Cómo la IA prioriza contenido sin índice web tradicional
Descubre cómo los modelos de IA y LLMs rankean y citan contenido sin índice web clásico. Explicación práctica con tácticas y señales clave.

¿De verdad “no hay índice”, pero aun así algunos contenidos aparecen primero y otros no? Esa es la sensación cuando trabajas con asistentes y LLMs: no vemos un índice web clásico, pero sí hay un proceso que decide qué pasajes se recuperan y citan. En esta guía te muestro, con base técnica y enfoque práctico, cómo funciona ese ranking sin índice visible y qué puedes hacer para que tus páginas sean elegibles, recuperadas y citadas.
De “índice” a recuperación semántica: qué ha cambiado
En los motores tradicionales, el índice léxico y el ranking por coincidencia de términos (BM25) dominaban el juego. En experiencias generativas, la clave es la recuperación semántica: representar consultas y fragmentos de texto como embeddings (vectores densos) en un espacio de alta dimensión, y comparar su similitud para traer los pasajes más cercanos aunque no compartan las mismas palabras.
Para que eso sea eficiente, los documentos extensos se dividen en chunks y se almacenan en almacenes vectoriales consultados con algoritmos de vecinos aproximados (ANN) como HNSW o IVF. Librerías como FAISS (Meta) son referencias para implementar búsqueda por similitud a gran escala; y guías como Elastic sobre recuperación de información y búsqueda semántica explican cómo se combinan señales léxicas y semánticas en la práctica.
Piensa en un almacén vectorial como una biblioteca sin estanterías ordenadas por palabras, sino por “significado”. Cuando preguntas algo, el sistema busca zonas del mapa donde viven los pasajes con sentido parecido y te trae los fragmentos más próximos.
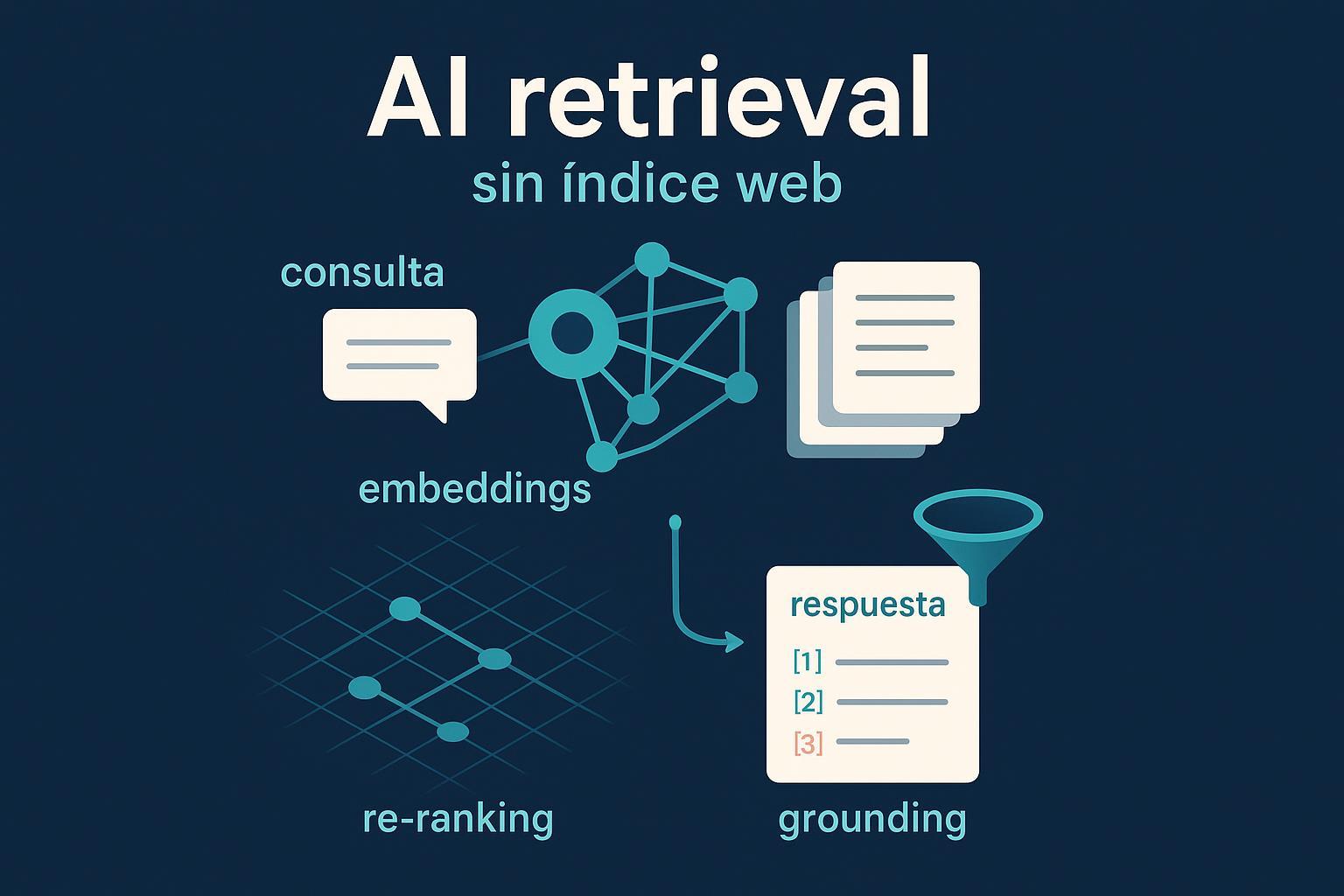
El pipeline que decide qué se cita
