
Optimisation des entités : meilleures pratiques pour le classement IA
Guide expert sur l’optimisation des entités pour la recherche IA : cas pratiques, code JSON-LD, audits multi-plateformes et stratégies de classement pro.

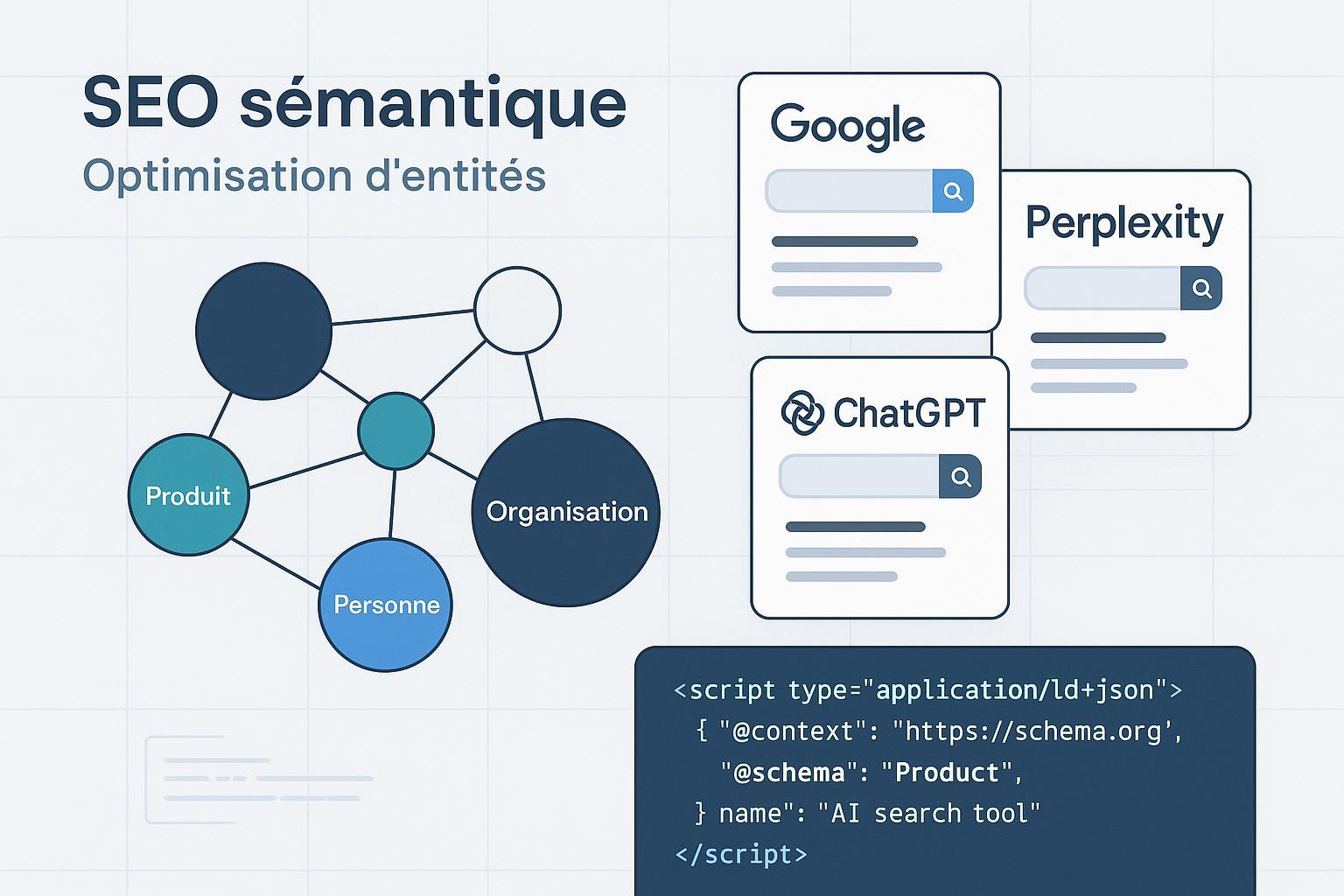
Quand une requête part dans un moteur piloté par l’IA, ce ne sont pas « des mots » qui voyagent, mais des entités reliées entre elles. Si vos entités (marque, produits, personnes, lieux, concepts) sont claires, stables et reliées à des identifiants fiables, vous augmentez vos chances d’être compris, cité… et cliqué. Voyons concrètement comment l’optimisation des entités influence les classements et les citations dans les AI Overviews de Google, Perplexity et les assistants fondés sur des LLM — et surtout comment l’implémenter proprement.
