
Corroboration des entités web par l’IA : explications clés
Découvrez comment l’IA recoupe les entités web, du NER aux Knowledge Graphs. Optimisez la citabilité et la visibilité de votre marque dans les moteurs IA.

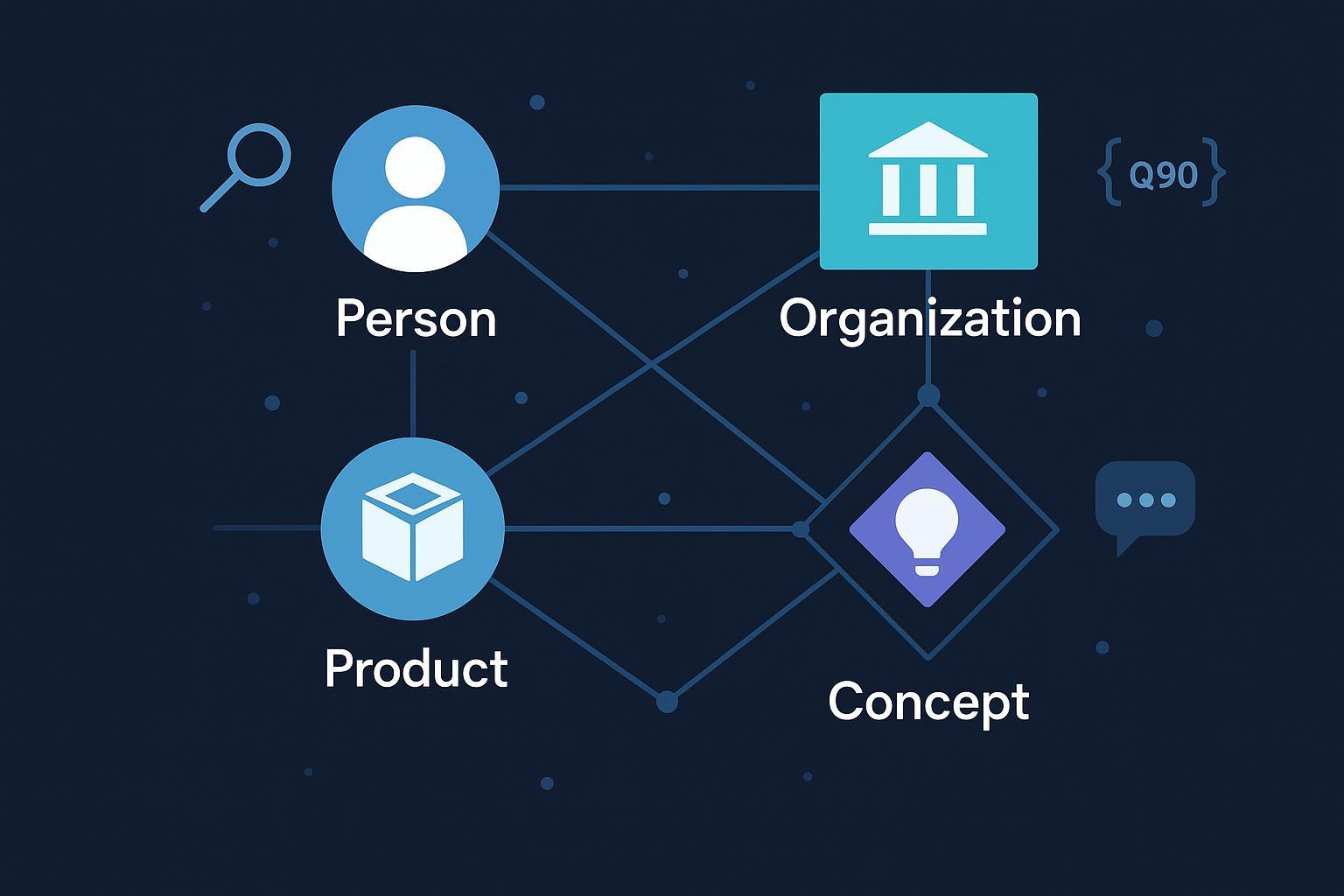
Votre marque est‑elle reconnue comme une entité, vérifiée et citée par les assistants IA et les moteurs génératifs ? Si la réponse hésite, c’est que la « corroboration des entités web par l’IA » vous concerne directement: il s’agit de la capacité des systèmes à identifier correctement une entité (personne, organisation, produit, concept), à la relier à des sources et à l’appuyer par des preuves fiables.
