Cómo la IA verifica entidades web: definición y flujo
Descubre cómo la IA verifica entidades web, su pipeline técnico y su impacto en citación, marketing y branding. Explicación clara para empresas.

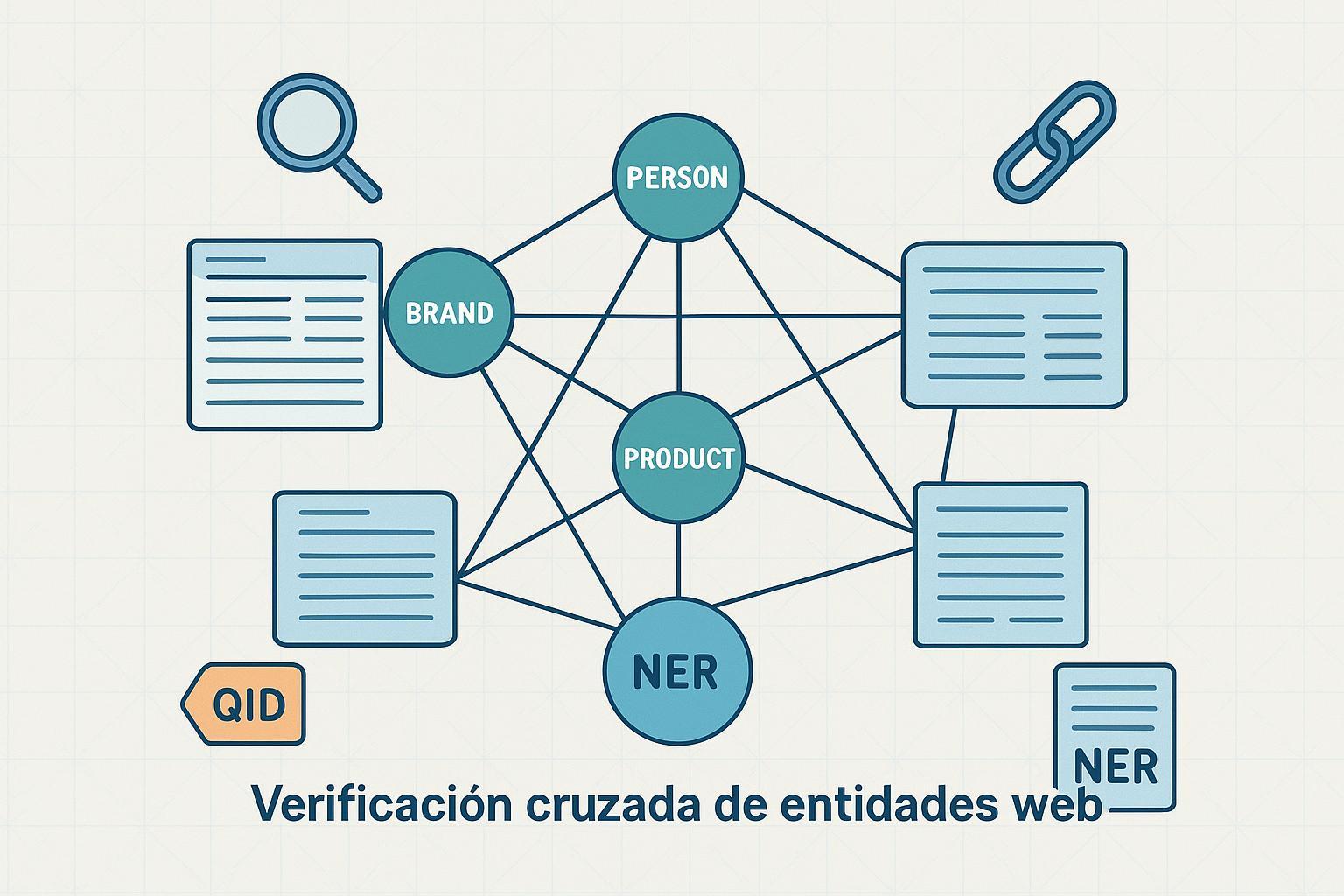
¿Tu marca aparece correctamente citada cuando un motor con IA responde una pregunta? Esa es la prueba de fuego de la verificación cruzada de entidades: la capacidad de un sistema para identificar quién eres, enlazarte al recurso correcto y respaldar los datos con fuentes confiables. En este artículo explicamos, con lenguaje claro y rigor técnico, cómo la IA contrasta entidades web y qué implica para marketing y branding.
