
Comment construire un système de monitoring GEO : étapes clés
Découvrez comment mettre en place un système de monitoring GEO efficace : étapes détaillées, exemples pratiques, code, tableaux et vérification. Tutoriel complet.

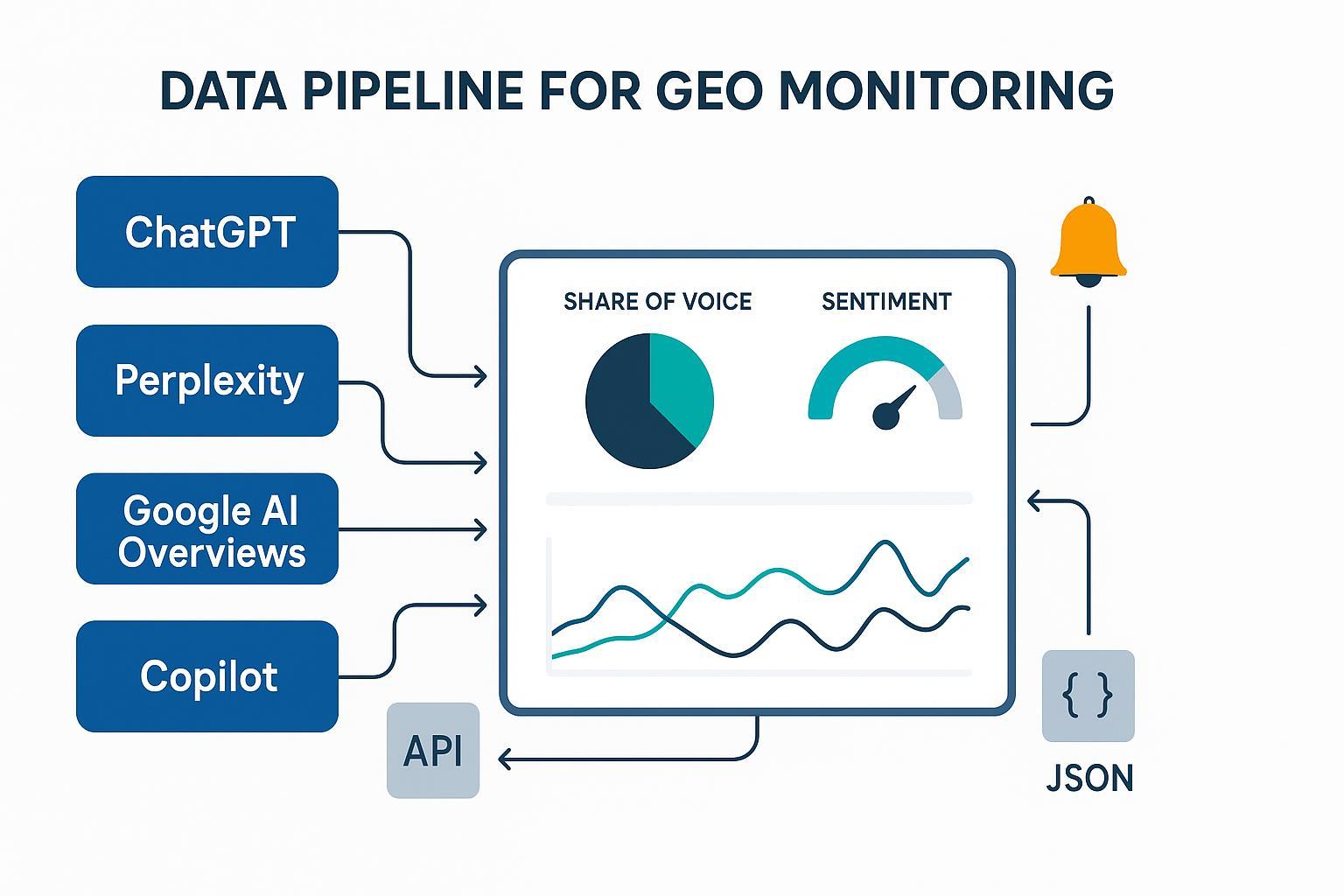
Vous souhaitez savoir si votre marque est citée par ChatGPT, Perplexity ou dans les AI Overviews de Google — et comment cela évolue semaine après semaine ? Construisons, pas à pas, un système de monitoring GEO fiable, conforme et actionnable.
