Comment mesurer le sentiment dans les réponses IA (2025) : guide complet
Guide pas à pas 2025 pour mesurer le sentiment dans les réponses AI (ChatGPT, Perplexity, Google). Méthodes, outils, pièges, validation humaine, alertes.

Vous allez mettre en place, pas à pas, une méthode fiable pour mesurer le sentiment dans des réponses produites par des assistants IA (ChatGPT, Perplexity, Google AI Overviews) et transformer ces signaux en actions concrètes pour votre marque.
- Temps et difficulté: 60–90 minutes pour un MVP; 1–3 semaines pour un déploiement « production ».
- Prérequis: accès API (selon le parcours choisi), tableur ou entrepôt de données léger, outil de visualisation (ou plateforme dédiée), disponibilité de 1–2 réviseurs humains pour la QA.
- Résultat: des tableaux de bord de sentiment par requête et par assistant, des alertes quand le ton bascule, et une boucle d’amélioration qui réduit durablement les réponses négatives ou trompeuses.
Pourquoi cette méthode fonctionne: elle combine collecte multi‑plateformes, modèles de sentiment fiables, validation humaine régulière, tests d’ironie/sarcasme, et alertes actionnables. Elle respecte aussi les politiques d’usage des plateformes (notamment l’absence d’API publique pour AI Overviews) et la conformité RGPD.
Vue d’ensemble du pipeline
- Collecter des réponses IA (APIs/exports; respect ToS) → 2) Étiqueter et calibrer sur un échantillon (double annotation, kappa) → 3) Choisir un moteur de sentiment (open source, cloud, LLM‑as‑judge) → 4) Valider et ajuster (précision/rappel/F1, tests d’ironie) → 5) Opérationnaliser (dashboards, alertes, boucle d’amélioration contenu/prompt).
Astuce: si vous avez besoin d’un accélérateur prêt à l’emploi pour les assistants majeurs et la surveillance de marque, vous pouvez utiliser Geneo en option aux étapes 1, 3 et 5.
Étape 1 — Collectez des réponses IA (en respectant les règles)
-
ChatGPT (OpenAI)
- Collecte par API: utilisez l’API Chat Completions ou la plus récente Responses API. Voir la documentation 2025 d’OpenAI pour la liste des endpoints et la migration vers Responses dans le guide « Migrer vers la Responses API (OpenAI, 2025) ». Pour les modèles disponibles et capacités, référez-vous à « Docs modèles et endpoints (OpenAI, 2025) ».
- Collecte par interface: possible au cas par cas via l’export de données du compte; pour du monitoring continu, privilégiez l’API et journalisez vos échanges côté client (JSON).
-
Perplexity
- Automatisez avec l’API officielle décrite dans les « Docs développeur Perplexity (2025) ». Respectez les « Conditions d’utilisation Perplexity (2025) » et quotas de l’API.
-
Google AI Overviews (synthèses IA dans la recherche)
- Il n’existe pas d’API publique en 2025. Google encadre strictement l’automatisation et le scraping. Conformez-vous aux « Search Spam Policies (Google, 2024–2025) » et respectez les règles « Crawlers & robots.txt (Google) ».
- Recommandation: ne pas scraper à grande échelle; constituez un échantillon manuel raisonnable ou passez par un outil qui respecte robots.txt et ToS.
-
Données et conformité
- Nettoyez et normalisez le texte (Unicode NFC/NFKC). Pour la segmentation FR/EN, appuyez-vous sur spaCy (voir les pages modèles FR et EN sur spacy.io).
- Si des PII sont présentes, suivez les recommandations 2025 de la CNIL sur l’IA et le RGPD, notamment l’anonymisation/pseudonymisation et la minimisation des données, détaillées dans les « Recommandations CNIL pour respecter le RGPD (2025) ».
- Pour anonymiser, Microsoft Presidio offre détection et masquage de PII, configurable pour le français, voir « Microsoft Presidio (GitHub) ».
