
How to find out the prompts your customers are asking on ChatGPT
Discover practical steps to uncover real customer prompts on ChatGPT using compliant tools, public forums, and AI answer tracking—includes template and checklist.
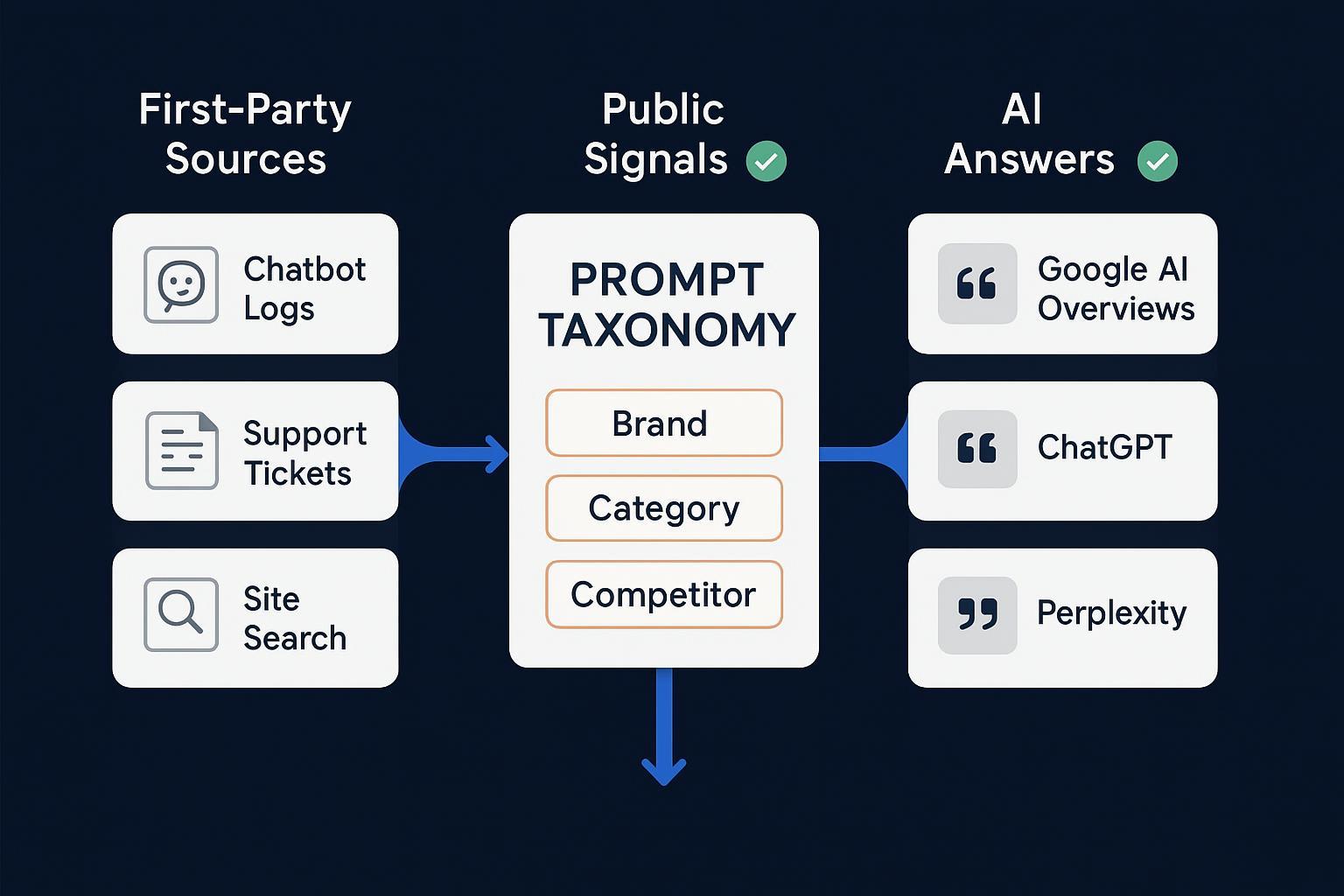
If you’ve ever wondered, “What exactly are people asking ChatGPT about our brand?” this guide shows you how to find out—legally and reliably. You’ll capture three prompt scopes:
Brand mentions (your name, products, pricing, alternatives)
Category/problem prompts (jobs-to-be-done queries where you should appear)
Competitor-comparison prompts (vs. questions that influence switching)
By the end, you’ll have a repeatable workflow, a prompt taxonomy template, and a weekly operating checklist you can implement immediately, whether you use ChatGPT Teams/Business or ChatGPT Enterprise.
