
Best Practices for Tracking Brand Tone Alignment Across Multiple AI Engines
Learn how professionals track brand language consistency across ChatGPT, Perplexity, and Google AI Overviews with measurable metrics and workflows.
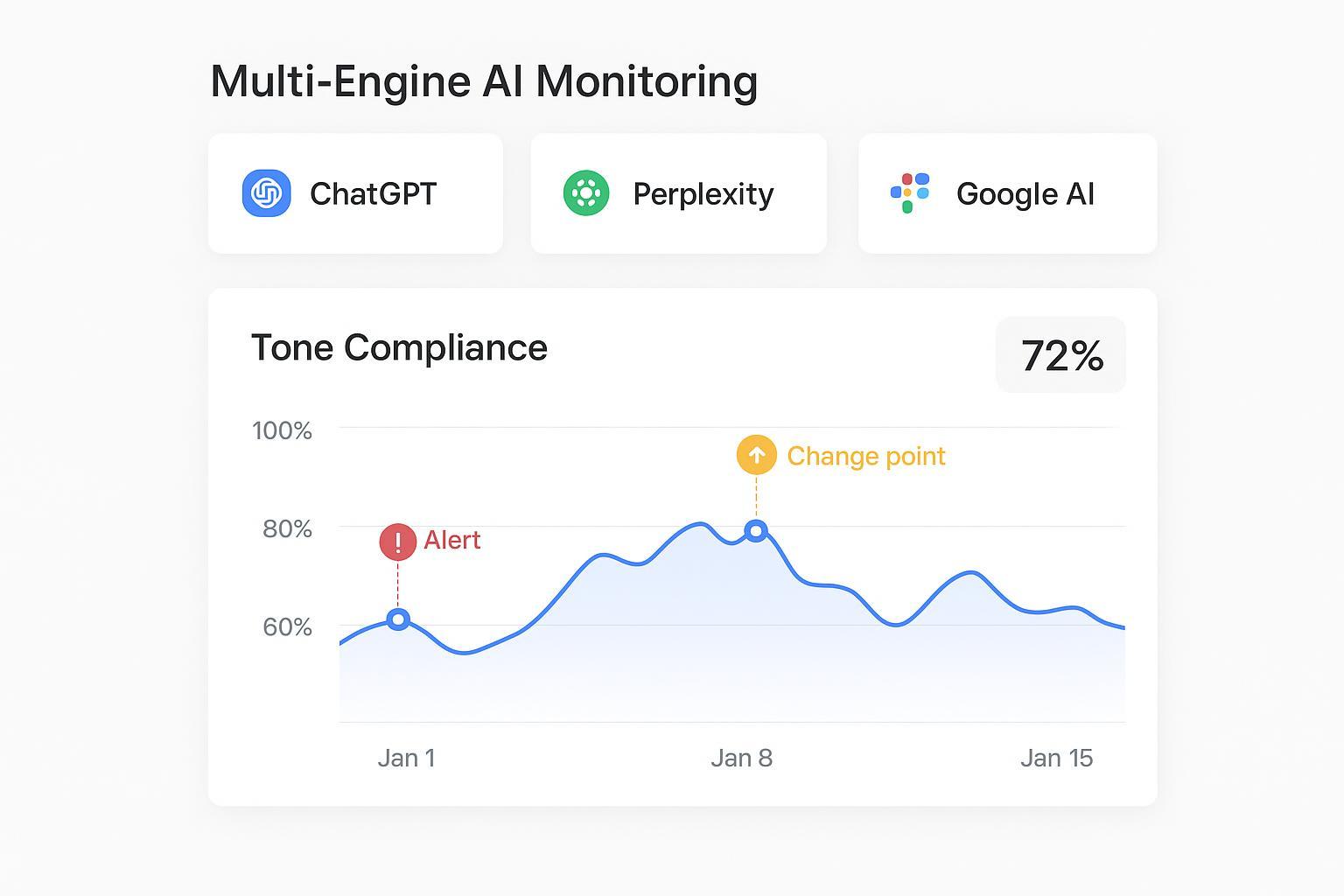
When AI answers define your brand before a click ever happens, tone alignment is no longer a style guide footnote—it’s a reliability requirement. If ChatGPT uses casual phrasing while Google AI Overviews leans overly formal, or Perplexity mixes outdated product names with hedged language, customers encounter a fragmented identity. That inconsistency hurts trust, depresses citations, and muddles your narrative. So how do you measure and control tone across engines, week after week?
