Cómo los modelos de IA leen e interpretan tu contenido
Descubre cómo los modelos de IA procesan y citan tu contenido. Optimiza estructura, metadatos y robots.txt para ser más visible en respuestas de inteligencia artificial.

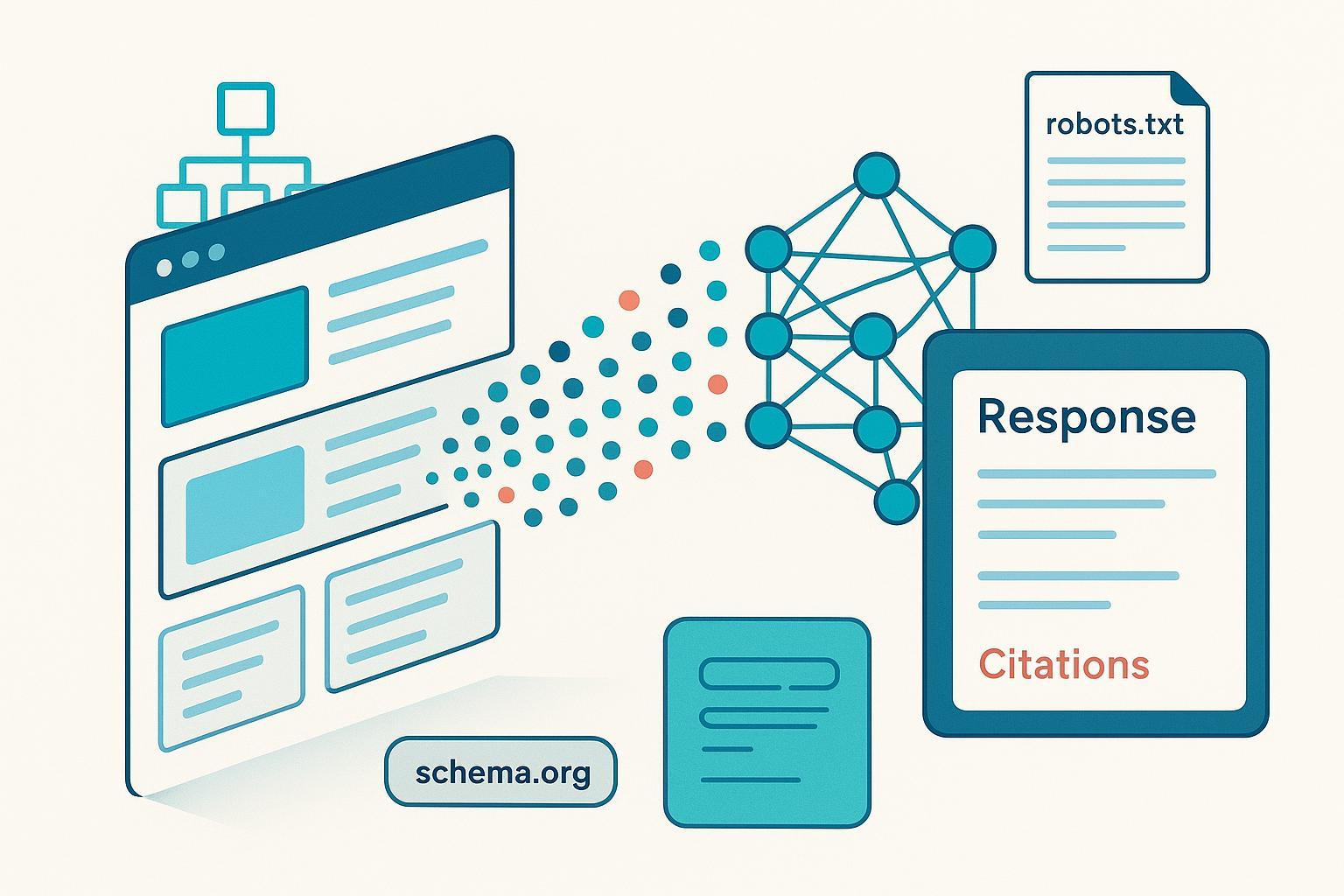
¿Por qué algunas páginas aparecen citadas en respuestas con IA y otras, aun siendo buenas, no? La clave es que los modelos no “ven” una web como lo hace una persona: extraen significado. Si los ayudas a entender tus ideas con estructura, señales claras y gobernanza técnica, aumentas la probabilidad de ser recuperado y citado.