1. Entités, graphe de connaissances et recherche IA
Une entité est un objet identifiable de manière unique (organisation, produit, personne, lieu, concept) avec des attributs (nom, description, logo…) et des relations (qui/quoi/ où/comment). Les moteurs modernes mappent ces entités dans des graphes de connaissances; Google s’appuie notamment sur son Knowledge Graph pour relier des nœuds et générer des réponses synthétiques.
Les standards publics jouent un rôle majeur. Google conseille d’exposer des données structurées pour aider la compréhension des systèmes et l’éligibilité aux résultats enrichis. Son guide « Fonctionnalités d’IA et votre site Web » explicite comment le contenu peut être utilisé et affiché dans le Mode IA/AI Overviews, sans garantir l’apparition à chaque requête. Voir la documentation officielle en français dans les fonctionnalités d’IA et votre site Web (Google, FR).
Deux points techniques reviennent systématiquement sur le terrain:
- JSON-LD est le format recommandé par Google pour le balisage schema.org; le W3C a normalisé la spécification dans JSON‑LD 1.1 (W3C Recommendation).
- Les propriétés
@id(identifiant stable) etsameAs(liens vers des identifiants externes comme Wikidata) sont clés pour désambiguïser vos entités et les relier à l’écosystème.
2. Pourquoi l’optimisation des entités influe sur les classements IA
Les systèmes de réponse générative opèrent en deux temps simplifiés: compréhension sémantique de l’intention et synthèse appuyée sur des sources de corroboration. Deux conséquences concrètes pour vous:
- L’ordre organique classique n’est pas un parfait prédicteur des sources citées dans un AI Overview: des études récentes montrent une forte volatilité et une sélection de sources parfois décorrélée du Top 3 SEO. Les travaux d’Authoritas (2024–2025) soulignent une rotation élevée des sources et des différences par intention de requête, détaillés dans leur recherche AI Overview sur l’intention et la volatilité (Authoritas).
- La présence d’un AI Overview peut redistribuer les clics. Ahrefs a observé en 2025 une baisse moyenne de 34,5% des clics pour les pages en position 1 lorsque l’Overview s’affiche; la position 1 passait d’environ 7,3% de CTR (mars 2024) à 2,6% (mars 2025) sur les requêtes concernées, selon AI Overviews Reduce Clicks by 34.5% (Ahrefs, 2025). Ce n’est pas un verdict universel, mais un signal: l’enjeu se déplace vers « être cité et choisi comme source ».
Conclusion opérationnelle: optimiser vos entités et vos preuves (schémas, sources, formats de réponses) vise à faciliter la sélection et la citation. Techniquement, c’est une stratégie de lisibilité sémantique et de désambiguïsation, plus qu’une « astuce » de positionnement.
3. Mettre en place une base solide (Entity Home, JSON‑LD, sameAs, @id)
Commencez par une « Entity Home » pour chaque entité prioritaire (marque, produit, personne porte‑parole). Cette page canonique consolide le nom, la description, les visuels, les coordonnées, et expose un JSON‑LD complet. Vous la reliez partout via un @id stable.