The measurement problem: make tone observable, comparable, and repeatable
A practical model starts with a clear taxonomy and a disciplined logging routine. Think of it like instrumenting an API: you need stable inputs (prompts), known outputs (answer snapshots and citations), and agreed rules (tone and lexicon guardrails) so comparisons are meaningful over time.
Taxonomy and signals
Tone/register: formal vs informal; concise vs verbose; assertive vs hedged; use of domain jargon.
Lexical guardrails: preferred phrases, forbidden terms, canonical product names, and consistent entity references.
Sentiment/polarity: positive, neutral, or negative toward your brand, plus confidence.
Consistency over time: stability of the above features across sessions, prompts, and engines.
Core KPIs (tracked longitudinally)
Tone compliance rate: the percent of answers that match declared brand tone and rules. Geneo’s LLMO guidance recommends calibrated LLM-as-judge plus human gold sets for validation, then trending in rolling windows. See the framework in LLMO metrics & KPI definitions.
Lexical conformity rate: the percent of outputs that use preferred lexicon and avoid forbidden terms, tied to canonical naming.
Temporal stability score: variance or week-over-week change in compliance; lower variance indicates steadier tone.
Brand sentiment trend: average polarity of brand-referencing answers over time, verified with human spot checks. Geneo ties tone framing to visibility outcomes in its AI Visibility Audit Guide.
Human–model agreement: agreement (e.g., percent or kappa) between human labels and judge LLM on tone/style; used to control label drift.
Multi-engine workflow: prompt libraries, snapshots, and attribution
To compare ChatGPT, Perplexity, and Google AI Overviews, standardize how you query and what you store.
Prompt library and cadence
Build a non-branded decision query set (20–50 prompts) covering your key journeys. Capture answer text, citations, and competitors for each engine. Geneo’s diagnostic playbook outlines this approach in How to diagnose and fix low brand mentions in ChatGPT.
Sample weekly; keep snapshots time-stamped. Record model/mode metadata, system instructions (if applicable), and engine version notes when available.
Evidence logging and attribution
Store the full answer, citation list, link positions, and any source metadata (Perplexity exposes this via APIs; see Perplexity search quickstart). Track changes against your content releases, schema updates, and site structure.
For Google AI Overviews, align content quality and structured data to encourage correct citations; official guidance is documented in Google’s AI features documentation.
Measurement methods
Use calibrated judge LLMs plus human validation to score tone and lexicon adherence; trend weekly aggregates.
For sentiment and psycholinguistic tone, lexicon-based methods (e.g., LIWC, VADER) are fast and interpretable; peer-reviewed evaluations discuss their trade-offs, such as in eLife’s LIWC-based analysis (2020).
Cross-engine deviation and volatility: quantify drift and trigger alerts
Even with disciplined logging, engines drift. UI patterns shift, personalization toggles change, training updates land without notice. You’ll need indices that turn qualitative shifts into numbers you can alert on.
Deviation and volatility indices
Response Drift Index: weighted combination of semantic shift (embedding distance), surface change (edit distance/ROUGE), and factuality differences across snapshots.
Cross-Engine Deviation: per-prompt difference in tone compliance and lexical conformity between engines; aggregate by week.
Prompt Sensitivity: variance in outputs when small prompt wording changes occur; useful for detecting brittle tone adherence.
Change-point detection and governance
Apply SPC/EWMA charts to weekly scores and trigger alerts when thresholds are breached (e.g., >15% drop in tone compliance or citation share). AWS’s prescriptive guidance covers production drift monitoring in Operational excellence for gen AI (AWS, ongoing).
Annotate spikes with provider changelogs and your content releases to avoid false attribution. Industry studies on AI Overview volatility, like Authoritas’ research (2024), help contextualize systemic swings.