Option accélérée avec Geneo: Geneo centralise la collecte et l’historique de réponses générées par l’IA pour vos requêtes de marque sur ChatGPT, Perplexity et AI Overviews, avec suivi des mentions et liens. Pratique si vous voulez monitorer sans coder.
Étape 2 — Étiquetez et calibrez (QA humaine indispensable)
- Construisez un échantillon représentatif (au moins 100–300 réponses par canal au départ). Stratifiez par requête (ex. « avis [marque] », « alternatives à [produit] », etc.) et par langue.
- Double annotation humaine: chaque réponse étiquetée Positive/Neutre/Négative par 2 personnes. Mesurez l’accord inter‑annotateurs (kappa de Cohen). En contexte critique, ciblez ≥0,7–0,8. Voir un rappel méthodologique dans les « lignes directrices d’annotation – ACL Anthology (2025) ».
- Définissez des critères concrets:
- Négatif: reproches explicites, recommandations contre votre marque, mise en garde forte.
- Neutre: comparaison factuelle sans jugement, ton informatif.
- Positif: recommandation, satisfaction, preuves favorables.
- Constituez un sous‑jeu « difficiles »: ironie, sarcasme, double négation, neutralité polie, ambiguïtés. Gardez-le pour les tests réguliers.
Astuce pratique: documentez 5–10 exemples par classe et par langue pour guider les futurs annotateurs.
Étape 3 — Choisissez votre moteur de sentiment
Vous avez trois familles d’options. Commencez simple, mesurez, puis complexifiez si nécessaire.
- Baselines lexicon/règles (prototypage rapide)
- VADER/TextBlob: utiles pour démarrer, surtout en anglais et textes courts. Limites en multilingue et sur l’ironie.
- Transformers multilingues (équilibre précision/effort)
- Modèles prêts à l’emploi sur Hugging Face:
- « twitter-xlm-roberta-base-sentiment (CardiffNLP) » pour un multilingue robuste.
- « bert-base-multilingual-uncased-sentiment (nlptown) » (1–5 étoiles; mappez vers Pos/Neu/Neg).
- Pour le français, essayez « distilcamembert-base-sentiment (cmarkea) ».
- Services cloud managés (scalabilité et simplicité)
- Google Cloud Natural Language: voir « Client libraries – Sentiment (Google Cloud) » et l’API « analyzeSentiment REST ».
- Azure AI Language – Text Analytics: guide « Appeler l’API Sentiment/Opinion Mining (Microsoft Learn) ».
- AWS Comprehend: documentation « How sentiment analysis works (AWS Comprehend) ».
- LLM‑as‑judge (évaluation via LLM)
- Pour capturer des nuances (ironie, contexte), vous pouvez demander à un LLM de juger le sentiment avec un prompt standardisé. Industrialisez avec « OpenAI Evals (repo officiel) », « Promptfoo – tests de prompts & CI » et « TruLens – évaluation LLM ».
Option accélérée avec Geneo: Geneo calcule automatiquement un score de sentiment sur les réponses IA collectées, agrège par requête/assistant et expose des tendances. Vous pouvez l’utiliser comme mesure principale ou comme ligne de base à confronter à vos propres modèles.
Étape 4 — Validez et ajustez (ne sautez pas cette étape)
- Mesurez vos métriques de classification: précision, rappel et F1 par classe, plus une matrice de confusion pour comprendre les erreurs. Pour un rappel des définitions et écueils, consultez « Classification metrics – Evidently AI (2025) ».
- Testez sur les « difficiles »: calculez F1 spécifique pour ironie, sarcasme, double négation. Si ces scores chutent, envisagez LLM‑as‑judge ou un modèle FR spécialisé.
