
2025年AI友好结构化清单:LLM消化Listicle与ItemList实操指南
12+条2025最新AI友好结构化清单!覆盖LLM列表优化、ItemList标注、可索引分块与验证监测,助力内容被AI引用。点击获取实操指南!
by
阎志涛
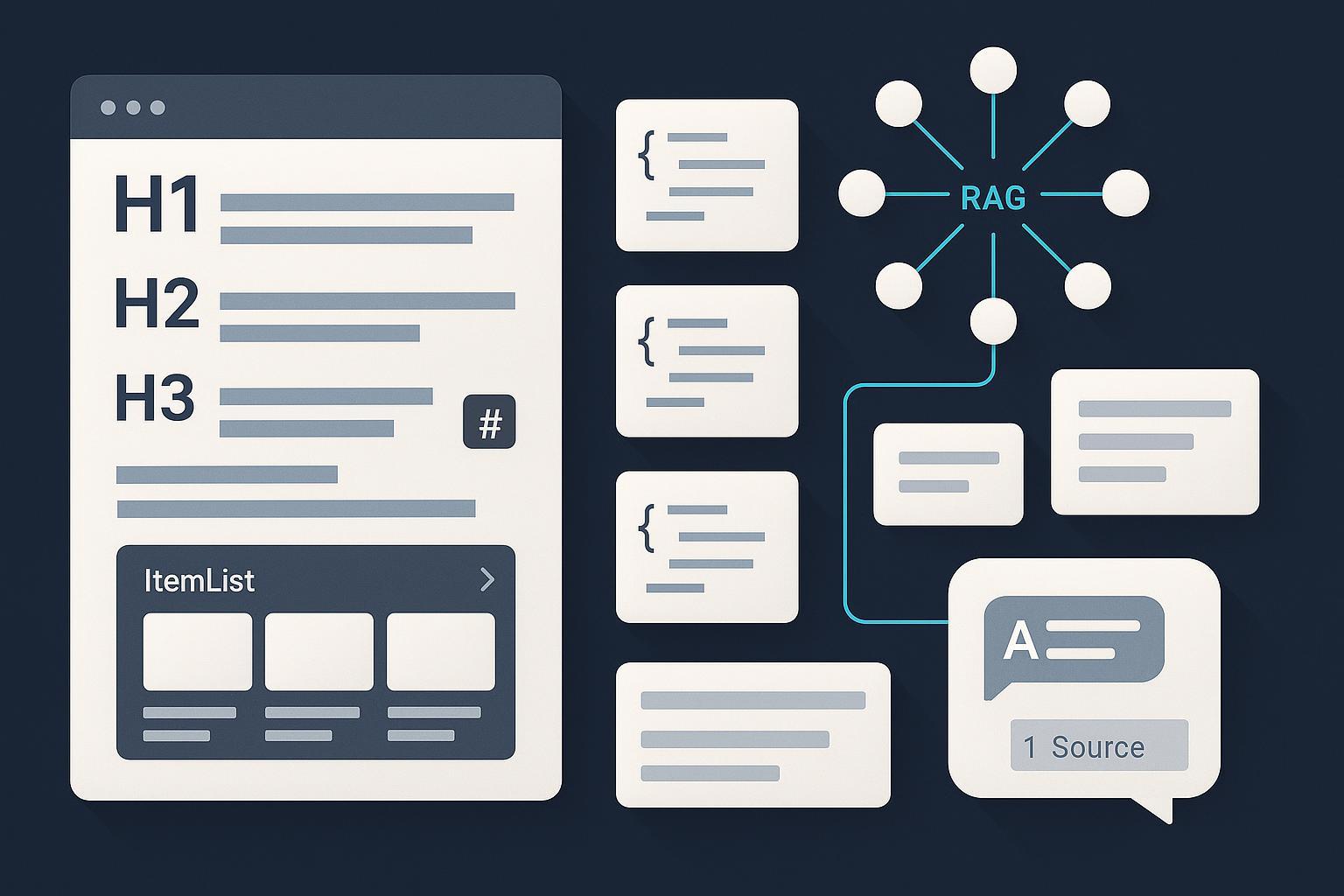
在 2025 年,AI Overviews/AI Mode、Perplexity、各类聊天机器人正越来越多地“读写网络”。你的列表是否便于它们解析、引用,并把精准的段落带回给用户?这份实操清单聚焦“机器可提取性 + 可验证性”,用工程化方法把传统 listicle 升级为 LLM 友好清单。
—
如何使用这份清单
- 每条都包含定位、关键动作、代码/示例、验证方式、常见误区与证据链接。
- 证据优先引用权威一手来源(Google Search Central、schema.org、web.dev、Anthropic、Perplexity 等)。
- 我们不承诺“必出 AI Overviews”。行业共识是:页面需可索引、内容以人为本且可抓取;结构化数据和清晰结构能提升理解与引用几率(见 2023–2025 官方与业界说明)。
主清单:让列表对机器更友好(12 条)
1) 用清晰的标题分层与稳定锚点,映射“一事一段”
- 要点:H1/H2/H3 清晰,列表项与小节一一对应;每项有可见标题与命名锚点,辅以稳定 URL(路径/查询参数),不要只依赖 #fragment。
- 代码/示例:
/guide/ai-list?item=itemlist-markup优于/guide#itemlist(片段仅为前端定位)。 - 验证:检查页面是否为每个要点提供可独立访问的 URL;在站内搜索与日志中验证点击与抓取。
- 误区:把
#fragment当作可索引单元;对单页应用用片段切换“不同内容”。WHATWG 定义说明片段不会发送至服务器,搜索索引基于不含片段的 URL(参见 2024 版标准)。参考 WHATWG URL 标准对“fragment”的定义 与 Google 的 JavaScript SEO 基础(History API 建议)。
2) 为列表添加 ItemList 标注,明确顺序与元素边界
- 要点:用
ItemList+ListItem(含position)表达列表顺序;item至少包含name与对应url,与页面可见内容一致。 - 代码:
{
"@context": "https://schema.org",
"@type": "ItemList",
"itemListElement": [
{"@type": "ListItem", "position": 1,
"item": {"@type": "Thing", "name": "标题分层与锚点", "url": "https://example.com/guide#structure"}},
{"@type": "ListItem", "position": 2,
"item": {"@type": "Thing", "name": "ItemList 标注", "url": "https://example.com/guide#itemlist"}}
]
}
- 验证:用 Google Rich Results Test 与 Schema Markup Validator;确保与页面可见顺序一致。参考 Google 的 Carousels(beta)指南 与 结构化数据目录。
3) FAQPage 标注:用作“机器理解”,不以富结果为唯一目标
- 要点:自 2023 起,FAQ 富结果展示收紧,多数站点不再常显;但规范的问答结构与 JSON-LD 仍可帮助 AI 正确抽取与归档。
- 代码:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "如何让列表更易被 AI 引用?",
"acceptedAnswer": {
"@type": "Answer",
"text": "保持清晰分层,使用 ItemList/FAQ 标注,并为每项提供权威来源链接与日期。"
}
}]
}
- 证据:参见 Google 的 FAQPage 结构化数据指南(长期维护) 与 2023–2024 展示策略更新汇总。
4) HowTo:保留结构化步骤,提高机器可读,但不指望 SERP 富结果
- 要点:HowTo 富结果在 2023 后逐步弃用;保留
HowToStep/HowToSection有助于步骤理解与垂直产品体验。 - 证据:见 Google 的 更新与政策变更总览(2023–2025)。
5) 让每个列表项“自给自足”:短段落、明确术语、局部可引用