Prerequisites and expectations
Time: 90 minutes to stand up the first version; 60–90 minutes weekly to maintain.
Difficulty: Moderate. No engineering required; optional APIs if you prefer automation.
Access: Admin access to your support/chat tools and analytics; optional legal/compliance support if you use Enterprise.
Why this works: You combine compliant first‑party logs, public signals, and AI answer monitoring, then synthesize them into one prompt taxonomy that directly informs your content roadmap.
For context on why prompts matter in AI‑driven search, see the comparison of Traditional SEO vs GEO.
Pick your path: ChatGPT Teams/Business vs Enterprise
As of 2025, the way you access prompt data depends on your ChatGPT plan.
ChatGPT Enterprise: Workspace admins can enable governance and auditing through enterprise features and the Compliance APIs, which support audit logging for e‑discovery and policy enforcement according to OpenAI’s Enterprise Privacy and Microsoft’s archived governance setup in Microsoft Purview for ChatGPT Enterprise (2025). Coordinate with legal before accessing any conversation metadata.
ChatGPT Teams/Business: Admins generally do not have access to private chats; visibility is limited to usage management and aggregate analytics per OpenAI’s Team announcement in Introducing ChatGPT Team (Business). If you’re on Teams/Business, rely on first‑party sources, opt‑in studies, and public data—not internal chat visibility.
Decision tip: If you cannot access internal ChatGPT prompt content, that’s okay—build your pipeline from compliant first‑party logs, public forums, and AI answer monitoring. If you have Enterprise and governance approval, you may add an audit layer to capture prompt metadata within policy.
Step 1 — Capture compliant first‑party signals
Your own data is the safest, most targeted source of prompt language. Focus on three streams.
A) On‑site chatbot conversations (e.g., Intercom)
Manual export: In Intercom, use the conversations data export to pull CSVs of conversation attributes on a schedule. This is useful for metadata like topics, tags, and timestamps. See Intercom’s conversations data export.
API pull (optional): If consented and permitted, use the REST API to retrieve conversation parts (message bodies). Paginate and store securely with role‑based access. Intercom’s developer references cover conversation parts and reporting data export endpoints. Start with their Conversation Part model.
How to confirm it worked
Compare weekly row counts to your expected conversation volume.
Spot‑check a sample of conversation IDs and ensure messages or attributes are populated correctly.
Verify that only authorized roles hold API tokens; rotate credentials periodically.
Common pitfalls and fixes
Export lacks message bodies: Switch to API with proper scopes and consent.
Rate limits: Implement nightly batches and backoff.
PII sprawl: Minimize fields; use an anonymization routine.
B) Support tickets (e.g., Zendesk)
Manual export: Use Zendesk’s CSV/JSON export for tickets and views. Include comments if your plan supports full ticket export. See Zendesk’s export guide.
API pull (optional): The Ticketing API lets you retrieve ticket contents programmatically for deeper analysis and tagging.
How to confirm it worked
Check the number of exported tickets against your reporting dashboard for the same period.
Inspect a handful of ticket threads to ensure comment bodies are present, if permitted.
Common pitfalls and fixes
Missing comments in CSV: Use API or ensure your plan supports full ticket export.