1) Qu’est‑ce qu’une entité web et pourquoi elle compte
Une entité web est une « chose » que les moteurs et assistants peuvent reconnaître de façon unique, indépendamment des mots‑clés: une personne, une organisation, un produit ou un concept avec des attributs précis et des relations. Plutôt que de faire correspondre des chaînes de caractères, les systèmes cherchent à comprendre « qui » ou « quoi » repose derrière une mention (« Apple » le fruit vs « Apple Inc. » l’entreprise). Le Knowledge Graph de Google agrège des milliards d’entités et leurs relations, nourri par des sources comme Wikipédia/Wikidata et les données structurées publiées par les sites, afin d’améliorer la pertinence sémantique et l’affichage (panneaux de connaissance, résultats enrichis). Pour une vue francophone synthétique du Knowledge Graph et de son rôle, voir la définition du Knowledge Graph par Abondance.
En SEO et en GEO (Generative Engine Optimization), être une entité « bien formée » augmente la probabilité de citations dans les réponses IA et de liens visibles, parce que la machine peut vous identifier sans ambiguïité et retrouver des preuves externes fiables.
2) La chaîne technique: NER → entity linking → ancrage au graphe
La corroboration commence par une chaîne de traitement bien connue:
- Reconnaissance d’entités nommées (NER): détecter et typer les mentions (Person, Organization, Product, etc.).
- Entity linking/désambiguïsation: relier chaque mention à l’entité correcte d’une base de connaissances (p. ex. Wikidata), ou signaler qu’aucune correspondance fiable n’existe.
- Ancrage au graphe: utiliser des identifiants stables (Q‑ID Wikidata, URI) et des relations sémantiques pour consolider les informations multi‑sources.
Pensez‑y comme à un contrôle d’identité: repérer la personne dans la foule (NER), valider son dossier exact (linking), puis l’inscrire au registre officiel (graphe) avec un numéro unique.
| Étape | Entrées | Sorties | Risques courants |
|---|---|---|---|
| NER | Texte brut, requêtes | Mentions typées (Person, Org…) | Ambiguïté, faux positifs |
| Linking | Mentions, candidats d’entités | Identifiant unique (ex. Q90 pour Paris) | Mauvais appariement, entité absente |
| Ancrage | Identifiant, relations | Graphe enrichi (propriétés, sameAs) | Incohérences, doublons |
Wikidata fournit une structure claire (items Q‑ID, propriétés P‑ID, déclarations) qui aide la désambiguïsation et l’ancrage; voir la page Wikidata sur les outils de visualisation pour comprendre la nature graphe et les identifiants.
3) Données structurées et identifiants: schema.org/JSON‑LD, sameAs, NAP
Les moteurs recommandent de publier des données structurées en JSON‑LD (schema.org) pour décrire vos entités: Organization, Person, Product, avec des attributs normalisés (nom, logo, URL, description, etc.). La propriété sameAs relie votre entité à des profils faisant autorité (Wikipedia, réseaux sociaux vérifiés, registres officiels), ce qui renforce la corroboration. Pour les entités locales, la cohérence NAP (Name, Address, Phone) sur le site et l’écosystème (annuaires, fiches) est essentielle.
Google détaille ces pratiques dans la documentation Structured data pour Organization (FR) et dans ses pages d’exemples (recettes, fiches marchands). Ces balises aident l’indexation sémantique, la désambiguïsation et l’apparition d’extraits enrichis — et, côté IA, facilitent l’extraction de « preuves » lorsque un assistant recoupe votre entité avec des sources publiquement vérifiables.
4) Côté LLM: RAG, recherche vectorielle, reranking et post‑vérification
Les assistants modernes utilisent des pipelines de Retrieval‑Augmented Generation (RAG) pour fonder les réponses sur des preuves. En bref: la recherche vectorielle dense (embeddings) récupère des passages pertinents; des cross‑encoders et des techniques de reranking affinent la pertinence des documents; une post‑vérification (grounding) confronte les assertions générées aux sources retenues pour réduire les hallucinations.
Pour un aperçu technique récent, Cohere explique l’architecture RAG (2025). Des travaux 2025 sur l’« agentic RAG » détaillent des boucles d’itérations et de vérification plus poussées (planification, contrôle de sources), utiles quand la réponse doit citer et valider des entités.
5) Citations et corroboration dans les assistants IA
Les plateformes n’ont pas toutes la même politique de citation visible:
- Perplexity affiche des liens cliquables vers les sources consultées et expose des métadonnées de provenance dans ses interfaces et API. Pour le fonctionnement utilisateur, voir « Commencer à utiliser Perplexity » (Help Center FR).
