Señales GEO y sistemas RAG: cómo optimizar tu citación en IA
Descubre cómo interactúan las señales GEO con sistemas RAG para mejorar visibilidad y citación en motores de IA. Claves, métricas y acciones para SEO técnico.

¿Has notado que algunas páginas se citan una y otra vez en respuestas de ChatGPT, Perplexity o en las Vistas creadas con IA de Google, mientras otras —igual de “buenas” a simple vista— jamás aparecen? La diferencia suele residir en dos capas que se tocan: las señales GEO (Generative Engine Optimization) y la forma en que un sistema RAG (Retrieval‑Augmented Generation) recupera, re‑ordena y ancla fuentes antes de generar la respuesta.
Este artículo define “señales GEO” (no confundir con geolocalización) y muestra cómo afectan cada etapa del pipeline RAG. Además, aporta métricas y un checklist para que tu contenido gane probabilidad de recuperación y citación en 2025.
1) Qué son las señales GEO y por qué elevan tu visibilidad en IA
“GEO” es la práctica de optimizar contenido para que sea elegido y citado por motores generativos. En la literatura de 2024–2025, se describen como un conjunto de señales editoriales y técnicas que incrementan la elegibilidad de una página para ser recuperada y mostrada como fuente. Dos panoramas útiles son Search Engine Land: qué es GEO (2025) y la explicación de Go Fish Digital sobre GEO (2025).
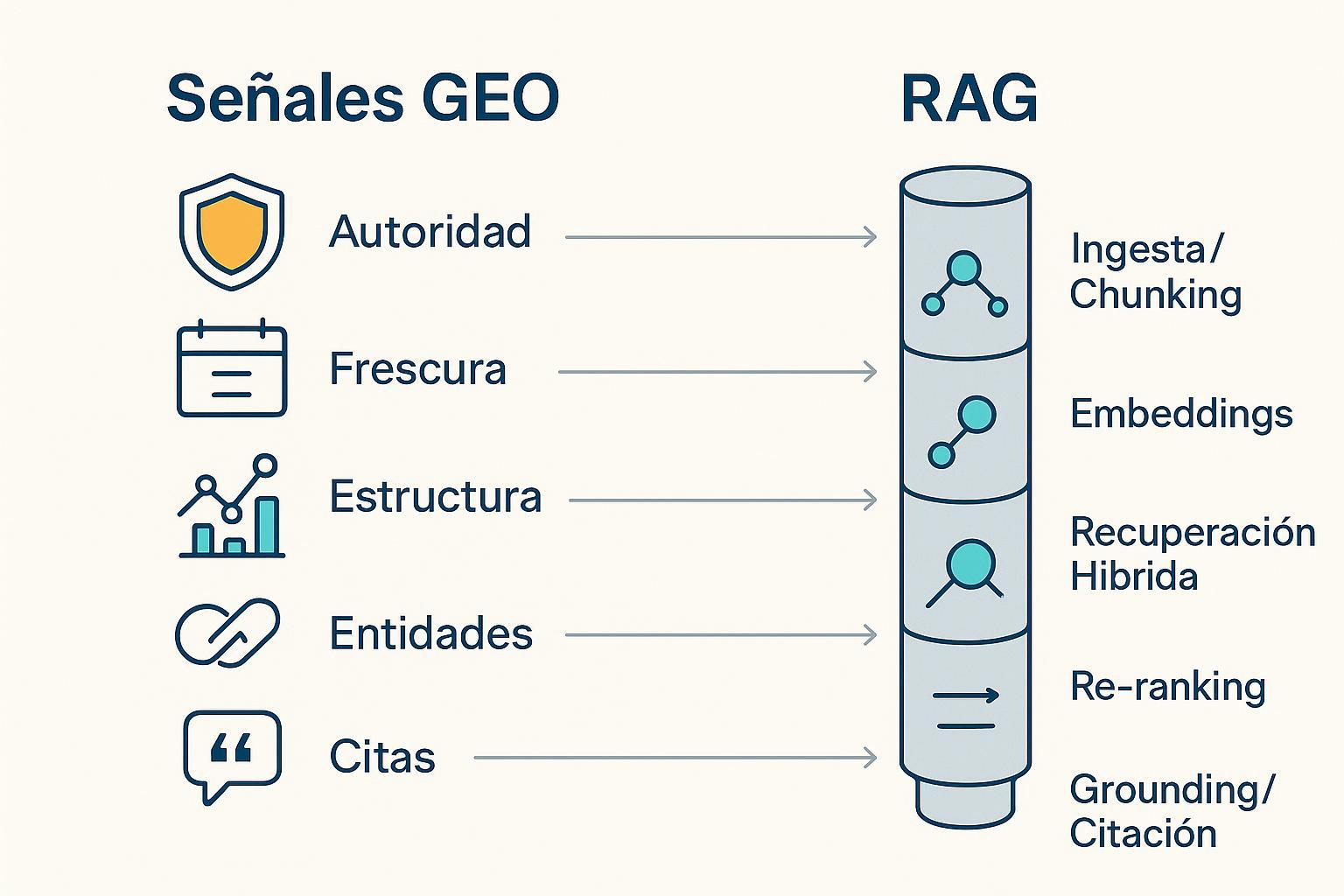
Señales GEO clave:
- Autoridad y E‑E‑A‑T: credenciales del autor, reputación del dominio, políticas editoriales y de correcciones.