- 要点:按“最小语义单元”写作;每项包含定义、关键动作与示例;跨段引用时尽量减少前文依赖,便于 LLM 独立抽取。
- 验证:让同事只阅读单个小节,是否能独立理解与执行;观察 Perplexity/Chatbot 是否引用整段而非散词。
6) RAG 友好分块:基于语义边界,附元数据与轻量重排
- 要点:以 句/段 为边界;常见实践在 256–1024 tokens;可用递归分割或滑动窗口保留上下文;给每块加标题、来源、日期等 metadata,支持过滤与重排。
- 证据:NVIDIA(2024)分享了分块与重排的工程实践思路,可用于参考方法论与参数选择,见 NVIDIA 开发者博客对“最佳分块策略”的讨论。Anthropic 则在 2024–2025 的 Projects 文档中强调在上下文不足时自动启用 RAG,见 Anthropic 对 Projects 与 RAG 的官方说明。
7) 引用与证据链:权威来源+清晰时间戳
- 要点:每项至少 1 个权威外链;在正文附近标注年份与上下文;链接到原始文档或数据页,避免二次转载。
- 证据:Google 在 2024–2025 的内容指南持续强调“有用、可靠、以人为本”的原则与透明来源,见 Creating helpful content 指南。
8) AI Overviews/AI Mode 的“必要不充分条件”:可索引 + 可抓取 + 高质量
- 要点:行业共识是,页面必须可被索引与抓取,结构化数据与清晰分段可辅助理解,但不保证入选。你可用 Search Console 检查索引状态。
- 证据:参见 2025 年媒体对 AI Mode/Overviews 的解释性报道,强调“先被索引”的底线,例如 Search Engine Land 关于 AI Mode/Overviews 的索引要求报道,以及 Google 的 SEO 入门指南(索引与抓取基本面)。
9) E‑E‑A‑T 与作者/组织元数据:让可信度“被看见、被标注”
- 要点:页面显著处展示作者、机构与日期;JSON‑LD 中同步
author/publisher/datePublished/dateModified;为可验证性提供“署名+更新记录”。 - 证据:参考 Google 对排名系统与内容质量的说明(2024–2025),见 Ranking systems 指南 与 Search Essentials。
10) 可访问性与性能:用 Core Web Vitals 把体验打牢
- 要点:以 75 百分位为目标:LCP ≤ 2.5s、CLS ≤ 0.1、INP ≤ 200ms;移动端优先,减少阻塞脚本与不稳定布局。
- 验证:用 PageSpeed Insights 与 Search Console 的 CWV 报告。
- 证据:见 web.dev 的核心指标总览与专页解读(2024–2025),如 Core Web Vitals 总览 与 LCP 指标详解。
11) URL 策略:避免“片段驱动”的内容切换与重复切片
- 要点:用规范化(canonical)巩固重复信号;管理分面导航与参数,避免 URL 爆炸与权重稀释;Scroll‑to‑text 仅用作前端定位。
- 证据:参见 Google 对 分面导航抓取管理 与 规范化重复 URL 的指导;关于文本片段行为,见 Chrome 文档对 Text Fragments 的解释。
12) 发布前后“可验证”流程:从标注校验到抓取日志
- 要点:上线前用 Rich Results Test/SMV 校验;上线后看 Search Console 的索引/增强报告;结合服务器日志与实际 SERP/AI 引用回溯。
- 工具: Rich Results Test 与 Schema Markup Validator,以及 PSI 的 CrUX 数据来源说明。
工具箱(含监测)
- 结构化与验证:
- Google Rich Results Test(FAQ/ItemList/Carousels 标注验证)
- Schema Markup Validator(schema.org 兼容性检查)
- Google Search Console(索引与增强报告)
- 写作与质量:
- 断链/引用稽核工具、站内链接审计脚本
- AI 引用与品牌提及监测:
- Geneo:跨 ChatGPT、Perplexity、Google AI Overviews 等平台监测品牌提及、引用与情感,并给出内容优化建议。披露:Geneo 为我们的产品(Disclosure: Geneo is our product.)。
- 第三方可选:Brand24 等(功能与价格因版本而异,subject to change)。
