
GEO et mentions IA : Cas pratique et workflow de référence 2025
Étude de cas : booster les mentions IA grâce au GEO en 2025. KPIs, roadmap auditable, outils de suivi, conformité. Pour responsables marketing et SEO avancé.

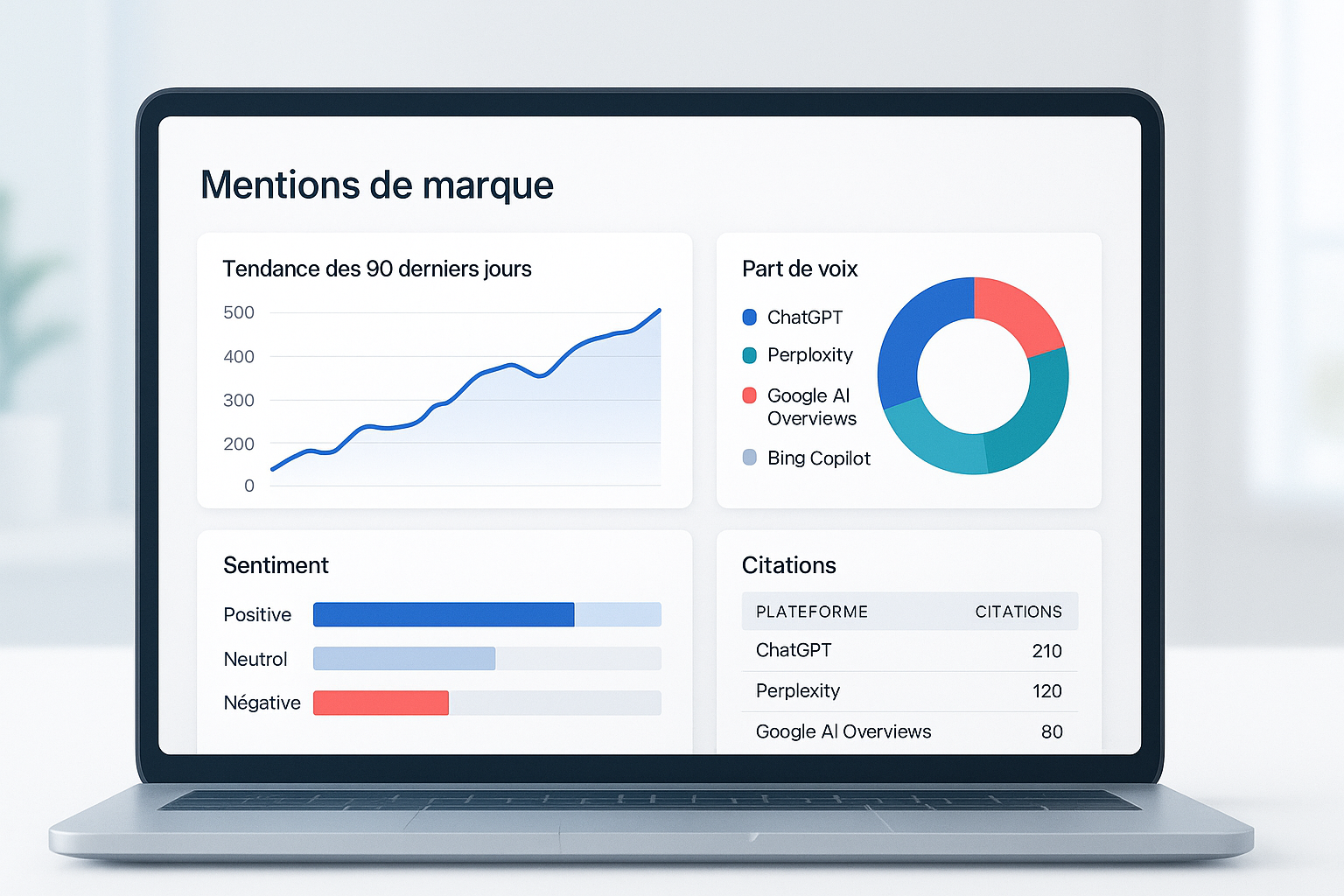
La promesse d’un « +300 % » fait rêver. Elle fait aussi lever un sourcil. À ce jour, aucun cas public francophone ne documente rigoureusement un tel bond des mentions de marque dans les réponses d’IA. Plutôt que de broder, voici un playbook réaliste pour se donner les moyens d’approcher ce type d’uplift, en mesurant proprement chaque étape et en acceptant les limites d’un terrain qui bouge vite.