- Frescura/recencia: fecha visible de publicación/actualización y contenido al día.
- Atribución y citas a fuentes primarias: referencias verificables, bibliografía y enlaces a documentos originales.
- Estructura legible por máquina: encabezados jerárquicos, listas, tablas y datos estructurados (Schema.org) adecuados al tipo de contenido.
- Claridad de entidades: nombres propios consistentes y desambiguados; relaciones nítidas entre conceptos.
- Evidencia cuantitativa: estadísticas, cifras y timestamps que faciliten la trazabilidad.
Si quieres un marco conceptual sobre exposición de marca en respuestas generativas, aquí tienes la definición de “AI Visibility” (Geneo).
2) Cómo decide un RAG qué recuperar y citar
Piensa en un sistema RAG como un bibliotecario ultra‑rápido que, antes de responder, busca notas relevantes, las ordena por calidad y actualidad, y sólo entonces redacta su explicación usando esas notas como base. Técnicamente, el pipeline sigue pasos bien conocidos:
- Ingesta y chunking: los documentos se segmentan en fragmentos semánticos (p. ej., 256–1024 tokens con solape) para conservar coherencia local. Ver la guía de técnicas RAG avanzadas de IBM (2025).
- Embeddings: se generan vectores densos que codifican significado de cada chunk.
- Recuperación híbrida: combinación de recuperación densa (ANN/similitud coseno) y dispersa (BM25/TF‑IDF), con fusiones como RRF para mejorar el recall. Introducciones y prácticas en Elastic Enterprise Search: RAG (2025) y el resumen en español de Datos.gob.es sobre técnicas RAG (2025).
- Re‑ranking: un modelo más costoso (p. ej., cross‑encoder) re‑ordena los candidatos top‑K para aumentar precisión antes de pasar al generador.
- Grounding y citación: el LLM recibe los fragmentos seleccionados como contexto y genera una respuesta que puede mostrar enlaces de apoyo.
En el caso de Google, la documentación oficial en español indica que las “Funciones de IA” (AI Overviews y modo IA) pueden mostrar enlaces a sitios como fuentes de apoyo, sin requerir marcado adicional específico más allá de ser elegible en Búsqueda estándar. Ver Google Developers: Funciones de IA y tu sitio web (2025).
3) Dónde se tocan GEO y RAG: mapa práctico
A continuación, un mapeo resumido de cómo cada señal GEO interactúa con etapas del pipeline RAG y qué efecto produce:
| Señal GEO | Etapas RAG más afectadas | Efecto observable |
|---|---|---|
| Estructura legible por máquina (H1–H3, listas, tablas) | Ingesta/Chunking; Recuperación densa | Chunks coherentes y temáticos; embeddings más informativos; mayor recall semántico |
| Datos estructurados (Schema.org: Article/FAQ/HowTo/Product) | Ingesta (metadatos); Re‑ranking | Metadatos útiles para filtros y señales explícitas que facilitan precisión del reranker |
| Autoridad y E‑E‑A‑T (dominio/autor) | Re‑ranking; Selección de citas | Desempata candidatos similares y aumenta probabilidad de mostrarse como fuente |
| Frescura (fechas visibles/actualizaciones) | Recuperación; Re‑ranking | Mejora elegibilidad cuando la intención exige actualidad; prioriza versiones recientes |
| Atribuciones y enlaces a fuentes primarias | Recuperación dispersa; Grounding | Refuerza matching léxico de entidades/URLs y facilita citación verificable |
| Claridad de entidades (nombres propios y relaciones) | Ingesta; Recuperación híbrida | Reduce ambigüedad, mejora emparejamiento exacto y semántico, disminuye riesgos de alucinación |
Este mapa se alinea con descripciones técnicas de RAG en Elastic (2025) y IBM (2025), y con prácticas GEO resumidas por Search Engine Land (2025).