1) Pourquoi un système de monitoring GEO maintenant
La GEO vise à optimiser la présence d’une marque dans les réponses générées par des moteurs/agents IA (au‑delà des SERP classiques). Par rapport au SEO, la cible change: on cherche des mentions, des citations et des liens dans des réponses synthétiques, pas seulement des positions. Pour un aperçu structuré des différences, voyez notre comparaison SEO traditionnel vs GEO.
Le périmètre à surveiller inclut Google AI Overviews (AIO), ChatGPT, Perplexity et, selon votre stack, Copilot. Les formats, la volatilité et l’accès varient selon chaque plateforme. Pour choisir où commencer, appuyez‑vous sur ce comparatif pratique: ChatGPT vs Perplexity vs Gemini vs Bing pour le monitoring.
Petit rappel utile: la « visibilité IA » ne se résume pas à être vu; elle concerne aussi la qualité des preuves utilisées par les modèles. Si le sujet est nouveau pour votre équipe, lisez la définition d’AI Visibility et suivi multi‑plateforme.
Côté volatilité, plusieurs analyses montrent que les AIO changent plus souvent que les classements organiques. Selon Search Engine Land (2025), la rotation d’URLs et la nature des réponses AIO sont particulièrement instables, d’où l’intérêt d’un suivi temporel rapproché: Google AI Overviews: ‘organic rankings’ highly volatile (Search Engine Land 2025).
2) Architecture minimale viable (MVP)
Imaginez un pipeline où la collecte (APIs et observations conformes) alimente une normalisation (schéma JSON unifié), puis une couche d’analyse (NER, sentiment) qui produit des KPI GEO, déclenche des alertes et se matérialise dans un dashboard. Deux modes d’implémentation cohabitent: un flux manuel, parfait pour l’amorçage et l’audit; et un flux automatisé, utile pour la scalabilité et des cadences régulières. Gardez la conformité au centre en respectant les CGU et la page Google Search updates; évitez tout scraping interdit.
3) Étape 1 — Construire votre corpus de requêtes
Regroupez vos requêtes par familles: marque (exacte et variantes), non‑marque (« best X », comparatives, alternatives), produit/fonction, et localisations. Démarrez avec 50–200 requêtes priorisées (volume et intention), puis itérez à partir des logs (ce que vos agents IA « explorent » naturellement en réponses). Checkpoint de validation: contrôlez la déduplication, l’attribution langue/pays, et conservez l’horodatage de toute modification du corpus.
4) Étape 2 — Collecter les réponses de façon conforme
ChatGPT (OpenAI) s’utilise via l’API officielle: respectez les limites de débit et implémentez un backoff exponentiel; les bonnes pratiques sont décrites dans OpenAI — rate limits et quotas (docs). Côté Perplexity, l’API « Chat Completions » (compatible OpenAI) et la Search API facilitent la récupération de réponses et de métadonnées de sources — cf. Perplexity — guide Chat Completions. Pour Google AI Overviews, il n’existe pas d’API publique: procédez par observations manuelles (avec captures, horodatage, pays/langue) ou via des outils conformes. Enfin, Copilot ne propose pas d’API de chat publique exposant les citations façon « Bing Chat » historique; limitez‑vous au suivi manuel ou à votre écosystème Microsoft.
