Cómo construir un grafo de conocimiento de marca: guía práctica paso a paso
Descubre cómo construir un grafo de conocimiento de marca, paso a paso, para mejorar visibilidad y coherencia de tus datos de marca.

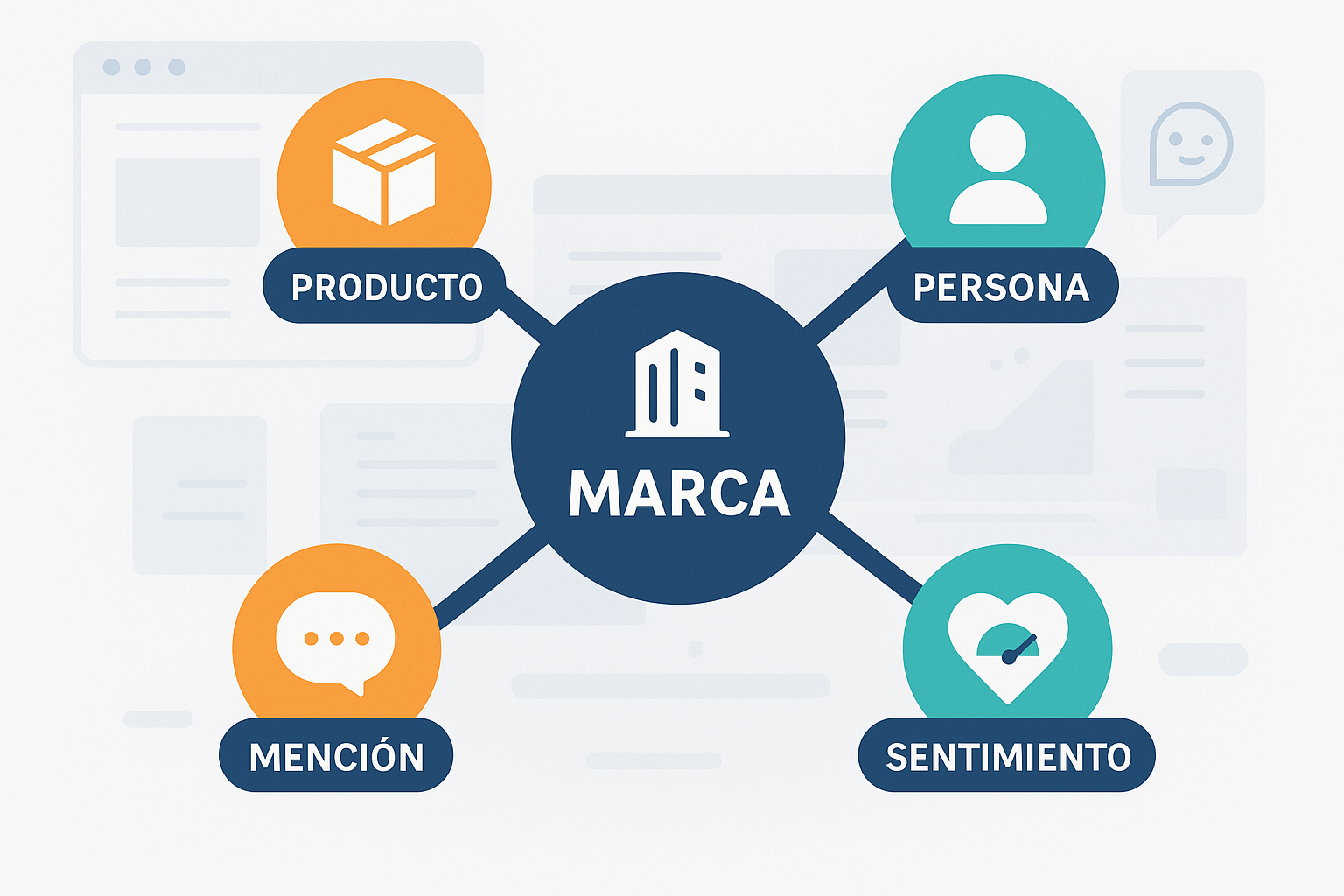
¿Has visto cómo tu web dice una cosa, el ecommerce otra y un asistente de IA responde con datos antiguos? Ese desajuste erosiona confianza y rendimiento. Un grafo de conocimiento de marca corrige la raíz: modela, en un mismo sistema, las entidades clave de tu ecosistema (Organización, Producto, Persona, Contenido, Canal, Evento, Consulta, Mención, Sentimiento) y sus relaciones. En la práctica, te ayuda a mantener una “verdad” coherente, impulsar SEO semántico y alimentar aplicaciones de IA con datos fiables.
Antes de empezar: fija objetivos y casos de uso
Elegirás mejor si acotas el alcance. Recomiendo priorizar tres frentes:
- Visibilidad SEO/IA: alinear tus datos con la web semántica y mejorar la presencia en resultados enriquecidos y paneles de conocimiento.
- Coherencia de entidades: una única ficha por producto/persona/servicio en todos los canales.