Aunque no veas un índice clásico, sí existe un pipeline que ordena qué contexto entra en la respuesta generada. En términos generales: la consulta del usuario puede reformularse o descomponerse en subconsultas para cubrir mejor la intención; después se aplica recuperación híbrida (densa por embeddings y dispersa por términos) para maximizar cobertura; un re‑ranking profundo reordena el top‑N de pasajes con más precisión; el LLM hace grounding limitándose al contexto recuperado y, cuando la plataforma lo permite, expone citas/URLs antes de sintetizar la respuesta final.
A nivel de implementación y buenas prácticas, Azure AI Search documenta RAG en español y su guía de diseño y evaluación explica chunking, selección de embeddings y recuperación híbrida con ranking semántico.
| Etapa | Input clave | Técnica dominante | Por qué importa para marketing |
|---|---|---|---|
| Consulta/expansión | Pregunta del usuario | Reformulación, subconsultas | Aumenta cobertura de temas y sinónimos |
| Recuperación híbrida | Consulta y colección | Vectorial + BM25 | Mejora recall sin perder precisión |
| Re‑ranking | Top‑N pasajes | Cross‑encoders/ColBERT | Prioriza el fragmento más citable |
| Grounding/atribución | Pasajes seleccionados | Limitación al contexto + citas | Reduce alucinación y da crédito |
| Síntesis | Contexto final | LLM | Une la respuesta con tono y claridad |
Para el re‑ranking, modelos tipo cross‑encoder (p. ej., monoT5) ofrecen alta precisión con más coste, mientras enfoques como ColBERT equilibran latencia y calidad. Microsoft explica el ranking semántico; y estudios como AutoRAG (arXiv, 2024) analizan los trade‑offs entre efectividad y costes en pipelines reales.
Las señales que más pesan hoy
- Relevancia semántica: la recuperación híbrida más el re‑ranking eleva la probabilidad de que tus pasajes entren en el contexto.
- Frescura/recencia: muchos sistemas permiten boosts o filtros por fecha; en ecosistemas tipo Elasticsearch se emplean funciones de decaimiento para priorizar contenido reciente, como documenta Elastic en function_score y decay.
- Consenso y corroboración: los sintetizadores tienden a preferir hechos consistentes en varias fuentes; Copilot, por ejemplo, explica cuándo y cómo expone citas en sus respuestas en su FAQ oficial.