Qué significa “verificación cruzada” de entidades web
Una entidad web es una unidad identificable (persona, organización, producto, obra) con atributos y relaciones, representada en páginas y en grafos de conocimiento. Operativamente, esa entidad suele estar anclada a un identificador único y a datos estructurados (por ejemplo, un QID en Wikidata, o marcado con schema.org).
La verificación cruzada por IA es el proceso de contrastar menciones y atributos de una entidad contra múltiples fuentes y contextos recuperados, validar la consistencia (grounding) y, cuando la plataforma lo permite, exponer citas visibles a las fuentes. Google describe sus Funciones de IA y tu sitio web como experiencias que ayudan a comprender temas complejos y muestran vínculos relevantes, aunque sin detallar su pipeline interno. Por su parte, Perplexity explica que cada respuesta incluye notas al pie con enlaces a las fuentes, un mecanismo útil para auditar la citación.
El pipeline: de la mención a la cita
1) NER y normalización de menciones
El Reconocimiento de Entidades Nombradas (NER) detecta spans en texto y los clasifica (persona, organización, lugar, etc.). Los modelos modernos (basados en transformers) han mejorado la precisión y el manejo de alias, lo que reduce confusiones. Piensa en NER como el filtro inicial que encuentra “Geneo” en una frase y lo etiqueta como ORG; luego, la normalización homogeniza variantes (Geneo App, geneo.app) para que el sistema no trate cada alias como un ente distinto.
2) Enlazado/resolución de entidades y QIDs
Identificar la mención no basta: hay que enlazarla a la entidad correcta. Aquí entra el entity linking/resolution, que decide si “Apple” se refiere a la empresa tecnológica o a la fruta. Los sistemas usan señales de contexto y modelos de ranking para asociar cada mención a un identificador único en una base de conocimiento. En Wikidata, ese identificador es un QID (p. ej., Q42); el glosario oficial define el QID como el código único de cada ítem, estable y reutilizable en URLs del tipo https://www.wikidata.org/wiki/Q42, según el Glosario de Wikidata (es). Si te ayuda, piensa en el QID como el DNI de la entidad.
3) Integración en grafos de conocimiento (Wikidata/Google KG)
Una vez enlazada, la entidad se valida y enriquece en un grafo de conocimiento: nodos (entidades) y aristas (relaciones) con propiedades y fuentes. En Wikidata, se consultan atributos y relaciones con SPARQL mediante el servicio WDQS; un buen punto de partida práctico es la lección de Programming Historian sobre Wikidata (es), que ejemplifica propiedades como wdt:P31 (instancia de) y wdt:P1082 (población), además del servicio de etiquetas en español. Esta etapa permite comprobar consistencia multifuente: si tu organización tiene fechas, sedes y productos coherentes entre sitios, la desambiguación es más fiable.
4) Recuperación Aumentada (RAG) y grounding
Para responder preguntas, muchos motores combinan recuperación y generación: RAG trae pasajes relevantes (búsqueda híbrida: BM25 + vectores) y el modelo genera basándose en esos contextos. La calidad del grounding se evalúa con métricas como fidelidad y relevancia del contexto; el marco RAGAS (arXiv, 2023) reporta correlaciones altas con juicios humanos para evaluar si la respuesta se apoya en las fuentes recuperadas. En escenarios de riesgo (información sensible o muy reciente), conviene incorporar revisión humana.
