
Best Practices for Monitoring AI Tone Alignment Trends (2025)
Discover 2025 best practices for monitoring AI engine tone alignment, with expert guides on trend visualization and threshold alerting for PR teams.
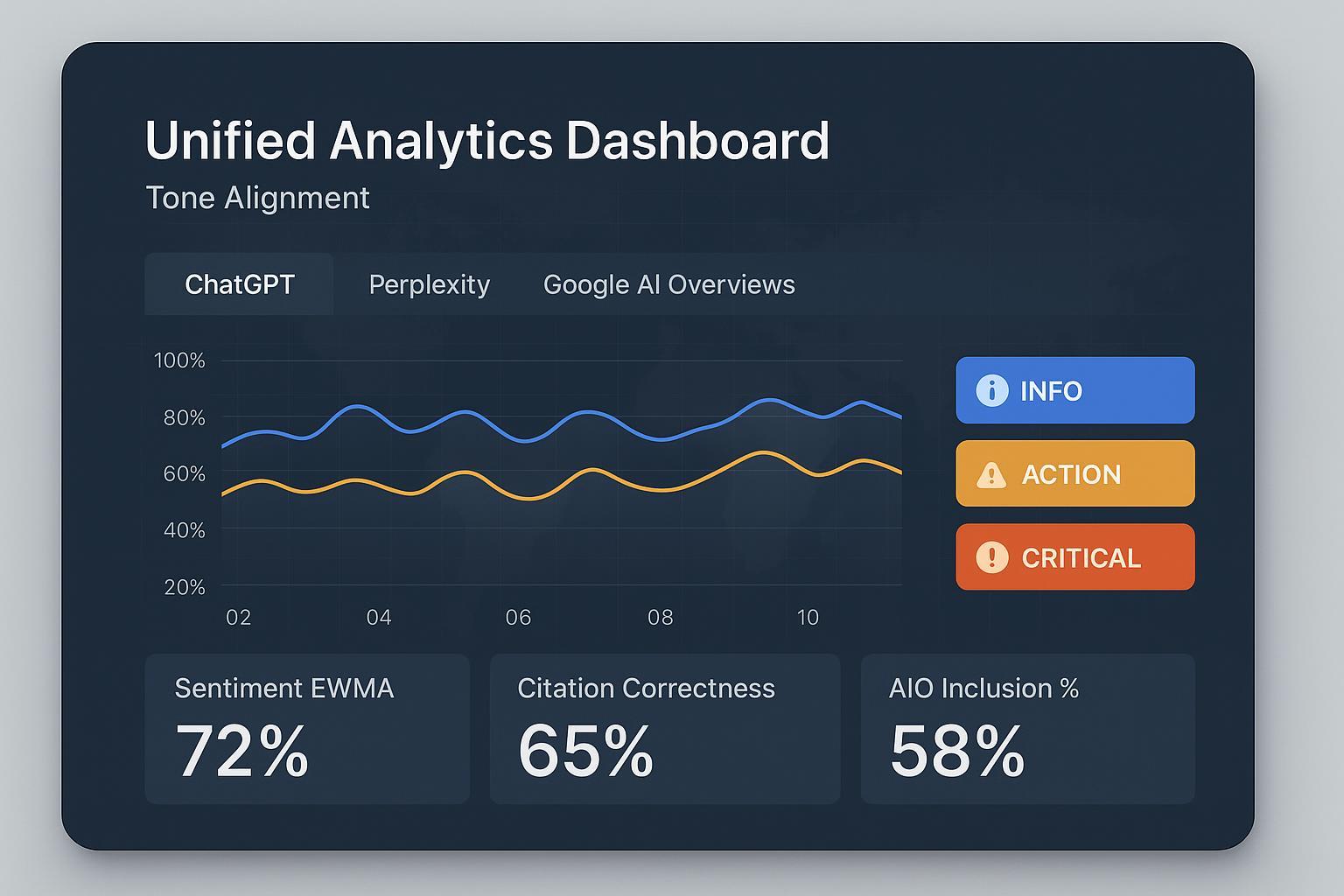
When AI answer engines summarize your brand, the words—and the feel—shape reputation long before anyone clicks. Google’s AI Overviews have been shown to suppress clicks when summaries appear, which raises the stakes for inclusion and tone consistency across channels.[According to the Pew Research Center (2025), Google users click less when an AI summary is present, as discussed in the analysis of AIO click behavior; SEER Interactive’s September 2025 cohort update offers similar evidence.] For PR and communications teams, monitoring tone alignment over time—not just snapshots—is now part of core media monitoring.
1) Turn brand voice into measurable tone dimensions
Brand voice guidelines are rich, but hard to measure unless you translate them into observable signals. Start with a compact model:
Sentiment polarity and emotional valence (e.g., negative/neutral/positive ratios).
Professionalism and politeness (markers of respectful phrasing and clarity).
Friendliness and empathy (lexical cues; how supportive the language sounds).
Brand lexicon adherence (approved terms, product names, boilerplate accuracy).
Compliance and reputational risk flags (toxicity, misinformation indicators).
Document acceptance criteria per dimension, then assemble a canonical test suite of brand-relevant prompts for ChatGPT, Perplexity, and Google AI Overview. Keep “golden” reference outputs as yardsticks for semantic/tone distance. For measurement scaffolding, see our overview of Large Language Model Observability (LLMO) dimensions in LLMO metrics: accuracy, relevance, personalization.
