
RAG : meilleures pratiques et signaux GEO pour l’optimisation IA locale
Explorez les meilleures pratiques RAG : intégration des signaux géographiques, workflow technique, RGPD, monitoring local IA. Idéal experts SEO/IA.

Quand une question suppose un contexte local — “magasin de pièces vélo près de moi”, “délais de collecte à Lyon 7”, “loi bruit en Île‑de‑France” — un RAG bien conçu doit comprendre l’intention, restreindre l’espace de recherche et pondérer la réponse par la proximité géographique et la qualité de la source. Comment y parvenir sans sacrifier la pertinence sémantique, la conformité RGPD et la traçabilité?
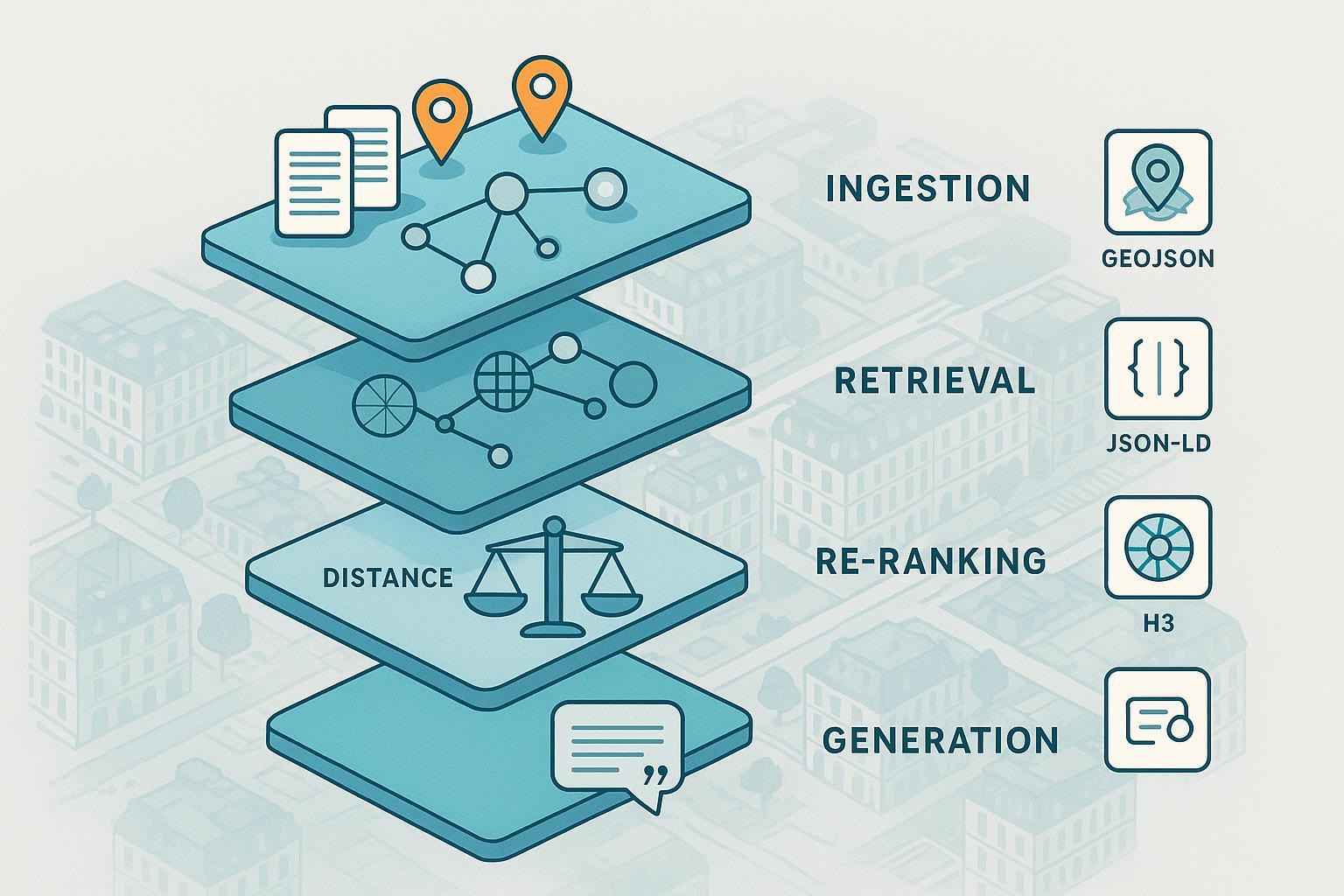
1. Les signaux GEO qui comptent pour un RAG
Dans un pipeline RAG, les signaux GEO jouent trois rôles majeurs: contextualiser, filtrer, et re-classer.
- Contexte: lier un document à un lieu (Point) ou une zone (Polygon) et préciser la granularité (adresse, quartier, ville, région). Pensez-y comme au “périmètre d’éligibilité” de l’information.
- Filtrage: limiter la recherche aux contenus pertinents pour une position ou une zone (rayon, commune, département, pays). Cela évite l’“over-retrieval” et améliore la fidélité de la génération.