Exemple minimal pour une Organization (reprenez la structure du guide officiel Google):
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://www.exemple.com/#brand",
"name": "Exemple Société",
"url": "https://www.exemple.com",
"logo": "https://www.exemple.com/logo.png",
"sameAs": [
"https://www.wikidata.org/wiki/Q123456",
"https://www.linkedin.com/company/exemple",
"https://twitter.com/exemple"
],
"contactPoint": {
"@type": "ContactPoint",
"contactType": "customer support",
"telephone": "+33-1-23-45-67-89"
}
}
</script>
Pour un Product, reliez la marque et, si pertinent, un identifiant Wikidata pour lever les ambiguïtés:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Product",
"@id": "https://www.exemple.com/produits/montre-xyz#product",
"name": "Montre Connectée XYZ",
"image": "https://www.exemple.com/images/montre-xyz.jpg",
"description": "Montre connectée avec GPS et suivi cardiaque.",
"sku": "XYZ-12345",
"brand": {
"@type": "Brand",
"name": "ExempleBrand",
"sameAs": "https://www.wikidata.org/wiki/Q987654"
},
"offers": {
"@type": "Offer",
"url": "https://www.exemple.com/montre-xyz",
"priceCurrency": "EUR",
"price": "199.99",
"availability": "https://schema.org/InStock"
}
}
</script>
Bonnes pratiques utiles sur le terrain:
- Adoptez des
@idpersistants (ex./#brand,#product) pour stabiliser le graphe interne. - Déclarez des pages FAQ ou HowTo lorsque le format s’y prête vraiment; structurez vos contenus en questions/réponses avec une réponse courte en tête de section.
- Validez systématiquement vos schémas avec le Validator schema.org (outil officiel) et surveillez l’éligibilité via la Search Console et le Rich Results Test.
- Rappelez‑vous: les données structurées aident la compréhension et certaines fonctionnalités enrichies; Google ne garantit pas la citation dans un AI Overview.
4. Auditer et optimiser sur Google, Perplexity et les assistants LLM
Voici un workflow simple pour mesurer et améliorer votre « part de voix IA »:
-
Cadrage: listez vos entités (marque, produits, dirigeants), les requêtes cibles (informationnelles, commerciales), ainsi que 3–5 concurrents.
-
Collecte: exécutez les requêtes dans Google (Mode IA/AI Overviews), Perplexity et un assistant LLM grand public. Capturez les réponses, les sources citées et la tonalité.
-
Évaluation: notez présence/absence de l’entité, cohérence des attributs (nom, prix, fonctionnalités), nombre et position des citations, sentiment perçu. Comparez votre fréquence de citation à celle des concurrents pour estimer la part de voix.
-
Actions: comblez les lacunes (Entity Home, schémas, sameAs vers Wikidata/Wikipedia et profils officiels), renforcez les sections Q/R et les preuves d’expertise (études, résultats propriétaires), puis itérez tous les 30 jours.
Tableau de repères rapides sur les citations par plateforme:
| Plateforme | Affichage des citations | Particularités utiles à l’optimisation |
|---|---|---|
| Google AI Overviews | Liens d’appui (pas systématiques, variable selon requêtes) | Sélection parfois décorrélée du top organique; importance de la clarté sémantique et de la preuve (pages canoniques, formats Q/R). Voir le guide des fonctionnalités d’IA. |
| Perplexity | Citations numérotées systématiques | Structurez vos pages pour répondre directement; formats Article/FAQ/HowTo/Organization/Product bien renseignés. Voir How does Perplexity work? (Help Center). |
| Assistants LLM | Variable (peut ne pas afficher de sources) | La désambiguïsation via sameAs/@id et des contenus « répondables » augmente les chances d’être compris et mentionné même sans lien visible. |
Mini‑cas (logique) souvent observé: après création d’une Entity Home « Produit A », ajout d’un JSON‑LD complet, harmonisation des noms et ajout de sameAs vers Wikidata et les profils officiels, la cohérence des attributs dans Perplexity s’améliore et la fréquence de citations augmente sur 4–8 semaines. Ce n’est pas garanti, mais suffisamment répété pour en faire une habitude de base.