- Google AI Overviews fournit un aperçu synthétique avec des liens vers des pages sources, mais la granularité de la sélection des passages n’est pas documentée publiquement de manière exhaustive. Les annonces officielles (2024–2025) décrivent l’expérience utilisateur et l’expansion des Overviews; voir le billet « AI Mode & expansion des AI Overviews » (Google, 2025).
Conséquence pratique: les citations visibles varient selon la plateforme et la requête. Pour être cité, votre entité doit laisser des traces claires et « saisissables »: balisage, pages preuves, identifiants, et une présence sur des sites de confiance.
6) Bonnes pratiques GEO pour rendre une entité « vérifiable »
Voici une checklist condensée, issue des tendances 2024–2025:
- Structurer vos pages « entité » avec JSON‑LD (Organization/Person/Product), renseigner sameAs et des identifiants officiels.
- Créer des pages preuves: méthodologies, études, FAQ, statistiques avec sources datées et liens sortants vers des référentiels reconnus.
- Obtenir des mentions et backlinks depuis des sites à forte autorité éditoriale; privilégier des pages contextuelles (interviews, études, annuaires vérifiés).
- Soigner la cohérence NAP et les profils publics (Wikipedia/Wikidata lorsque pertinent), avec des informations stables et sourcées.
- Écrire pour des intentions conversationnelles (FAQ, how‑to) qui se mappent bien aux assistants.
- Rendre le contenu facilement extractible: titres clairs, tableaux de données, paragraphes courts contenant les chiffres et les définitions.
Pour une mise en perspective, voir les analyses FR sur GEO, notamment le guide Generative Engine Optimization de Datashake.
7) Mini‑workflow pour tester et améliorer la corroboration
Un cycle simple et reproductible:
- Préparer l’entité
- Créez/affinez une fiche Wikidata (Q‑ID), typée (P31 « instance de »), reliée au site officiel et à des profils vérifiés.
- Implémentez schema.org/JSON‑LD (Organization/Person/Product) avec sameAs, identifiants officiels et pages « About/Press ».
- Tester la citabilité
- Interrogez Perplexity (Web) sur vos requêtes cibles et notez les sources citées; votre site apparaît‑il ? Quelles pages « preuve » sont reprises ?
- Observez des AI Overviews sur vos marchés où la fonctionnalité est active et relevez les liens visibles.
- Diagnostiquer et corriger
- Si les citations sont rares, renforcez le balisage, clarifiez les pages preuves (méthodologie, chiffres), et développez l’écosystème de mentions/backlinks.
- Itérer
- Répétez toutes les 2–4 semaines et suivez les variations de citations et de présence.
Divulgation: Geneo est notre produit. Dans ce type de workflow, un outil de suivi multi‑plateformes comme Geneo peut être utilisé pour consigner, par requête et par assistant (Perplexity, AI Overviews, etc.), les mentions et liens visibles au fil du temps, afin de faciliter l’audit et la comparaison historique. Mention neutre, sans impact promis.
8) Limites, risques et sécurité
La corroboration n’est pas parfaite. Trois points méritent une vigilance continue:
- Biais et opacité: la sélection des sources et des liens affichés peut varier, sans transparence complète sur les critères. Certaines requêtes « zéro‑clic » réduisent la visibilité des sites même cités.
- Sécurité (prompt injection): les systèmes RAG/agents sont exposés à des entrées malveillantes qui tentent de détourner les comportements. L’OWASP GenAI détaille le risque LLM01 Prompt Injection et les contre‑mesures (validation des inputs, filtrage, supervision humaine, red teaming).
- Qualité des preuves: une entité mal balisée ou des pages non sourcées conduisent à des citations inexistantes ou fragiles; renforcer la qualité éditoriale et la traçabilité.
9) Mesurer la fiabilité (groundedness) en pratique
La question qui compte est simple: vos réponses IA reposent‑elles réellement sur des preuves retrouvées ? En pratique, on mesure d’abord la couverture des preuves (quelle part des affirmations renvoient à des passages récupérés), puis la pertinence de ces passages via des scores de similarité et de reranking; enfin, les assertions sensibles sont relues manuellement ou vérifiées par des tests d’entailment. Des articles récents décrivent ces boucles de validation dans les pipelines RAG et leurs extensions, notamment l’article de Cohere sur l’architecture RAG (2025).
Conclusion
Pour que l’IA recoupe correctement votre entité, rendez‑la identifiable, reliée et prouvée. En pratique: ancrez‑la (Wikidata, schema.org), publiez des pages preuves, obtenez des mentions d’autorité, testez la citabilité dans Perplexity et AI Overviews, puis itérez avec un suivi régulier. C’est un travail de fond, mais il paye en fiabilité et en visibilité — et il vous évite des surprises lorsque les assistants « compressent » le web en quelques liens.