1) De texto a significado: tokens, embeddings y RAG en dos minutos
Piensa en tu página como un mapa de conceptos. Para un modelo, ese mapa se convierte primero en tokens (pequeñas unidades de texto) y luego en embeddings, que son vectores que capturan el “significado” de cada fragmento. Con esos vectores, los sistemas comparan consultas y documentos por similitud y recuperan los pasajes más relevantes.
En muchas plataformas, la recuperación es híbrida: combinan coincidencia por palabras clave con búsqueda semántica, y entregan los fragmentos a un generador para redactar la respuesta (patrón RAG). Elegir el embedding adecuado y cómo troceas tu contenido importa. Google explica los tipos de tarea y usos de embeddings en la API de Gemini en la guía oficial Embeddings (Google AI for Developers, 2025), útil para entender cómo se optimiza la recuperación semántica en distintos contextos: tipos y usos de embeddings en la API de Gemini.
Cómo aterrizarlo en tu página:
- Fragmenta en secciones autocontenidas con encabezados descriptivos.
- Mantén contexto local en cada bloque (término, entidad, autor, fecha si aplica).
- Evita párrafos kilométricos: mejor piezas precisas y citables.
2) Cómo “ven” tu sitio: rastreo, renderizado y límites prácticos
Para llegar a esos fragmentos, antes hay que poder rastrear y renderizar. Googlebot descarga tu HTML y, cuando lo necesita, usa un servicio de renderizado para ejecutar JavaScript. Hay límites relevantes: Google documenta que solo considera los primeros 15 MB de cada recurso HTML para indexación; lo que quede después puede ignorarse. Ver “Qué es el robot de Google” (Google Search Central, 2025): límite de 15 MB y consideraciones de rastreo.
Recomendaciones prácticas:
- Prioriza que el contenido principal esté en HTML inicial o se renderice de forma fiable.
- No bloquees CSS/JS esenciales en robots.txt; ayudan a entender el layout y el contenido.
- Comprueba canónicos y que la versión renderizada expone el texto que quieres que se recupere.
3) Metadatos que sí ayudan: datos estructurados y señales de calidad
Los datos estructurados en JSON‑LD aportan un “resumen explícito” de tu página: tipo de contenido, autoría, organización, FAQs, pasos de un HowTo… Esto facilita la comprensión automática y, de paso, la elegibilidad para resultados enriquecidos. La referencia canónica es la guía “Introducción a datos estructurados” (Google Search Central, 2025): cómo describir tu contenido con Schema.org.
Ejemplo base (JSON‑LD) para un artículo informativo:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Título del artículo",
"author": {"@type": "Person", "name": "Nombre del autor"},
"publisher": {"@type": "Organization", "name": "Nombre de la organización"}
}
</script>
Buenas prácticas de calidad que favorecen la citación:
- Atribuye datos y definiciones con enlaces a fuentes primarias.
- Incluye páginas “Acerca de”, biografías de autor y, si procede, revisiones editoriales.
- Mantén consistencia de nombres de entidades, unidades y versiones.
4) Gobierno y control: robots.txt, meta robots, Google‑Extended y GPTBot
Controlar el rastreo no es lo mismo que controlar la indexación. robots.txt indica a cada agente qué rutas puede o no explorar; para impedir indexación usa meta robots noindex (o X‑Robots‑Tag en cabeceras HTTP). La sintaxis y la interpretación admitida están documentadas por Google (Google Search Central, 2025): directrices y ejemplos de robots.txt.