- Re‑ranking: départager des candidats proches sémantiquement en tenant compte de la distance, de l’appartenance à une zone administrative, de la fraîcheur et de l’autorité de la source.
Ce triptyque suppose des données locales bien modélisées et un moteur capable de combiner recherche lexicale, vectorielle et géospatiale sans casser la latence.
2. Modéliser correctement vos données locales
Deux formats font gagner du temps, car ils sont standards et interopérables.
- GeoJSON: pour encoder géométries et propriétés (Point, Polygon, MultiPolygon) en WGS84. Respecter l’ordre [longitude, latitude] et les règles de fermeture/orientation des anneaux. La spécification officielle IETF est détaillée dans le RFC 7946 publié par l’IETF en 2016 et toujours la référence en 2025; voir le document de l’IETF dans le RFC 7946 — The GeoJSON Format (IETF).
- JSON‑LD LocalBusiness: pour décrire entités locales (nom, adresse normalisée, coordonnées, horaires, téléphone). Ce balisage aide la compréhension machine et l’éligibilité aux résultats enrichis. Google centralise les règles d’apparence IA dans sa documentation; voir les consignes 2025 dans Google — AI features and your website (documentation développeurs).
Extrait JSON‑LD (simplifié) à intégrer sur vos pages locales:
{
"@context": "https://schema.org",
"@type": "LocalBusiness",
"name": "Atelier Vélo Lyon 7",
"telephone": "+33 4 00 00 00 00",
"address": {
"@type": "PostalAddress",
"streetAddress": "12 rue de l'Exemple",
"postalCode": "69007",
"addressLocality": "Lyon",
"addressCountry": "FR"
},
"geo": {
"@type": "GeoCoordinates",
"latitude": 45.748,
"longitude": 4.85
},
"openingHours": "Mo-Sa 09:00-19:00"
}
Côté indexation, conservez les géométries (ou au minimum un Point) comme métadonnées et générez des embeddings sur le texte (produits, politique locale, FAQ, etc.). Les champs structurés (codes INSEE, CP, pays ISO) facilitent les filtres.
3. Workflow RAG + GEO pas‑à‑pas
- Gouvernance & conformité: clarifier finalités, base légale, minimisation et politique de conservation. Les recommandations 2025 de la CNIL cadrent les usages IA et géolocalisation; voir les conseils de la CNIL publiés en 2025 dans CNIL — IA et RGPD: recommandations pour une innovation responsable.
- Ingestion & normalisation: nettoyer textes, harmoniser toponymes, valider coordonnées, produire GeoJSON/JSON‑LD, taguer fraîcheur/source.
- Embeddings: générer des vecteurs adaptés au domaine; par exemple les modèles “text‑embedding‑3” d’OpenAI sont documentés par l’éditeur en 2025; voir la fiche modèle OpenAI — text‑embedding‑3‑large (documentation 2025).
- Indexation: stocker geo_point/geo_shape (ou geoCoordinates) + dense_vector; prévoir champs scalaires (ville, code postal) utiles aux filtres rapides.
- Retrieval hybride: combiner filtre géo (distance/zone), BM25 et recherche vectorielle pour un top‑K resserré.
- Re‑ranking: reclasser les candidats par pertinence sémantique pondérée par distance, appartenance à une zone, fraîcheur et autorité.
- Génération contrôlée: forcer les citations de contexte, préciser la localité, refuser de répondre quand le contexte ne couvre pas la zone.
- Évaluation continue: mesurer recall, pertinence, fidélité, latence; A/B tester pondérations et tailles de contexte.
4. Retrieval hybride et re‑ranking spatial + sémantique
Un moteur de recherche opérationnel doit accepter un filtre géo strict avant la similarité, puis pondérer la distance au re‑ranking. Pensez distance comme “barrière anti‑bruit”: elle élimine tôt les faux positifs hors zone.
Exemple Elasticsearch (DSL) — kNN + filtre géo 50 km:
POST my_index/_search
{
"knn": {
"field": "text_embedding",
"query_vector": [/* … */],
"k": 32,
"num_candidates": 200
},
"query": {
"bool": {
"filter": [
{ "geo_distance": { "distance": "50km", "location": "45.748,4.85" } },
{ "term": { "country": "FR" } }
],
"should": [ { "match": { "body": "réparation vélo dérailleur" } } ]
}
},
"sort": [
{ "_geo_distance": { "location": "45.748,4.85", "order": "asc", "unit": "km" } }
]
}
Exemple Weaviate (GraphQL) — hybrid + WithinGeoRange:
{
Get {
Document(
where: {
operator: WithinGeoRange,
path: ["location"],
valueGeoRange: { point: { latitude: 45.748, longitude: 4.85 }, distance: 50000 }
},
hybrid: { query: "réparation vélo dérailleur", alpha: 0.5 }
) {
title
_additional { distance certainty }
}
}
}
Au re‑ranking, agrégez un score final par une combinaison linéaire simple: 0,6 pertinence sémantique + 0,3 distance normalisée + 0,1 fraîcheur. Ajustez par secteur et testez régulièrement; il n’existe pas de recette universelle.