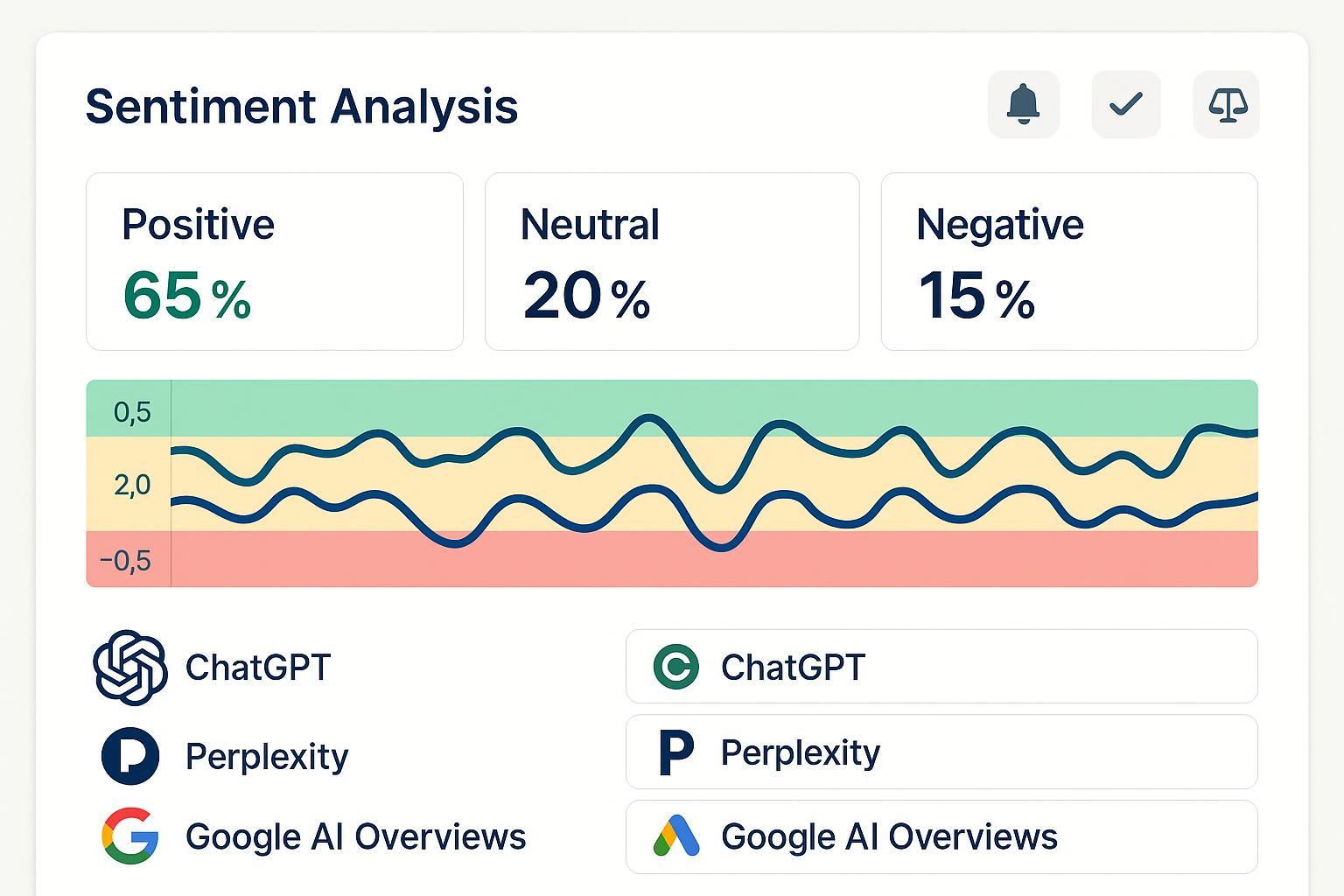
- Calibrez vos seuils d’alerte selon l’usage. Exemple de départ (à adapter):
- Score continu ∈ [−1, +1] ou probas par classe.
- Alerte soft: moyenne mobile sur 7 jours < −0,30.
- Alerte forte: moyenne mobile < −0,60 ou part de « Négatif » > 35% sur 24–48 h.
- Vérifiez la corrélation métier: comparez vos scores au CSAT/NPS ou aux tickets support. Si corrélation faible, revoyez vos définitions de labels ou segmentez par intention de requête.