Overcollection risk: Limit fields to what’s needed for prompt discovery; align retention with policy.
C) Internal site search (GA4)
Enable site search: In GA4, turn on Enhanced Measurement for “Site search” and configure query parameters (e.g., q, search).
Export data: Use the GA4 Data API or BigQuery to pull the search_term event parameter and integrate it into your taxonomy. Check retention settings—standard GA4 holds event/user data up to 14 months unless otherwise configured per Google’s data retention overview.
How to confirm it worked
Run a test search on your site and verify the term appears in GA4 reports.
Export a small sample via the Data API to confirm fields and timestamps.
Common pitfalls and fixes
Search terms not appearing: Confirm parameter names; ensure Enhanced Measurement is on.
Sampling confusion: Use Explore or BigQuery for unsampled views when needed.
Privacy and consent guardrails
Use explicit, granular consent for non‑essential analytics and user‑generated text, especially in UK/EU markets. The UK’s regulator provides detailed guidance in the ICO’s consent overview.
Keep retention minimal and document lawful bases. When in doubt, prefer opt‑in consent over legitimate interest.
Step 2 — Mine public signals via official APIs
Public forums and social platforms reveal how people phrase problems and comparisons. Stay ToS‑compliant.
Reddit: Use the official Reddit Data API with OAuth; respect rate limits and avoid unauthorized scraping. See the Reddit Data API wiki.
Stack Exchange/Stack Overflow: If you choose to analyze Q&A, use the official API and follow licensing/attribution. Avoid scraping private Teams instances.
X/Twitter: Use the official Twitter API and access tiers; monitor question‑phrased tweets and brand mentions.
Quora: As of 2025, there’s no public API for bulk content access; rely on manual research or partnerships.
Verification
Log API rate‑limit headers and track successful calls per source.
Compare weekly record counts to typical community activity; investigate sudden drops.
Pitfalls and fixes
Unauthorized scraping: Stick strictly to official APIs, export tools, or manual techniques.
Noisy data: Use intent tags (informational/transactional/navigational) and sentiment scoring; always review human samples.
Tactics resources
For Reddit acquisition tactics, see this practical guide: How to activate Reddit for GEO.
Step 3 — Monitor AI answers and infer prompt patterns
You won’t always see the raw prompts used in AI platforms, but you can monitor the answers and infer common prompt structures.
Google AI Overviews and AI Mode: Track whether your content is cited or summarized in answers. Google explains how these AI features source and present information in the Search Central AI features overview (2025). Maintain a list of trigger queries and check inclusion monthly.
Perplexity Spaces: Use Spaces to organize observed answers, citations, and inferred prompt patterns by topic. Perplexity’s help article What are Spaces? describes how teams can collaborate around collections of threads and files.
ChatGPT web: There is no public API for listing when your brand appears in answers. Use opt‑in studies with participants or a multi‑engine monitoring tool. Avoid scraping chat.openai.com.
Verification
Capture screenshots and URLs of AI answers where your brand or competitors appear.
Track changes over time—AI answers can be volatile; record dates and query phrasing.
Tooling resources
For a neutral overview of options to monitor brand appearances in ChatGPT answers, see Best tools to monitor your brand in ChatGPT answers (2025).
When evaluating trackers, you may also compare vendor approaches in Profound vs Brandlight: AI brand monitoring comparison.
Step 4 — Synthesize everything into a prompt taxonomy
Create a single taxonomy that tags prompts by scope, intent, journey stage, entities, and sentiment. Use the template below.