2) Cross-engine monitoring you can operationalize
Standardize prompts and run them on a predictable cadence (weekly for strategic, daily for high-risk campaigns). Track:
Engine inclusion (does the brand appear in AIO, and how often?).
Citation correctness and source authority.
Tone dimensions and sentiment ratios.
Model/version metadata and retrieval context for auditability.
An audit trail matters for postmortems and root-cause analysis. Datadog’s observability guidance outlines how to instrument LLM pipelines with metadata, which maps cleanly to PR monitoring needs; see LLM Observability documentation. And for context on why Google AIO visibility matters, review SEER’s 2025 CTR impact update alongside the Pew study above.
3) Visualization that tells you what changed—and when
Dashboards should help you spot drift, not create noise. A few pragmatic rules:
One message per chart: e.g., “Negative sentiment ratio by week.”
Consistent time scales across charts for easy scanning.
Pair a line chart with a stacked series breakdown when you need composition.
For trend detection, two simple-but-powerful tools:
EWMA (Exponentially Weighted Moving Average) smooths short-term jitter so subtle direction changes stand out.
CUSUM (Cumulative Sum) flags sustained deviations from baseline, catching larger shifts.
If your data has cycles (weekday vs. weekend, product launch periods), baseline with seasonality-aware methods to reduce false alarms. A practical primer is Metabase’s time-series visualization guide.
4) Threshold alerting that PR teams can trust
Static rules are clear; adaptive rules are resilient. Use both:
Static thresholds: “Trigger an action alert when negative sentiment rises >15% absolute vs. the last 28-day average.”
Adaptive baselines: “Trigger critical when the EWMA deviates >3σ and CUSUM confirms a sustained shift.”
Make alerts role-aware and context-rich. Include source authority, reach, and citation provenance so the on-call owner knows what to do next. Align with governance frameworks (DETECT/RESPOND) common to risk programs; NIST’s AI RMF offers a helpful north star in AI Risk Management Framework.
Alert Tier | Typical Trigger | Context to Include | PR Action |
|---|---|---|---|
Informational | Minor deviation vs. baseline; visibility dips in one engine | Engine, prompt group, last-28-day baseline | Log in weekly digest; monitor next run |
Action | >15–20% absolute increase in negative sentiment; citation correctness below threshold for multiple prompts | Source list, authority scores, sample outputs | Assign owner; prepare talking points; request content fixes |
Critical | >3σ EWMA/CUSUM deviation with high-reach sources; AIO inclusion collapse across priority prompts | Influencer reach, misinfo/toxicity flags, competitor overtake notes | Escalate per playbook; issue holding statement; run postmortem |
5) Workflow example (Disclosure: Geneo is our product.)
How this looks in practice with Geneo:
Dashboards visualize cross-engine signals—AIO inclusion %, sentiment ratios, citation correctness—and let you toggle by prompt set or product line.
Trends apply EWMA smoothing by default, with anomaly bands to flag outliers. You can pin “golden” outputs to compare current tone distance.
Thresholds combine static (e.g., sentiment ratio changes) and adaptive baselines (rolling 28–90 day). Alerts are routed to comms owners with the context noted above.
Weekly reports summarize drift and visibility; monthly views benchmark competitors’ share of AI voice.
For setup context, see the AI visibility audit workflow and this explainer on AI visibility and brand exposure.
6) Micro-case: triaging a tone drift event
A consumer tech brand notices a sudden uptick in negative tone across ChatGPT and Perplexity, while Google AIO inclusion dips for several priority prompts. Geneo’s alert fires at “Action” level: negative sentiment is up 18% absolute versus the 28-day baseline, and citation correctness falls below the configured threshold across four prompts.
Triage steps:
Review alert context: confirm the high-reach sources driving the change and examine sample outputs.
Check citation provenance: identify the misaligned or outdated references.
Coordinate corrective content: update product pages and FAQs; publish a clarifying post; engage with journalists/bloggers where needed.
Prepare holding statements and Q&A for spokespeople; align with legal if necessary.
Monitor next cycles: verify that AIO inclusion rebounds and sentiment stabilizes; run a short postmortem to refine thresholds.
To strengthen inclusion where brand mentions lag, use our diagnostic guide for low mentions in ChatGPT.
7) Quick-start SOP (30–90 days)
Weeks 1–2: Define tone dimensions and acceptance criteria per engine; build your canonical prompt suite; assign owners; configure dashboards and alert tiers.
Weeks 3–6: Establish baselines; enable EWMA/CUSUM anomaly detection; attach playbooks to alerts; tune thresholds to cut noise.
Weeks 7–12: Add competitive benchmarking; track share of AI voice and citation correctness; implement content fixes and measure lift.
8) Ready to start a trial? What to prepare
Before you kick off:
Gather brand voice guidelines, approved lexicon, priority prompts, and high-stakes topics.
Identify PR owners for informational/action/critical tiers; confirm escalation paths.
Decide your reporting rhythm (weekly digests, monthly reviews) and success metrics (e.g., smaller variance in tone, faster alert-to-action time).
If you’re evaluating platforms, a trial should confirm three things: dashboards make trend changes obvious, alerts arrive with the right context, and postmortems lead to better thresholds. That’s how you turn AI answer monitoring into a dependable part of your media operations.