Conseil: gérez le drift. Surveillez la distribution des entrées (types de requêtes) et des sorties (répartition Pos/Neu/Neg) au fil du temps. Des outils comme Evidently peuvent détecter des dérives via des tests statistiques (KS, PSI).
Étape 5 — Opérationnalisez (dashboards, alertes, amélioration continue)
- Tableaux de bord
- Grafana: créez une vue par assistant/requête et une tendance temporelle. Les bonnes pratiques d’alerting centralisé présentées par Grafana en 2025 peuvent inspirer votre setup, voir « Alerting centralisé – billet Grafana (2025) ».
- Power BI: vous pouvez configurer des alertes sur des indicateurs du tableau de bord, cf. « Alertes de données dans Power BI Service (Microsoft Learn) ».
- Alertes & intégrations
- Slack: envoyez des messages via « Incoming Webhooks (Slack API) » ou l’API « chat.postMessage ».
- Jira: créez automatiquement des tickets via la « Jira REST API – exemples (Atlassian) ».
- Email: utilisez SMTP Microsoft 365 si besoin, voir « Configurer l’envoi SMTP avec Microsoft 365 (Microsoft Learn) ».
- Boucle d’amélioration
- Côté contenu: créez/optimisez FAQ, pages comparatives, politiques de retour/garantie.
- Côté prompts/assistant: testez des versions de prompts, ton rédactionnel, politiques de refus, via A/B. Outillage: « Promptfoo – tests A/B et CI » ou « OpenAI Evals ».
Option accélérée avec Geneo:
- Scoring & dashboard: suivez le sentiment par requête/assistant et les tendances historiques sans bâtir d’infrastructure.
- Alertes: fixez des seuils et recevez des notifications par email ou Slack.
- Amélioration: exploitez les recommandations de contenu de Geneo pour attaquer les causes profondes des réponses négatives (lacunes d’information, messages datés, preuves insuffisantes).
Parcours « starter en 60 minutes »
- Collecte: 20 min
- Exportez 30–50 réponses par assistant (manuellement pour AI Overviews; API pour ChatGPT/Perplexity si possible). Anonymisez avec Presidio si besoin.
- Scoring: 15 min
- Chargez un modèle HF (p. ex. XLM‑RoBERTa sentiment) et scorez vos textes.
- Validation rapide: 15 min
- Étiquetez manuellement 50 réponses (double regard si possible) et calculez une F1 globale approximative + vérifiez 10 cas d’ironie.
- Dashboard & alertes: 10 min
- Un tableur ou un mini-dashboard (Power BI) suffit pour visualiser; ajoutez une règle d’alerte simple.
Alternative sans code: faites la même chose dans Geneo en connectant vos requêtes de marque et en activant les alertes.
Parcours « production » (équipe)
- Collecte et historisation (API + stockage; conformité RGPD; supervision des quotas)
- Annotation continue (lot hebdo de 100 réponses, double annotation, kappa ≥0,7)
- Modèle hybride (transformer multilingue + LLM‑as‑judge sur les cas ambigus)
- QA mensuelle (tests d’ironie, drift, recalibration des seuils)
- Dashboards par segment (requête, langue, assistant) et alertes multicanales (Slack/Jira/Email)
- Boucle d’amélioration coordonnée avec SEO/Content/Support; A/B des prompts et suivi CSAT/NPS.
Pièges courants et comment les éviter
- Faux neutres: réponses polies mais défavorables (« nous ne recommandons pas… »). Solution: exemples de guidelines + LLM‑as‑judge.
- Ironie/sarcasme: sous‑jeu dédié et seuils distincts; privilégier un juge LLM pour arbitrer.
- Biais de langue: un modèle EN peut sous‑performer en FR; utilisez des modèles FR ou multilingues adaptés.
- Désalignement métier: un score « Négatif » global peut masquer qu’une requête « alternatives à [produit] » est structurellement plus négative. Segmentez par intention.
- Collecte AI Overviews: pas d’API publique; évitez l’automatisation agressive et respectez robots.txt & politiques.