GEO en 2025 : pourquoi c’est déterminant pour votre visibilité
Le Generative Engine Optimization (GEO) consiste à rendre vos contenus « citables » par les moteurs génératifs (ChatGPT, Perplexity, Google AI Overviews, Bing Copilot). L’enjeu n’est plus seulement le clic, mais la mention, la qualité de la citation et la part de voix dans des réponses souvent zéro‑clic. SEO et GEO se complètent : l’autorité et la propreté technique héritées du SEO restent la base, tandis que le GEO travaille la clarté, la neutralité, la preuve et les formats appréciés par les LLM.
Pour cadrer les fondamentaux de la visibilité IA (définition, mesures et enjeux), voyez la ressource de référence « visibilité IA » publiée par Geneo en 2025 : Qu’est‑ce que la visibilité IA ? Exposition de marque dans la recherche IA.
La colonne vertébrale de la mesure
Sans métriques reproductibles, impossible de parler de progression. Ci‑dessous, une grille resserrée de KPIs et leur utilité. Ajoutez une journalisation stricte de vos tests (prompt exact, modèle, date/heure, langue, pays) et une annotation humaine du sentiment sur un échantillon.
| KPI | Définition | Pourquoi ça compte |
|---|---|---|
| Taux de citation IA | % de requêtes du panel où la marque est citée | Indicateur direct de présence dans les réponses |
| Volume de mentions | Nombre total de mentions observées sur une période | Donne l’ampleur absolue de votre exposition |
| Part de voix IA | Part des citations obtenues vs concurrents | Mesure votre avance ou retard sur le marché |
| Position/poids | Rôle de la source (primaire/secondaire) et emplacement | Influence la visibilité réelle dans le bloc |
| Fidélité de citation | Degré d’exactitude et de contexte | Évite les déformations nuisibles à la marque |
| Sentiment | Tonalité positive/neutre/négative | Oriente les actions de réputation |
| Fraîcheur | Mise à jour des données citées | Les LLM préfèrent des sources récentes |
| Couverture de sources | Diversité des domaines qui vous citent | Renforce crédibilité et découvrabilité |
Protocole d’annotation du sentiment (résumé) : deux annotateurs minimum, guide commun et contrôle d’accord (ex. Kappa de Cohen). Les meilleures pratiques francophones insistent aussi sur des cycles d’audit réguliers et sur la traçabilité des prompts, comme le détaille Natural Net dans son guide 2025 sur la mesure de la visibilité IA (audit visibilité et suivi des réponses LLM, 2025).
Un workflow reproductible sur 60–90 jours
Étape 1 — Cadrage et panel de requêtes. Alignez objectifs (ex. part de voix IA, taux de citation par persona) et sélectionnez 80–150 requêtes représentatives (informationnelles, commerciales, « qui recommanderais‑tu… ? », FR/EN si pertinent). Constituez la baseline T0 sur 3–4 plateformes.
Étape 2 — Diagnostic « citabilité » du contenu. Évaluez clarté, neutralité, preuves, structure (Hn, définitions, FAQ, HowTo), profondeur et fraîcheur. Repérez les pages trop promotionnelles ou ambiguës.
Étape 3 — Signaux E‑E‑A‑T et preuves. Renforcez l’expertise visible : auteurs identifiés, bios, références datées et fiables, études, avis vérifiés. Plus vos preuves sont denses et sourcées, plus vous serez repris.
Étape 4 — Actions contenu IA‑friendly. Réécrivez en formats digestes pour LLM : définitions nettes, listes numérotées quand elles facilitent la citation, Q/R, tableaux comparatifs, résumés exécutifs. Travaillez un glossaire et des pages « fondamentaux » sectorielles.
Étape 5 — Actions techniques. Schema.org (FAQPage, HowTo, Article), maillage interne vers les pages d’autorité, performance, indexabilité, et journal de mises à jour. Documentez vos politiques éditoriales.
Étape 6 — Prompts de test et panels. Créez des prompts standardisés et des variantes. Cadence de test hebdomadaire au départ, puis mensuelle. Tenez un log exact (prompt, modèle, paramétrage, horodatage).
Étape 7 — Mesure & annotation. Suivez mentions, position/poids, fidélité, sentiment. Standardisez l’annotation et auditez l’accord entre évaluateurs pour fiabiliser la série temporelle.
Étape 8 — Itérations et gouvernance. Boucles mensuelles sur les pages prioritaires. Un comité GEO consolide la tendance, observe les concurrents, arbitre les priorités et alimente la roadmap.