5. Mesure et monitoring de la visibilité IA
Les fonctionnalités IA de Google (dont AI Overviews) n’exigent pas de balisage spécial au‑delà des bonnes pratiques Search. Google documente leurs conditions d’apparition et l’intégration dans les rapports Search Console depuis fin 2024; voir la documentation développeurs 2025 dans Google — AI features and your website.
Disclosure: Geneo est notre produit. À titre d’exemple, pour suivre les réponses génératives qui citent vos pages dans ChatGPT, Perplexity ou AI Overviews, un outil de monitoring multi‑plateformes comme Geneo (suivi de mentions, tonalité, historiques, recommandations) aide à détecter les gains/pertes “zero‑click” et à prioriser les correctifs sur les contenus locaux.
Indicateurs à suivre (hebdomadaire puis mensuel):
| KPI | Définition | Cible de départ |
|---|---|---|
| Part IA locale | % de questions locales où vous êtes cité dans les réponses IA | +5 pts en 90 j |
| Couverture zones | % de communes/arrondissements avec au moins 1 page locale éligible | >80 % |
| Temps de fraîcheur | Âge moyen (jours) des pages citées | <60 j |
| Distance médiane | Distance médiane (km) entre l’utilisateur cible et le point du document | ↓ trimestre |
| Faithfulness | Part de réponses IA citant exactement vos sources | >95 % |
6. Checklist RGPD pour la géolocalisation
- Documenter la finalité et la base légale (consentement explicite si nécessaire), informer clairement les utilisateurs et limiter la fréquence de collecte.
- Minimiser la précision (agrégations/maillage H3 quand la précision au mètre n’est pas requise), pseudonymiser/anonymiser les logs, chiffrer en transit/au repos.
- Restreindre l’accès (RBAC), tracer les consultations (journalisation), définir des durées de conservation et une purge automatisée.
- Encadrer les sous‑traitants par des DPA, vérifier les transferts hors UE, et tester régulièrement les procédures d’effacement.
7. Cas d’usage sectoriels
- E‑commerce local: pages magasins enrichies en JSON‑LD, inventaires avec points géolocalisés, retrieval hybride; re‑ranking par distance et disponibilité. Résultat: meilleure mise en avant pour les requêtes “près de moi” avec variantes de produits.
- Collectivités/administrations: notices et services par commune/arrondissement, filtres d’inclusion polygonale; génération contrôlée citant les délibérations ou arrêtés officiels; bénéfice: réponses exactes par territoire.
- Assistants multi‑régionaux: pipeline de désambiguïsation (toponyme + pays/région), filtres par zone, prompts qui imposent la locale; suivi stricte de la latence pour rester utile sur mobile.
8. Pièges courants et contrôles qualité
Les toponymes ambigus (Saint‑Denis métropole ou La Réunion?) exigent soit un pré‑questionnement (“de quelle ville parlez‑vous?”), soit une réécriture de requête multi‑hypothèses et une sélection par score. La fraîcheur reste critique: sans timestamps pondérés, vous risquez d’exposer des horaires ou règles obsolètes. Enfin, les hallucinations surviennent surtout quand le filtre géo est laxiste et que le contexte est trop verbeux; mieux vaut moins de documents, mais parfaitement situés. Vous préféreriez une réponse honnête qui admet “je ne sais pas” plutôt qu’un conseil faux, n’est‑ce pas?
Côté biais, surveillez l’hétérogénéité territoriale de vos sources (rural vs urbain) et la couverture des quartiers périphériques. Une grille d’hexagones (type H3) peut aider à visualiser et combler les trous de couverture.
9. Prochaines étapes
- Normaliser vos données locales: adresse, GeoJSON, JSON‑LD, codes administratifs; générer des embeddings cohérents.
- Déployer un retrieval hybride avec filtre géo strict et un re‑ranking qui pondère distance, fraîcheur, autorité.
- Mettre en place un tableau de bord de visibilité IA: part IA locale, couverture des zones, fraîcheur, faithfulness, distance médiane.
- Opérer un audit RGPD: minimisation, anonymisation, conservation, DPA, transferts.
- Industrialiser: tests A/B des pondérations, jobs d’actualisation des index, surveillance de la latence et de la fidélité.
Pour les équipes qui veulent aller vite, commencez par un périmètre pilote (une ville, une ligne de produits), validez les gains sur 90 jours, puis étendez par grappes de zones. Pensez votre “périmètre” comme un polygone de sécurité: tout ce qui est dedans doit être excellent; tout ce qui est dehors n’existe pas pour votre RAG jusqu’à preuve du contraire.
Références citées dans l’article: RFC 7946 — The GeoJSON Format (IETF); Google — AI features and your website (documentation 2025); CNIL — IA et RGPD (2025); OpenAI — text‑embedding‑3‑large (2025); Elastic — Geospatial search with LLM and Elasticsearch (2025).