- Autoridad/E‑E‑A‑T: en temas sensibles (YMYL), la guía de contenidos útiles de Google recomienda demostrar experiencia, autoridad y fiabilidad.
- Calidad estructural y citabilidad: encabezados informativos, TL;DR, FAQs, tablas y cifras con enlaces a fuentes primarias ayudan a que tu contenido sea “chunkable” y fácil de citar.
- Anti‑spam y claridad técnica: HTML limpio, carga rápida y versiones textuales de PDFs/infografías reducen fricciones y errores de extracción.
Tácticas accionables para ser recuperado y citado
- Diseña contenido “chunkable”: H2/H3 que describen exactamente lo que viene, párrafos breves y bullets donde aporte.
- Incluye un TL;DR ejecutivo al inicio y una sección de FAQs con preguntas específicas.
- Añade datos verificables con enlaces a fuentes primarias y URLs estables.
- Usa marcado estructurado (schema.org donde aplique), sitemaps actualizados y canonicalización.
- Mantén una cadencia de actualización visible (política de frescura) y registra cambios.
- Refuerza señales editoriales: autoría clara, revisión experta en YMYL, transparencia de metodología y límites.
- Cuida accesibilidad técnica: HTML claro, mobile‑first, evitar muros duros que bloqueen la extracción de pasajes.
Métricas y monitorización para cerrar el loop
Para saber si tus tácticas funcionan, necesitas medir el comportamiento del sistema.
- KPIs de recuperación: Recall@K y nDCG@K para auditar cobertura y orden del recuperador (benchmark de referencia BEIR).
- KPIs de citación: tasa de respuestas que enlazan a tus páginas y estabilidad de citas por consulta.
- Visibilidad de marca: Share of Voice en asistentes y sentimiento asociado en respuestas generativas.
- Flujo operativo: registra consultas objetivo; muestrea respuestas; guarda evidencias (capturas, URLs, timestamps); analiza los pasajes citados y detecta brechas temáticas para iterar.
Ejemplo práctico de cierre del ciclo
Divulgación: Geneo es nuestro producto.
Tras publicar una guía con TL;DR y FAQs, el equipo utiliza una plataforma de monitorización de visibilidad en asistentes de IA para:
- Detectar si las respuestas generativas citan las URLs de la guía y qué pasajes se reutilizan.
- Observar la frecuencia y estabilidad de menciones por consulta en el tiempo.
- Analizar el sentimiento asociado a la marca en esas respuestas.
- Identificar huecos donde no hay citación para priorizar nuevas piezas.
Este circuito cierra el loop entre táctica editorial y señales observables, y te permite iterar sin hacer promesas de rendimiento.
Límites y diferencias por plataforma
No todos los asistentes funcionan igual. Algunos conectan a crawls propios, otros a bases documentales curadas o a conectores externos. Los pesos exactos de las señales y la forma de citar rara vez están totalmente documentados. Por eso conviene trabajar sobre principios universales de IR/RAG (recuperación híbrida, re‑ranking, grounding con citas) y validar en tu vertical con experimentos reproducibles.
Para profundizar en el enfoque RAG y variantes modernas, revisa la vista general de RAG con Azure AI Search (en español), la librería FAISS para índices ANN, y las pautas de OpenAI sobre grounding en sus blueprints de Knowledge Retrieval.
Cierre
Si el índice clásico era una estantería por palabras, el ranking en asistentes se parece más a un mapa por significados. Para aparecer y ser citado, optimiza para recuperación semántica: estructura chunkable con TL;DR y FAQs, datos verificables con enlaces, marcado y sitemaps, políticas de frescura y señales editoriales sólidas. Mide recall y nDCG, vigila la tasa y estabilidad de citaciones y el sentimiento, y ajusta tu contenido según lo que veas. ¿La clave? Iterar con evidencia y construir autoridad donde importa.