Mini‑cas anonymisé (cadre expérimental)
Hypothèses de départ. Panel de 120 requêtes FR réparties sur 4 plateformes (ChatGPT navigation, Perplexity, Google AI Overviews, Copilot). Baseline T0 sur 14 jours. Objectifs : +X points sur le taux de citation, amélioration de la fidélité et du sentiment, hausse de la diversité des sources.
Plan d’action. Réécriture de 12 pages « fondamentaux », ajout de 2 comparatifs neutres, enrichissement des preuves (données datées, sources académiques/médias reconnus), schémas FAQ/HowTo, signatures d’auteurs avec bios. Maillage interne renforcé vers 6 pages d’autorité.
Observations qualitatives à T+90. Hausse nette du taux de citation sur requêtes informationnelles, mentions plus visibles (sources primaires citées plus haut), sentiment amélioré sur les pages réécrites. Les requêtes « recommandation » progressent moins vite et restent très sensibles à la formulation du prompt. Conclusion pratique : l’« uplift » existe, mais varie selon les familles de requêtes et les plateformes. Sans journalisation et panel stable, toute comparaison serait trompeuse.
Outils et monitoring (avec un exemple illustratif)
Le marché 2025 propose plusieurs approches de suivi (panel de prompts, scraping contrôlé, APIs, annotations). Chaque solution a ses limites (coûts, couverture des LLM/langues, courte profondeur historique). Pour un panorama français et des mises en garde méthodologiques, voir l’examen des outils de suivi LLM publié fin 2025 (panorama d’outils de monitoring LLM, Tool‑Advisor 2025). Côté pratiques de référencement sur les IA, SE Ranking partage aussi des protocoles utiles pour ChatGPT et les AIO (guide de référencement sur ChatGPT, SE Ranking 2025).
Exemple illustratif (Disclosure : Geneo est notre produit). Dans un audit type, Geneo consolide un panel de requêtes FR par persona, exécute des tests périodiques sur ChatGPT/Perplexity/AIO/Copilot, enregistre prompts et modèles, et agrège des KPIs : taux de citation, part de voix IA, position, fidélité, sentiment. Le tableau de bord met en évidence les tendances mensuelles et les écarts vs concurrents, pour piloter la roadmap contenu sans surestimer un résultat ponctuel.
Gouvernance, conformité et dynamique des plateformes
Les plateformes évoluent en continu, et votre plan doit suivre. Côté Google AI Overviews, des analyses 2025 indiquent que la majorité des citations proviennent des pages déjà bien classées en organique, ce qui renforce l’importance du socle SEO. Ahrefs a synthétisé points d’apparition, fonctionnement et leviers utiles dans son guide 2025 (analyse AI Overviews par Ahrefs, 2025). De plus, plusieurs études de marché ont observé une baisse du CTR organique sur des requêtes informationnelles lors de l’affichage d’Overviews ; Search Engine Land en a documenté l’impact et les implications stratégiques en 2025 (impact d’AI Overviews sur le CTR, Search Engine Land 2025).
Côté conformité, tenez un registre des données collectées (réponses IA et annotations), précisez vos finalités, limitez la conservation, et encadrez l’accès. Sur le site, affichez auteurs, bios, dates de mise à jour, sources externes, disclaimers quand nécessaire. Ces signaux éditoriaux servent à la fois vos utilisateurs et votre « citabilité ».
Plan d’action 30‑60‑90 jours
-
30 jours — Cadrer et mesurer. Sélectionner le panel de requêtes et exécuter la baseline; auditer « citabilité » (contenu, preuves, schémas, auteurs); lancer 3–5 quick wins rédactionnels; mettre en place le journal de prompts et l’annotation du sentiment.
-
60 jours — Produire et relier. Réécrire/structurer les pages « fondamentaux » et 1 comparatif; ajouter FAQ/HowTo et bios; renforcer le maillage interne; obtenir 2–3 références externes fiables (associations, médias spécialisés) pour soutenir vos faits.
-
90 jours — Boucler et arbitrer. Rejouer le panel, comparer T0 vs T+90; analyser citations/position/fidélité/sentiment; ajuster la roadmap contenu; consolider un comité GEO mensuel et étendre le panel à d’autres personas.
Ce qu’il faut retenir
Le « +300 % » ne doit ni vous hypnotiser ni vous décourager. Ce qui compte, c’est une démarche stable : un panel de requêtes bien défini, des contenus citables et sourcés, une mesure transparente et des itérations disciplinées. Les plateformes privilégient les sources fiables et récentes ; votre mission est de construire cette fiabilité, de la rendre visible, puis de la vérifier dans les réponses d’IA. Prêt à lancer un pilote mesuré et actionnable ?