Además de Googlebot, hoy conviene gestionar rastreadores ligados a modelos de IA. Por ejemplo, OpenAI publica información del user‑agent “GPTBot” y cómo excluirlo (OpenAI, 2025): política oficial de GPTBot. También puedes distinguir entre agentes de entrenamiento y de navegación (cuando existan), y aplicar reglas separadas.
Ejemplo ilustrativo de robots.txt (recuerda: el cumplimiento es voluntario y algunos agentes podrían ignorarlo o falsificar su identidad):
# Permite rastreo a Googlebot para SEO
User-agent: Googlebot
Allow: /
# Expresa preferencia de exclusión para usos de IA específicos
User-agent: Google-Extended
Disallow: /
# Bloquea GPTBot (OpenAI) para entrenamiento
User-agent: GPTBot
Disallow: /
# Regla general para otros agentes
User-agent: *
Allow: /
Refuerza estas políticas con controles de red cuando el proveedor publique rangos de IP o métodos de verificación. Y al decidir bloqueos, separa “entrenamiento” de “navegación”: tu estrategia de marca puede querer permitir que te citen en experiencias de respuesta, pero no ceder datos para entrenamiento.
5) Diseña para ser citado: checklist editorial y técnico
- Escribe títulos y subtítulos descriptivos (incluye la entidad y el concepto principal).
- Divide en secciones breves y autocontenidas, con definiciones y cifras claras.
- Usa tablas o listas solo cuando aporten claridad; evita bloques de texto interminables.
- Marca con Schema.org lo que ya está en la página (Article/FAQPage/HowTo/Organization/Person).
- Enlaza a fuentes primarias y explica el contexto (qué, quién, cuándo).
- Asegura indexabilidad: sitemaps al día, canónicos correctos, rendimiento sólido.
6) Ejemplo práctico: comprobar si te citan y qué dicen
Disclosure: Geneo es nuestro producto. Un flujo sencillo para validar visibilidad y consistencia en motores de respuesta y asistentes con navegación podría ser:
- Elige el conjunto de URLs prioritarias (guías, estudios, landing de producto).
- Revisa periódicamente respuestas generadas por IA para consultas objetivo y localiza menciones/citas.
- Registra el sentimiento y la exactitud de los datos citados.
- Cruza con Search Console y analítica (impresiones, clics, referencias) para ver correlaciones.
- Itera mejoras editoriales/técnicas: claridad de definiciones, secciones más citables, metadatos, datos estructurados.
Una herramienta de monitorización de visibilidad en plataformas de IA, como Geneo, puede ayudar a centralizar menciones, enlaces y sentimiento para cerrar el ciclo “optimizo → observo → corrijo”. No garantiza aparición; sí aporta observabilidad para tomar decisiones.
7) FAQs rápidas
¿Bloquear Google‑Extended afecta al SEO?
No debería afectar al rastreo e indexación de Googlebot para resultados de búsqueda tradicionales si no bloqueas a Googlebot. Google‑Extended se usa para funciones de IA; su cumplimiento es voluntario y la política puede evolucionar. Define tu postura por tipo de agente y revisa periódicamente.
¿Puedo medir AI Overviews en Search Console?
A día de hoy, la documentación pública no desglosa de forma explícita métricas independientes para cada experiencia de IA. Las definiciones oficiales de impresiones y clics están en la ayuda de Search Console (Google, 2025): cómo interpreta Search Console las métricas de rendimiento. Vigila las actualizaciones del blog de Search Central.
Cierre
Si tu contenido se presenta como un mapa semántico claro—fragmentos bien definidos, señales de calidad y metadatos coherentes—los modelos lo entienden mejor. Suma una gobernanza explícita (robots.txt, meta robots y controles de red cuando proceda) y un flujo de medición continua sobre citaciones y sentimiento. El resultado no son atajos mágicos, sino una base sólida para ser recuperado con mayor precisión cuando importe. ¿El siguiente paso? Define un circuito mensual de auditoría: comprueba rastreo y renderizado, valida Schema, revisa citas y ajusta tu contenido para que sea aún más claro y verificable.