Exemple Perplexity (cURL):
curl --request POST \
--url https://api.perplexity.ai/chat/completions \
--header 'accept: application/json' \
--header 'authorization: Bearer VOTRE_CLE_API' \
--header 'content-type: application/json' \
--data '{
"model": "sonar-pro",
"messages": [{"role": "user", "content": "Quels sont les meilleurs logiciels de monitoring GEO ?"}],
"stream": false
}'
Exemple Perplexity (Python, client compatible OpenAI):
from openai import OpenAI
client = OpenAI(api_key="VOTRE_CLE_API", base_url="https://api.perplexity.ai")
resp = client.chat.completions.create(
model="sonar-pro",
messages=[{"role": "user", "content": "Cite des sources fiables sur le GEO et fournis les liens."}]
)
print(resp.choices[0].message.content)
Bonnes pratiques: journalisez la requête exacte, la version du modèle, le code HTTP et le contenu brut de la réponse. En cas d’erreur 429/5xx, appliquez un retry avec backoff (2^n). Checkpoint de validation: pour chaque appel, assurez‑vous d’avoir un contenu de réponse, des métadonnées de sources (si disponibles) et un horodatage complet.
5) Étape 3 — Normaliser les données
Un schéma JSON unifié évite les casse‑têtes d’analyse. Exemple minimal annoté:
{
"mentionId": "m-2025-12-10-0001",
"platform": "perplexity",
"query": "meilleurs outils de monitoring GEO",
"timestamp": "2025-12-10T10:15:23Z",
"lang": "fr",
"country": "FR",
"response_text": "...extrait de la réponse...",
"type": "recommendation",
"segment_index": 0,
"entities": ["VotreMarque", "ConcurrentA"],
"sentiment": {"score": 0.35, "label": "neutre"},
"sources": [
{"title": "Guide GEO", "url": "https://exemple.com/geo-guide", "publisher": "Exemple", "date": "2025-11-20"}
],
"has_brand_link": true,
"brand_match_confidence": 0.92,
"audit": {"model": "sonar-pro", "hash": "sha256:...", "status": 200}
}
Conseils: UTF‑8 partout, ID stables, hash de réponse pour déduplication, vocabulaires contrôlés (plateforme, type). Gardez aussi la requête originale et toute note de conformité (pays, langue, mode recherche activé ou non). Checkpoint de validation: validez le JSON (types/champs), contrôlez l’encodage et testez la déduplication sur un échantillon.
6) Étape 4 — Analyser: entités, sentiment, catégorisation
Pour l’extraction d’entités (NER) et le sentiment, commencez simple avec des librairies éprouvées (spaCy, transformers, ou services managés si disponibles). Définissez des règles anti‑ambiguïté: listes d’inclusion/exclusion, distances de chaînes (Levenshtein) et un score de confiance de « match marque ». Côté catégorisation, qualifiez chaque mention: neutre/positive/négative, « recommandé » vs « alternative », et position au sein de la réponse (haut/milieu/bas) si vous segmentez le texte. Échantillonnez manuellement 5–10% des mentions pour QA mensuelle. Checkpoint de validation: les scores sont dans des bornes cohérentes, la QA manuelle est alignée (≥80% d’accord), et les logs d’inférence sont conservés.
7) Étape 5 — Définir et calculer les KPI GEO
Calibrez des indicateurs comparables dans le temps et entre plateformes. Pour relier performance et qualité des réponses, vous pouvez vous appuyer sur des critères LLMO (exactitude, pertinence, personnalisation) expliqués ici: Mesurer l’exactitude, la pertinence et la personnalisation des réponses IA.
- Part de voix IA: proportion de réponses qui mentionnent votre marque sur un ensemble de requêtes stable.
- Taux de citation/lien: part des réponses qui contiennent au moins un lien/source vers vos pages.
- Inclusion rate AIO: % de requêtes déclenchant un AIO où votre site apparaît dans les sources citées.
- Sentiment moyen pondéré: moyenne des scores de sentiment par mention, pondérée par l’importance de la requête.
- Stabilité temporelle: variance (ou coefficient de variation) des apparitions/citations sur période glissante.
Checkpoint de validation: recalculez les KPI sur un sous‑échantillon et vérifiez la cohérence (ex. somme des catégories = 1, aucune division par zéro, filtrage correct par langue/pays).