- Reputación y señales externas: integrar menciones, citaciones y sentimiento para detectar riesgos y oportunidades.
Como contexto para autoridad y visibilidad, vale la pena considerar el papel de fuentes públicas como Wikipedia. Consulta este análisis sobre cómo influyen en IA y búsqueda en el recurso de Geneo: Wikipedia y autoridad: clave para visibilidad de marca en IA.
Paso 1 — Diseña una ontología mínima pero escalable
Empieza por el vocabulario que define “qué existe” y “cómo se relaciona”. Tu ontología de marca debería cubrir:
- Entidades: Organization/Brand, Product, Person (portavoces), WebPage/Article, Channel, Event, Query (consulta), Mention (mención), Sentiment (sentimiento).
- Relaciones típicas: Brand—owns→Product; Product—appears_on→WebPage; Brand—mentioned_in→AI_Answer; Query—relates_to→Intent; Mention—has_sentiment→Score.
Reutiliza estándares para interoperabilidad: schema.org para Organización, Producto, FAQ/Article; FOAF para personas; SKOS para taxonomías y etiquetas temáticas. Los repositorios y guías en español sobre ontologías son un buen punto de partida, por ejemplo la colección de Recursos de datos.gob.es sobre “ontologías” y los artículos divulgativos de Universo Abierto sobre ontologías.
Buenas prácticas:
- Modulariza (núcleo + extensiones por canal/caso de uso) y versiona la ontología.
- Documenta dominios, rangos y cardinalidades; incluye ejemplos y preguntas de competencia (“¿Qué productos de la marca X fueron citados el último mes?”).
- Define propiedades obligatorias por tipo de entidad para facilitar la validación automática.
Paso 2 — Reúne fuentes y prepara la ingesta (ETL/ELT)
Mapea fuentes internas y externas y decide la cadencia de actualización. Internas: CRM/ERP, PIM/ecommerce, CMS, analítica. Externas: sitio público, redes sociales, Wikipedia/medios y, cada vez más, respuestas/citaciones de asistentes de IA.
Para estas últimas, modela cada aparición como una entidad “Mención” u “Observación” con:
- Texto/resumen de la mención, plataforma (p. ej., SGE, ChatGPT, Perplexity), URL citada si existe.
- Timestamp de captura y autor/fuente.
- Sentimiento y tema estimados.
Asegura trazabilidad de origen y calidad: normaliza formatos, registra el “source of truth” y mantiene histórico para comparar tendencias.
Paso 3 — Resuelve y desambigua entidades
El mismo producto puede aparecer como “X Pro”, “X-Pro” o “XPro”. La resolución de entidades une duplicados y separa homónimos.
En la práctica combinamos:
- Normalización: minúsculas, acentos, alias, limpieza de caracteres; IDs oficiales (SKU, VAT, LEI) cuando apliquen.
- Blocking: agrupa candidatos por claves (prefijos, país, categoría) para reducir comparaciones.
- Reglas de matching: umbrales de similitud (Jaro-Winkler/Levenshtein), coincidencias exactas en campos críticos (legalName, tax ID), reglas compuestas.
- Modelos ML: clasificadores de duplicado/no duplicado y embeddings para nombres de marca/producto.
Mide la calidad con precisión, recall y F1; controla la tasa de duplicados remanentes y la consistencia de IDs. Establece un umbral de aceptación y un flujo de revisión manual asistido por sugerencias del modelo.
Paso 4 — Elige tu modelo de grafo: RDF/Linked Data vs Property Graph
No existe una única respuesta. Piensa en interoperabilidad, tipo de consulta y operaciones.
| Criterio | RDF/Linked Data (RDF, OWL, SPARQL) | Property Graph (Cypher/Gremlin/GQL) |
|---|---|---|
| Interoperabilidad semántica | Muy alta; URIs y vocabularios estándar | Media; esquema flexible pero menos estandarizado |
| Consultas | SPARQL potente en patrones semánticos | Patrones de rutas y análisis operativo |
| Modelado | Tripletas; ontologías y razonamiento | Nodos/aristas con etiquetas y propiedades |
| Casos típicos | Datos enlazados, publicación abierta, alineación con vocabularios | Recomendaciones, recorridos operativos, analítica ágil |
| Herramientas | GraphDB, Stardog, Jena/Fuseki | Neo4j, Cosmos DB (Gremlin), Neptune |
Para una introducción al lenguaje de consulta de grafos emergente, revisa la guía de GQL en Microsoft Fabric y la visión general de base de datos de grafos en Microsoft Fabric. Si tu caso se cruza con RAG y LLMs, esta comparación práctica de Paradigma ayuda a decidir entre vectores y grafos: “Vectores vs grafos para aplicaciones RAG” de Paradigma Digital.
Paso 5 — Publica y conecta con la web semántica (JSON-LD)
Tu sitio debe “hablar” el mismo idioma que tu grafo. Publica datos estructurados con JSON-LD, alineados con tu ontología.