Prompt taxonomy CSV template
prompt_id,example_prompt,scope,intent,journey_stage,entities,source,source_detail,date_captured,volume,verified_answer_summary,sentiment,content_gap_status
P-0001,"Which alternatives to <YourBrand> integrate with HubSpot?",Competitor-Comparison,Informational,Consideration,"HubSpot,integrations",Reddit,"r/YourCategory",2025-11-02,12,"Lists 5 tools with pricing",Neutral,Needs article
P-0002,"How do I track ChatGPT answers that mention my brand?",Category/Problem,Informational,Awareness,"ChatGPT,monitoring",AI Answer,"Google AI Overviews",2025-11-03,8,"Cites 2 relevant resources",Positive,Covered
P-0003,"Does <YourBrand> have a free tier?",Brand,Transactional,Decision,"Pricing,free",Support,"Zendesk tickets",2025-11-01,26,"Free tier details requested",Neutral,Update pricing page
Tagging schema suggestions
Scope: Brand, Category/Problem, Competitor‑Comparison
Intent: Informational, Transactional, Navigational
Journey stage: Awareness, Consideration, Decision
Entities: Features, integrations, industries, pricing
Source: First‑party (chatbot/support/search), Public (forum/social), AI Answer (Overviews/Perplexity/opt‑in studies)
Sentiment: Positive/Neutral/Negative
Clustering and de‑duplication
Group similar prompts with simple lexical methods (n‑grams, TF‑IDF) or sentence embeddings if available.
Deduplicate exact matches; flag near‑duplicates (e.g., “vs.” vs “compare”).
Human review every cluster before adding to your content roadmap.
Validation routines
Run opt‑in micro‑surveys asking “How would you ask ChatGPT about X?” Collect phrasing and compare to your clusters.
Require two independent sources (e.g., support tickets + Reddit) before committing to major content investments.
Practical workflow example: stand up the pipeline in 90 minutes
Disclosure: Geneo is our product.
Here’s a neutral, replicable setup that any team can follow.
First‑party capture (30 minutes)
Export last 30 days of Intercom conversations (metadata). Pull 200 recent messages via API if permitted.
Export Zendesk ticket views to CSV for the same period.
Enable GA4 site search; verify a test query appears in reports.
Public signals (30 minutes)
Use Reddit’s API to fetch the latest threads in relevant subreddits; pull titles and top comments.
Collect 50–100 public question posts from X via the official API.
AI answers (20 minutes)
Compile 15 trigger queries and check Google AI Overviews for citations to your site.
Create a Perplexity Space per topic area; paste observed answers and inferred prompt patterns.
Synthesize (10 minutes)
Paste examples into the CSV template, tag by scope/intent/stage, and mark content gaps.
What you’ll have at the end
A single spreadsheet with the highest‑frequency prompts across brand, category, and competitors.
A short list of content updates and net-new articles mapped to verified prompt clusters.
Optional visual
Alt text: Geneo logo used as a neutral visual anchor for the example workflow.
Operating cadence, roles, and success signals
Recommended cadence
Weekly: Export/update first‑party logs; harvest public signals; review AI answers; add to the taxonomy.
Monthly: Synthesize findings; validate with micro‑surveys or interviews; ship 2–4 content updates based on clusters.
Quarterly: Refresh your roadmap; archive older data per retention policy; review consent and role‑based access.
Suggested roles
Data steward: Owns exports, retention, and RBAC.
Analyst/SEO: Tags prompts, runs clustering, validates with surveys.
Content lead: Translates clusters into briefs and updates.
Legal/compliance: Reviews governance, especially for Enterprise audit features.
Success signals to track
Increased coverage of category/competitor prompts in AI answers.
Higher inclusion of your pages in Google AI Overviews citations.
Reduced support volume for repeated brand questions after content updates.
Governance and compliance guardrails (as of 2025)
Enterprise audit and archiving: If you use ChatGPT Enterprise, plan your audit logging with legal oversight. OpenAI’s enterprise policies explain data handling and governance in the Enterprise Privacy page, and Microsoft details archived governance connections in Purview’s archive guide.
Teams/Business realities: Without access to private chats, build your pipeline from first‑party, public, and AI answers. OpenAI’s Team announcement, Introducing ChatGPT Team, describes the plan’s scope and controls.