4) Ejemplo comparado: página optimizada vs. página sin estructura
- Página optimizada: H1 claro, H2/H3 por subtema, tabla comparativa, secciones de resumen y FAQs, datos estructurados Article + FAQ, autor con credenciales y “última actualización” visible, enlaces a fuentes primarias. Resultado RAG: chunking limpio, embeddings ricos, mayor recall en recuperación densa, metadatos útiles para filtros/re‑ranking y fragmentos listos para citar.
- Página sin estructura: bloque largo sin encabezados, sin autor ni fecha, pocas referencias, sin schema. Resultado RAG: chunks ruidosos, embeddings menos informativos, peor recall y menos señales para re‑ranking; baja probabilidad de citación.
Moraleja: si el motor no puede “trocear” y entender, tampoco podrá recuperar ni justificar bien tu página. ¿Qué puedes hacer hoy para facilitarle ese trabajo? Pasemos a métricas y acciones.
5) Métricas para medir visibilidad y citación en IA
Define un panel mínimo para responder: “¿aparezco y con qué frecuencia me citan?”
- AI Citation Rate: porcentaje de respuestas generativas que incluyen un enlace a tu dominio dentro de un conjunto controlado de consultas.
- Response Inclusion Rate: porcentaje de respuestas en las que tu marca se menciona (con o sin enlace) para esas mismas consultas.
- Share of Voice (IA): distribución de presencia/citas por dominio frente a competidores en un tema o clúster de consultas.
- Cobertura por intención e idioma/país: aparición por tipo de búsqueda (informativa, comparativa, transaccional) y por mercado.
- Variación por plataforma: diferencias entre ChatGPT, Perplexity, AI Overviews, etc., y su evolución mensual.
Para metodologías y KPIs de evaluación, consulta estas lecturas ampliadas: métricas LLMO (Geneo) y cómo realizar una auditoría de visibilidad en IA (Geneo).
6) Checklist GEO‑friendly para facilitar RAG
- Editorial
- Añade bylines con credenciales verificables y políticas de corrección; refuerza E‑E‑A‑T.
- Mantén un registro de cambios con “última actualización” visible.
- Incluye citas a fuentes primarias y una breve sección de referencias.
- Técnico
- Estructura con H2/H3, listas y tablas; prepara resúmenes ejecutivos por sección.
- Aplica datos estructurados (Article/FAQ/HowTo/Product, según el caso) y metadatos de autor/fecha/idioma.
- Alinea entidades clave (marcas, productos, normas) con consistencia cross‑site; evita PDFs no parseables.
- Medición y ciclo de mejora
- Trackea AI Citation Rate, Response Inclusion Rate y SOV IA por tema/plataforma.
- Correlaciona cambios de contenido con variaciones de visibilidad/citación en ventanas semanales/mensuales.
7) Límites, riesgos y expectativas razonables (2025)
- Opacidad de señales: los pesos exactos que usan los motores generativos no son públicos; trabajamos con documentación de alto nivel y evidencia observacional. La página de Google Developers: Funciones de IA y tu sitio web (2025) ofrece las pautas más claras sobre elegibilidad y presentación de enlaces.
- Volatilidad de modelos: los pipelines cambian; monitoriza tendencias y evita promesas deterministas.
- Hallazgos por idioma/mercado: la citación puede variar por país y lengua; segmenta tus mediciones.
8) Micro‑ejemplo de flujo de trabajo para auditar citas
Divulgación: Geneo es nuestro producto.
- Objetivo: medir si tu contenido se recupera y cita con regularidad.
- Flujo sugerido (quincenal):
- Define un set de consultas por clúster temático e idioma.
- Lanza estas consultas en las plataformas de interés (ChatGPT con navegación, Perplexity, Google AI Overviews) y registra si aparece tu dominio y si hay enlace de citación.
- Calcula AI Citation Rate y Response Inclusion Rate por plataforma y clúster.
- Anota cambios editoriales/técnicos (nuevas tablas, schema, actualizaciones de fecha) y vincúlalos con la variación de métricas.
- Prioriza páginas con “alto recall sin citación” para mejorar estructura, metadatos o evidencias.
Herramientas como Geneo ayudan a centralizar este seguimiento de menciones y citas multi‑plataforma y a mantener el histórico para comparar periodos, sin convertir esta tarea en un trabajo manual infinito.
Cierre
Las señales GEO y los sistemas RAG se encuentran en cada paso: si tu página es fácil de trocear, rica en señales de entidad, actualizada y con trazabilidad, tendrá más papeletas para ser recuperada, re‑rankeada y citada. La receta no es mágica, pero sí repetible: estructura mejor, aporta evidencias, marca fechas y mide con constancia. Si gestionas presencia en motores generativos, convierte este proceso en un hábito y revisa tus métrricas cada mes. Así, cuando el “bibliotecario” vuelva a buscar, sabrá exactamente dónde coger el mejor fragmento.