Ejemplo básico de Organization y Product:
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Ejemplo S.A.",
"url": "https://www.ejemplo.com",
"logo": "https://www.ejemplo.com/logo.png",
"sameAs": [
"https://es.wikipedia.org/wiki/Ejemplo",
"https://www.linkedin.com/company/ejemplo"
],
"brand": {
"@type": "Brand",
"name": "Ejemplo"
}
}
{
"@context": "https://schema.org",
"@type": "Product",
"name": "Ejemplo X Pro",
"image": ["https://www.ejemplo.com/x-pro.jpg"],
"description": "Dispositivo X para profesionales.",
"sku": "XPRO-123",
"brand": {"@type": "Brand", "name": "Ejemplo"},
"offers": {
"@type": "Offer",
"priceCurrency": "EUR",
"price": "499.00",
"availability": "https://schema.org/InStock",
"url": "https://www.ejemplo.com/tienda/x-pro"
}
}
Valida con las guías oficiales de Google y su tester. Consulta la documentación de datos estructurados de Organization (Google Developers, es) y la introducción a datos estructurados.
Paso 6 — Publicación y acceso: APIs, SPARQL o GQL
Expón tu grafo de forma segura y útil:
- RDF: endpoint SPARQL (paginado, límites de tiempo) y exportaciones JSON-LD/Turtle.
- Property graph: APIs o acceso por drivers con Cypher/Gremlin/GQL.
- Seguridad: HTTPS, OAuth2/OpenID Connect o JWT, control de acceso por roles/atributos, auditoría y límites de tasa.
- Documentación: describe ontología, endpoints y ejemplos; usa OpenAPI/Swagger para REST.
Paso 7 — Evalúa, valida y mejora continuamente
Define métricas técnicas y de negocio:
- Calidad del grafo: cobertura de entidades, completitud de propiedades obligatorias, frescura de datos, coherencia semántica.
- Rendimiento: latencia media de consulta, throughput, estabilidad.
- Utilidad: mejoras en rich results y paneles de conocimiento, frecuencia de citaciones en respuestas de IA, evolución del sentimiento promedio.
Para validar restricciones en RDF, apóyate en W3C SHACL. Diseña “preguntas de competencia” para pruebas funcionales, por ejemplo: “¿Qué productos de la marca X han sido citados por asistentes de IA en los últimos 30 días?”.
Gobierno del dato y privacidad (RGPD)
Tu grafo debe cumplir por diseño:
- Base legal del tratamiento y minimización de datos personales.
- DPIA/EIPD cuando el riesgo sea alto; designación de DPO si corresponde.
- Derechos de las personas (acceso, rectificación, supresión, oposición, portabilidad, limitación) y procesos para atenderlos.
- Medidas técnicas y organizativas: pseudonimización, cifrado, control de acceso, registro de eventos y políticas de retención/borrado.
- Si operas en el sector público español, considera el Esquema Nacional de Seguridad (ENS).
Troubleshooting: problemas frecuentes y cómo resolverlos
- Ambigüedad de entidades: añade contexto (sameAs, alias, IDs oficiales) y refuerza reglas de matching. Revisión asistida por ML para casos límite.
- Duplicados persistentes: eleva umbrales y añade validaciones en ingesta; establece revisiones por muestreo semanal hasta estabilizar la tasa de duplicados.
- Inconsistencias entre fuentes: define jerarquías de confianza (source of truth) y registra versiones con timestamp y autor.
- Latencia alta en consultas: crea índices, cachea patrones recurrentes, limita profundidad de recorridos y precomputa agregados.
- Errores de esquema al evolucionar la ontología: versiona cambios, ejecuta migraciones y valida con SHACL o tests de preguntas de competencia.
- Desalineación con la web: automatiza la publicación de JSON-LD desde el grafo y valida periódicamente con herramientas de Google.
Recursos y herramientas
- GQL y bases de datos de grafos: guía oficial en español en Microsoft Fabric (2024–2025) y la visión de graph database.
- RDF y validación: estándar de W3C SHACL.
- Comparativas para RAG y grafos: artículo de Paradigma Digital sobre vectores vs grafos.
- Marcado estructurado: guías de Google Developers en español.
Disclosure: Geneo es nuestro producto. Puede ayudar a monitorizar menciones y citaciones de marca en asistentes de IA y buscadores, integrándolas como observaciones en tu grafo para analizar visibilidad y sentimiento.
Checklist de 30 días para poner tu grafo en marcha
- Objetivos y alcance definidos; ontología mínima diseñada y documentada.
- Fuentes internas y externas mapeadas; pipeline de ingesta incremental en marcha.
- Reglas de normalización y matching aprobadas; muestra etiquetada para evaluación.
- Elección de modelo (RDF o property graph) tomada y prototipo funcional listo.
- Marcado JSON-LD publicado en homepage y plantillas clave; validaciones OK.
- Endpoint/API expuesto con seguridad básica; logs y auditoría habilitados.
- Métricas y tablero de calidad/uso operativos; plan de mejora continua.
¿Listo para alinear tu marca con la web semántica y las IA? Construye el primer prototipo, mide y itera: tu grafo se volverá el activo de datos más “vivo” de tu marketing técnico.