Consent and lawful basis: For UK/EU, use explicit, granular consent for non‑essential analytics and UGC where appropriate. The UK regulator’s ICO consent guidance is a practical reference.
Data retention: Keep retention minimal; review GA4 retention settings per Google’s data retention overview.
Do/Don’t checklist
Do use official APIs and documented export features.
Do restrict access via RBAC and anonymize sensitive fields.
Do publish clear opt‑in language and retention schedules.
Don’t scrape prohibited endpoints or bypass rate limits.
Don’t store raw PII longer than necessary.
Don’t make decisions on single‑source prompts; validate with multiple signals.
Troubleshooting common issues
Empty first‑party exports: Verify permissions; switch from CSV to API; align date ranges across systems; ensure scopes are correct. Intercom’s export documentation and conversation part references are a good starting point: Intercom conversations export.
API rate limits or changes: Implement exponential backoff; log headers; subscribe to platform changelogs.
No Google AI Overview citations: Expand trigger queries; improve content freshness and factual structure; add schema and clear headings.
Compliance uncertainty: Default to explicit consent; minimize fields; document your decisions and revisit quarterly.
Overfitting to niche communities: Balance first‑party and public signals; require corroboration before roadmap changes.
Your next step: Implement the prompt‑capture workflow (template + checklist)
Copy the template and checklist below into your spreadsheet or project management tool and start today.
Prompt taxonomy spreadsheet headers
prompt_id
example_prompt
scope (Brand / Category/Problem / Competitor‑Comparison)
intent (Informational / Transactional / Navigational)
journey_stage (Awareness / Consideration / Decision)
entities (features, integrations, industries, pricing, etc.)
source (First‑party / Public / AI Answer)
source_detail (e.g., Intercom, Zendesk, GA4, Reddit, X, Google AI Overviews, Perplexity)
date_captured
volume (count per period)
verified_answer_summary
sentiment (Positive / Neutral / Negative)
content_gap_status (Needs article / Needs update / Covered)
Weekly operating checklist
Export/update first‑party sources (chatbot, support, site search).
Pull public signals via official APIs (Reddit, X; optional Stack Exchange).
Review AI answers (Google AI Overviews; update Perplexity Spaces).
Add examples to the taxonomy CSV and tag by scope/intent/stage.
Cluster and deduplicate; flag content gaps and prioritize 2–4 updates.
Run a brief opt‑in micro‑survey to validate phrasing on top prompts.
Review privacy/consent notices and retention settings.
Share a 1‑page summary to stakeholders.
Resources to keep handy
Governance and auditing for Enterprise: OpenAI Enterprise Privacy and Microsoft Purview archive setup.
First‑party capture techniques: Intercom conversations export and Zendesk export guide.
Public signals and AI answers: Reddit Data API wiki, Search Central AI features overview, and Perplexity’s Spaces overview.
With this workflow, you’ll capture the real language customers use in ChatGPT and adjacent AI platforms—then turn it into a content roadmap that improves your visibility where it matters.
Related Articles
How to Find Out the Prompts Your Customers Are Asking on ChatGPT
Discover practical steps to uncover real customer prompts on ChatGPT using compliant tools, public forums, and AI answer tracking—includes template and checklist.


What is Predictive Analytics? Definition, Key Components & Applications
Discover what Predictive Analytics is, its definition, core components, and real-world applications in digital marketing and SaaS. Learn how predictive analytics helps forecast trends, optimize campaigns, and boost brand visibility in AI search. Read the full guide for marketers and SaaS professionals.

What is Retrieval-Augmented Generation (RAG)? Definition, Workflow & SEO Applications
Learn what Retrieval-Augmented Generation (RAG) is, how it works, and why it matters for content optimization and SEO. Discover RAG’s definition, technical workflow, key components, and real-world applications in AI-powered search, brand visibility, and enterprise content strategies.