8) Étape 6 — Automatiser: cadences, alertes, exports BI
Cadences recommandées: hebdomadaire sur AIO (volatilité élevée), quotidienne ou bi‑hebdomadaire sur ChatGPT/Perplexity selon enjeux. Planifiez vos jobs (cron, Cloud Scheduler/EventBridge) et implémentez des webhooks (Slack/Teams) pour les alertes.
- Seuils utiles: chute des mentions >30% sur 7 jours; sentiment moyen <0.2; perte d’un lien AIO sur une requête critique; bascule d’une recommandation de votre marque vers un concurrent.
- Exports: CSV/JSON vers votre data warehouse (BigQuery, Redshift, Snowflake) et vers votre outil de dataviz. Archivez les réponses brutes et captures d’écrans (AIO) pour audit.
Checkpoint de validation: un rapport d’exécution horodaté (succès/erreurs), des alertes testées, et un export lisible par votre BI.
9) Exemple pratique d’intégration (neutre)
À l’étape d’agrégation multi‑plateformes, un outil comme Geneo peut être utilisé pour centraliser les réponses collectées (ChatGPT, Perplexity, observations AIO), appliquer une analyse de sentiment standardisée et produire un tableau de bord de KPI GEO filtrable par moteur, langue, période. Divulgation : Geneo est notre produit.
10) Troubleshooting ciblé
Transformez les problèmes fréquents en routines de diagnostic. Si les réponses Perplexity n’affichent pas de sources, vérifiez le modèle et, lorsque c’est possible, les options de recherche, ou testez un prompt qui demande explicitement des références. Pour les JSON invalides, mettez en place une validation via JSON Schema, normalisez les types (dates ISO 8601, booléens) et journalisez les corrections. Les limites API (429, latence) se gèrent avec backoff exponentiel, métriques de quotas et file d’attente. En cas d’ambiguïté de marque, combinez regex, NER et distance de chaîne; ajustez vos listes d’inclusion/exclusion et surveillez les faux positifs. Enfin, côté AIO, restez strictement conforme aux CGU: pas d’automatisation interdite; conservez des captures horodatées.
11) Table de synthèse — Champs clés du schéma
| Champ | Type | Rôle |
|---|---|---|
| mentionId | string | Identifiant unique et traçable de la mention |
| platform | enum | chatgpt, perplexity, google_aio, copilot |
| query | string | Requête source (texte exact) |
| timestamp | datetime (ISO 8601) | Horodatage UTC de la collecte |
| lang / country | string | Codes ISO langue/pays |
| response_text | string | Extrait de réponse utile à l’analyse |
| type | enum | recommendation, comparison, neutral, etc. |
| entities | array | Entités détectées (incluant la marque) |
| sentiment | object | score (−1 à 1) et label |
| sources[] | array | title, url, publisher, date |
| has_brand_link | bool | Lien/citation vers un actif de marque présent |
| brand_match_confidence | float (0–1) | Confiance de matching de la marque |
| audit | object | modèle, hash, code HTTP, notes de conformité |
12) Prochaines étapes
- MVP en 2 semaines: corpus de 100 requêtes, collecte Perplexity/ChatGPT automatisée, AIO observée manuellement, normalisation JSON, premiers KPI + alertes basiques.
- Mois 2–3: NER/sentiment robustes, dashboards exécutifs, cadences stables, QA mensuelle, et boucle GEO→contenu (ajustements éditoriaux et preuves).
- Mois 4+: intégration BI complète, tests contrôlés (impact de nouveaux contenus sur l’inclusion AIO), politiques d’échantillonnage plus fines et gouvernance avancée.
Envie d’accélérer l’agrégation et le reporting sans repartir de zéro ? Essayez Geneo sur un set pilote de requêtes pour valider vos KPI et votre méthode, puis internalisez ce qui doit l’être.
Notes de conformité et sources utiles (sélection):
- Volatilité AIO: Search Engine Land (2025).
- Politiques et évolutions Search/AI Overviews: Google Search updates (officiel).
- Limites et bonnes pratiques d’appels: OpenAI — rate limits (docs).
- Accès Perplexity (API): Perplexity — Chat Completions (docs).