5) Citación y evaluación de fuentes
No todas las plataformas exponen citas igual. Perplexity añade notas al pie en cada respuesta; Google indica que sus experiencias de IA muestran enlaces relevantes, pero no publica el pipeline completo. Al evaluar fuentes, usa criterios simples pero estrictos:
- Autoridad y transparencia del editor
- Frescura (fecha y actualización)
- Cobertura y trazabilidad del dato
Para profundizar en datos estructurados, revisa la introducción oficial a datos estructurados de Google.
Tabla rápida: ¿Quién cita y cómo?
| Plataforma | ¿Cita visible en cada respuesta? | Fuente oficial/documentación |
|---|---|---|
| Perplexity | Sí, notas al pie numeradas con enlaces | Centro de Ayuda de Perplexity (es) |
| Google (Funciones de IA) | Muestra enlaces relevantes; no detalla pipeline de citación | Funciones de IA y tu sitio web (Google Developers) |
| ChatGPT | Depende del modo/experiencia; no hay documentación pública específica | — |
Riesgos y limitaciones habituales
- Ambigüedad de nombres: homónimos y alias mal gestionados.
- Datos desactualizados: errores por contenidos viejos o no verificados.
- Misgrounding: respuestas no respaldadas por contextos recuperados.
- Sesgos de fuentes: preferencia por ciertos dominios/idiomas.
Cuando el tema sea sensible (YMYL), incrementa el estándar de evidencia y añade revisiones humanas.
Qué pueden hacer las marcas hoy
-
Consolida tu “entity home”: página “Sobre” clara, perfiles oficiales y coherencia NAP; usa
schema.org/OrganizationoProducty la propiedadsameAspara enlazar perfiles externos. Guía base: introducción a datos estructurados de Google. -
Presencia en Wikidata: si eres elegible, crea/actualiza tu ítem con QID, propiedades y sitelinks. Tutorial práctico: lección de Programming Historian sobre Wikidata.
-
Contenido citable: publica datos verificables (metodologías, tablas, definiciones) con buena estructura para facilitar el parsing.
-
Audita tu visibilidad en motores con IA: mide menciones, precisión de atributos y sentimiento. Un marco de lectura útil sobre el enfoque general es Traditional SEO vs GEO (Geneo), que compara el SEO clásico con la monitorización de visibilidad en entornos de IA; y esta guía práctica: cómo realizar una auditoría de visibilidad en IA para tu marca.
-
Plan de resiliencia: la visibilidad puede fluctuar; considera estrategias de diversificación y seguimiento continuo. Para cambios en modelos, consulta Model Drift Monitoring (definición y aplicaciones, en español).
Flujo práctico de monitoreo de citaciones y visibilidad
Divulgación: Geneo es nuestro producto. En la práctica, las marcas necesitan observar cómo distintas plataformas identifican y citan su entidad. Un flujo útil incluye:
- Muestreo quincenal de consultas: preguntas de marca y de categoría (comparativas, atributos, reseñas) en motores con IA.
- Registro de respuestas y citas: ¿qué fuentes se enlazan?, ¿hay discrepancias de datos?, ¿qué tono predomina?
- Clasificación de precisión: atributos correctos vs incompletos; anota casos de ambigüedad.
- Acciones de corrección: enriquecer
schema.org, actualizar perfiles, reforzar Wikidata, publicar aclaraciones/casos de uso. - Seguimiento histórico: comparar periodos para detectar mejoras o degradaciones.
Las herramientas del mercado pueden ayudar a monitorizar visibilidad multi-plataforma, seguimiento de menciones/citaciones y análisis de sentimiento en respuestas; el objetivo no es promocionar, sino ilustrar que estos flujos son operativos y medibles.
Cierre
La verificación cruzada de entidades combina NER, enlazado a identificadores únicos, grafos de conocimiento y RAG con grounding, culminando en citas que idealmente son transparentes. Si tu entidad está bien definida y consistente, reduces la ambigüedad y aumentas la probabilidad de respuestas precisas y citables. ¿Qué paso vas a priorizar en el próximo trimestre: reforzar tus datos estructurados, tu QID en Wikidata o tu proceso de auditoría de visibilidad?