Engine-specific behavior to account for
Google AI Overviews
Overviews blend generative answers with links to supporting pages. Visibility depends on content quality and structured data; see Google’s guidance to succeed in AI Search (2025).
Perplexity
Perplexity cites multiple sources inline and exposes source fields; its Sonar Pro API announcement (2025) outlines enterprise features for source retrieval.
OpenAI/ChatGPT
Tone can be influenced by personalization settings, Custom Instructions, Memory, and custom GPTs. OpenAI’s controls are described in Customizing your ChatGPT personality (OpenAI Help) and recent updates reported by TechCrunch (2025).
SOP for product/data teams and agencies
This sequence operationalizes tone tracking over time across engines.
Setup
Define tone/register rules, lexicon guardrails, and forbidden terms; document canonical product and entity names.
Build a 20–50 prompt library; stratify by user journey. Configure weekly sampling across ChatGPT, Perplexity, and AI Overviews; save snapshots, citations, and metadata.
Measurement
Compute KPIs: tone compliance, lexical conformity, sentiment trend, temporal stability, and human–model agreement. Align evidence logs with content change logs.
Track mention/citation share-of-voice and link positions to connect tone outcomes with visibility changes. For content improvements that help citations, see Geneo’s AI citation optimization playbook.
Alerting and diagnosis
Thresholds: investigate when compliance drops >10–20% WoW, sentiment skews negative, or cross-engine deviation widens.
Diagnosis: separate retrieval/content issues from model changes; use embeddings and source metadata.
Remediation
Content fixes: answer-first sections, structured Q→A headings, author/org schema, citable methods/data, clearer canonical naming. Google’s official AI features documentation supports these principles.
Engine-specific tweaks: ensure crawlability and structured summaries for AI Overviews; authoritative hubs and explainers for ChatGPT; well-cited posts for Perplexity.
Reporting
Publish monthly rollups with trend charts, alert annotations, root-cause notes, and recommended actions. Agencies often package this via white-label portals; Geneo describes such workflows in its agency reporting overview.
Neutral example: a Geneo-powered longitudinal tone tracking workflow
Here’s a compact, non-promotional example showing how teams operationalize these steps.
Instrumentation
In Geneo, define tone rules and lexicon guardrails for your brand profile; attach a 30-prompt library covering decision queries.
Schedule weekly runs across ChatGPT, Perplexity, and AI Overviews; Geneo stores answer snapshots, citations, and competitor references.
Scoring and validation
Configure judge LLM scoring for tone compliance and lexical conformity; sample 10% of outputs for human review to calibrate agreement.
Track temporal stability and cross-engine deviation; apply EWMA alerts when drift exceeds set thresholds.
Remediation loop
When Perplexity starts citing outdated product names, trigger content refresh and schema updates; when AI Overviews omit canonical pages, strengthen structured data and answer-first blocks.
Monitor lift: report changes in compliance and citation share in the next monthly rollup.
For broader definitions and KPIs referenced above, Geneo’s LLMO metrics & KPIs and AI Visibility Audit Guide provide additional context.
Pitfalls, limits, and governance
Over-reliance on automated judges: Always run human spot checks; publish inter-rater agreement to avoid silent label drift. Peer-reviewed surveys such as PeerJ Computer Science (2025) discuss model evaluation trade-offs.
Misattribution and broken citations: Engines can cite syndicated or incorrect pages; monitor citation correctness, not just presence. See industry commentary in Digital Content Next’s analysis (2025).
Provider churn and personalization: Document system messages, personalization toggles, and user memory states in ChatGPT; note UI/template shifts in AI Overviews.
Privacy/compliance: Avoid storing sensitive prompts and ensure proper governance when exporting reports.
What to do next
If you’re responsible for product analytics or agency reporting, start a pilot: build the 30-prompt library, set weekly snapshots across engines, and implement tone KPIs with alerts. To speed setup, download a longitudinal tone tracking checklist and SOP template, then run a four-week trial and review stability and deviation.
Suggested resource: Geneo’s AI Search Visibility Tracking overview includes reporting references and practical implementation notes.