可复制代码模板
ItemList(最小骨架)
{
"@context": "https://schema.org",
"@type": "ItemList",
"itemListElement": [
{"@type": "ListItem", "position": 1,
"item": {"@type": "Thing", "name": "清晰标题分层", "url": "https://example.com/guide#structure"}},
{"@type": "ListItem", "position": 2,
"item": {"@type": "Thing", "name": "ItemList 标注", "url": "https://example.com/guide#itemlist"}}
]
}
FAQPage(最小骨架)
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "AI Overviews 是否一定会引用?",
"acceptedAnswer": {
"@type": "Answer",
"text": "不会。行业共识是:先确保页面可索引与可抓取,并提供高质量、结构清晰的内容;结构化数据有助于理解但不保证入选。"
}
}]
}
Article/BlogPosting 元数据(片段)
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"headline": "设计给 LLM 消化的列表:从 Listicle 到 AI 友好清单(2025)",
"author": {"@type": "Person", "name": "内容系统工程师"},
"publisher": {"@type": "Organization", "name": "YourOrg"},
"datePublished": "2025-09-11",
"dateModified": "2025-09-11"
}
上线前“10 步校验清单”
- H1/H2/H3 是否与每个列表项一一映射?
- 是否为每个关键项提供稳定 URL(路径或参数),非仅 #fragment?
- ItemList 是否包含 position、item.name 与 item.url,并与可见顺序一致?
- FAQ/HowTo 标注是否与页面文案一致,且无误导性隐藏?
- 是否为每个关键主张附上权威来源与年份?
- 段落是否“自给自足”,可被独立引用?
- 分块与元数据是否便于 RAG 检索与过滤?
- 页面是否展示作者、组织、日期,并在 JSON‑LD 同步?
- Core Web Vitals 在 75 百分位是否达标(LCP/CLS/INP)?
- Rich Results/SMV 验证通过,Search Console 报告正常?
常见坑与规避
- 只用
#fragment当版本切换或内容分面,会导致抓取与索引脱节(见 WHATWG 与 Google JS SEO 指南)。 - ItemList 缺
position或与页面顺序不一致,影响机器理解(参见 Carousels/ItemList 文档)。 - 为追求富结果滥用 FAQ/HowTo,与页面不一致或堆砌关键词(2023 后政策收紧)。
- 引用用二手博客而不是原始文档,削弱信任度与可验证性。
- 忽视移动端性能与可访问性,导致 LCP/INP 超标,影响整体体验与抓取效率(web.dev 指标)。
方法透明度:我们如何选择与排序
- 评估维度:能力契合度(30%)、实施成本(20%)、生态兼容(20%)、证据质量(20%)、稳定性与支持(10%)。
- 数据来源优先:Google Search Central、schema.org、web.dev、Anthropic、Perplexity 官方资料;必要时辅以 2025 行业报道与技术博文,并在正文中标注。
下一步
- 先用本文的“10 步校验清单”给你的头部 Listicle 做一次改造,生成 ItemList/FAQ 的 JSON‑LD 并通过验证工具校验;随后用 Search Console 观测索引与增强表现。若你需要跨平台的 AI 引用/品牌提及监测与优化建议,可尝试工具箱中的 Geneo(上述披露已说明)。
—
附加参考(延伸阅读):
- Google: 结构化数据入口与目录 | SEO 入门指南
- schema.org: ItemList | ListItem
- web.dev: Core Web Vitals 总览
- Perplexity: Introducing Deep Research(2024)
by
阎志涛