5. Outils et pilotage continu (avec Geneo)
Côté mise en œuvre, une pile légère suffit pour démarrer: un générateur/éditeur de schémas, un crawler (pour vérifier @id, hreflang, canonicals), Validator + Rich Results Test, et un tableur de suivi des requêtes IA.
Pour le monitoring multi‑plateformes, l’enjeu est de centraliser les requêtes testées, les réponses observées, les liens cités et le sentiment. C’est précisément le rôle de solutions dédiées comme Geneo: suivi des mentions et citations dans ChatGPT, Perplexity et Google AI Overviews, analyse de sentiment, historique des requêtes et recommandations de contenu pour combler les écarts. Vous pouvez découvrir la plateforme ici: Geneo – optimisation de la visibilité dans la recherche IA.
Checklist express (priorités sous 30 jours)
- Définir l’Entity Home de la marque et des 1–2 produits phares; publier un JSON‑LD propre, avec
@idstable etsameAspertinents. - Harmoniser les noms, logos, descriptions et profils officiels (site, LinkedIn, Wikidata/Wikipedia le cas échéant).
- Structurer 3–5 pages en vrais formats « répondables » (Q/R courtes en tête, sections HowTo si utile) et ajouter FAQPage là où c’est pertinent.
- Vérifier et valider tous les schémas (Validator schema.org; Rich Results Test) puis contrôler dans Search Console.
- Lancer un journal d’audit IA (Google, Perplexity, un LLM), mesurer citations et sentiment, et itérer toutes les 4 semaines.
FAQ express
Q: Qu’appelle‑t‑on « entité » en SEO/IA ?
R: Une chose unique (marque, produit, personne, lieu, concept) décrite par des attributs et reliée à d’autres choses dans un graphe de connaissances. Les systèmes IA s’appuient sur ces représentations pour comprendre et répondre.
Q: Pourquoi utiliser JSON‑LD ?
R: C’est le format conseillé par Google pour les données structurées; il est standardisé par le W3C (JSON‑LD 1.1) et facile à maintenir sans polluer le HTML.
Q: À quoi servent sameAs et @id ?
R: @id fixe un identifiant persistant pour l’entité; sameAs relie votre entité à des identifiants externes (Wikidata, profils officiels) pour lever les ambiguïtés d’homonymie.
Q: Une FAQ balisée garantit‑elle une citation en AI Overview ?
R: Non. Les schémas améliorent la compréhension et l’éligibilité à certaines fonctionnalités, mais la citation reste à la discrétion de l’algorithme. D’où l’importance de tester et d’itérer.
Q: Perplexity cite‑t‑il toujours ses sources ?
R: Oui, c’est un principe de la plateforme: des citations numérotées renvoient vers les documents d’origine, comme expliqué dans son centre d’aide.
Conclusion
Le nerf de la guerre n’est plus seulement « être premier »: c’est « être compris, choisi et cité ». L’optimisation des entités — Entity Home, JSON‑LD propre, @id persistants, sameAs vers des identifiants fiables — augmente votre lisibilité sémantique et vos chances d’apparaître dans les réponses génératives. Appuyez‑vous sur des preuves (pages répondables, études internes, données originales), validez vos schémas et mettez en place un pilotage continu des citations et du sentiment sur les différentes plateformes.
Envie de passer de la théorie à un pilote mesurable? Lancez un premier sprint de 30 jours, instrumentez vos entités, et suivez l’évolution des citations avec un tableau de bord dédié (ou une solution comme Geneo) — puis ajustez. Au fond, pourquoi attendre que les IA « devinent » qui vous êtes, si vous pouvez leur montrer clairement qui vous êtes et pourquoi vous méritez d’être cité ?