- Sur‑dépendance au LLM juge: gardez un échantillon de QA humaine et comparez périodiquement.
Checklists prêtes à l’emploi
-
Collecte
- [ ] ToS/robots.txt vérifiés pour chaque source
- [ ] PII supprimées/anonymisées (Presidio)
- [ ] Normalisation Unicode + segmentation FR/EN
- [ ] Journalisation des métadonnées (assistant, requête, date, langue)
-
Annotation & QA
- [ ] Guide d’annotation avec exemples Pos/Neu/Neg
- [ ] Double annotation + kappa calculé
- [ ] Sous‑jeu « difficiles » (ironie, double négation)
-
Modèle & validation
- [ ] Métriques par classe (précision/rappel/F1)
- [ ] Tests dédiés « difficiles »
- [ ] Seuils d’alerte définis et documentés
-
Opérationnalisation
- [ ] Dashboard par assistant/requête/temps
- [ ] Alertes Slack/Jira/Email configurées
- [ ] Revue hebdo + actions contenu/prompt planifiées
Comment vérifier que « ça marche »
- Chaque semaine: spot‑check humain de 30 échantillons (≥80% d’accord avec le système).
- Distribution stable: la part de Pos/Neu/Neg ne doit pas dériver sans cause identifiée.
- Edge cases: F1 sur le sous‑jeu « difficiles » ne doit pas chuter (>−10% vs baseline).
- Impact métier: baisse des alertes fortes sur 4–8 semaines et meilleure corrélation avec CSAT/NPS.
Foire aux questions (troubleshooting)
- Mes scores varient d’une langue à l’autre.
- Vérifiez la langue détectée, utilisez un modèle multilingue robuste ou spécifique FR, et réentraînez vos seuils par langue.
- Trop d’alertes lors d’un lancement produit.
- Passez en « mode événement »: augmentez la fenêtre de lissage (7→14 jours) et élevez temporairement le seuil d’alerte forte.
- Mon modèle rate l’ironie.
- Ajoutez un LLM‑as‑judge sur les réponses incertaines (p. ex. quand l’entropie/proba max < seuil) et renforcez le sous‑jeu d’entraînement/validation.
- Sentiment négatif mais CSAT stable.
- Re-segmentez par intention de requête, vérifiez la part de comparatifs. Ajustez la pondération des requêtes à risque.
Intégrer Geneo à votre workflow (option recommandé pour équipes marketing/SEO)
- Monitoring multi‑assistants: suivez vos requêtes de marque sur ChatGPT, Perplexity et AI Overviews sans scripting.
- Sentiment prêt à l’emploi: visualisez le ton par requête/assistant, détectez les bascules, comparez dans le temps.
- Alertes et exports: configurez des seuils, recevez des notif Slack/Email, exportez en CSV/API pour vos outils.
- Actions guidées: exploitez les recommandations de contenu pour corriger les réponses négatives à la source.
Essayez Geneo: https://geneo.app
Sources citées (sélection)
- OpenAI — « Migrer vers la Responses API (2025) »; « Docs modèles/endpoints (2025) »
- Perplexity — « Docs développeur (2025) »; « Conditions d’utilisation (2025) »
- Google — « Search Spam Policies (2024–2025) »; « Crawlers & robots.txt »
- CNIL — « Recommandations IA & RGPD (2025) »
- Microsoft — « Presidio (GitHub) »
- Hugging Face — « XLM‑RoBERTa sentiment (CardiffNLP) »; « BERT multilingual sentiment (nlptown) »; « distilcamembert FR sentiment »
- Cloud — « Google Cloud NL – Sentiment »; « Azure Language – Sentiment API »; « AWS Comprehend – Sentiment »
- Évaluation — « Evals (OpenAI) »; « Promptfoo – Docs »; « TruLens – Docs »; « Classification metrics (Evidently AI, 2025) »
- Dashboards & alertes — « Alerting centralisé (Grafana, 2025) »; « Alertes de données – Power BI »