
Comment cartographier votre site pour la recherche IA : guide étape par étape
Guide étape par étape pour améliorer la visibilité et les citations de votre site dans les IA, avec schémas, sitemaps, bots et KPIs.

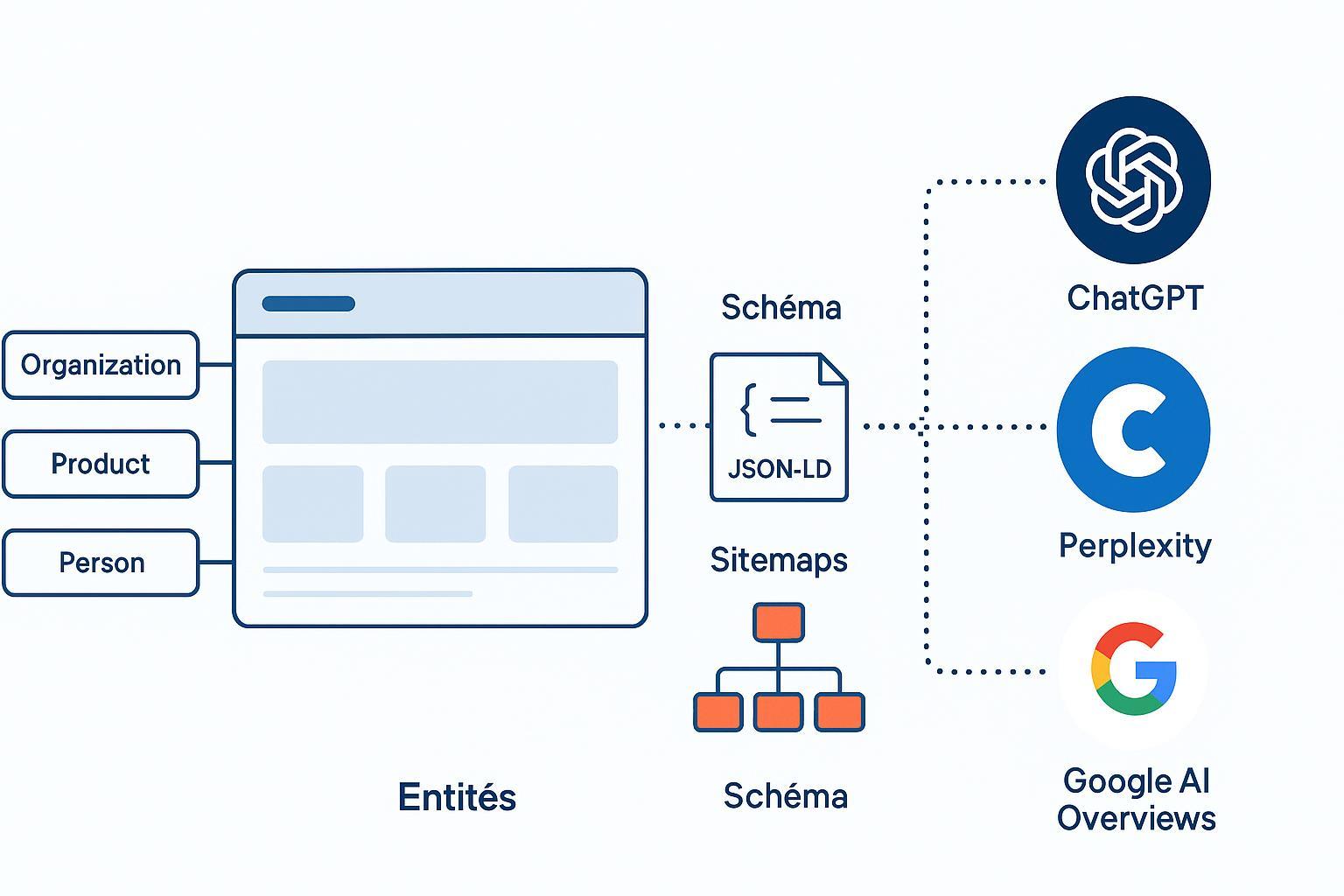
Vous voulez que votre site soit cité par ChatGPT, Perplexity ou les AI Overviews de Google — sans magie ni promesses creuses ? Voici le guide opératoire pour y parvenir, étape par étape, avec un focus 2025 sur les entités, les passages « answerables », les schémas, les sitemaps et les contrôles des bots IA. Et si on construisait un graphe clair que ces systèmes peuvent comprendre et réutiliser ?
1) Ce que « mapper vers l’IA » veut dire (GEO/AEO/LLMO)
Le SEO classique optimise des pages pour des classements. Le mapping « site → IA » vise autre chose : produire des blocs de réponses fiables que les systèmes génèrent en s’appuyant sur des sources multiples, des entités reconnues et des passages bien délimités. Les AI Overviews de Google sélectionnent et affichent des liens de provenance quand un résumé assisté par IA est jugé utile, sans action spéciale obligatoire du site au-delà des bonnes pratiques de qualité et d’éligibilité décrites par Google dans la page officielle AI features and your website (2025) — voir la documentation « AI features » dans Google Search Central.
Plutôt que de redéfinir tout le vocabulaire ici, vous pouvez approfondir la différence entre SEO, GEO et LLMO via notre article en français « Nouveaux acronymes SEO : GEO, GSVO, AIO, LLMO » et la comparaison « Traditional SEO vs GEO (Geneo) » (EN).
2) Pré‑requis et audit express (10 minutes)
Avant de poser la première brique, vérifiez que les fondations tiennent :
- Indexation active (Google/Bing), contenu accessible, Core Web Vitals corrects, pages auteurs existantes.
- Sitemaps XML propres et déclarés dans robots.txt; contrôlés dans Search Console.
- Auteurs identifiés, dates de publication/modification visibles, politique éditoriale accessible.
- Robots.txt propre (pas de blocages « surprises » sur des répertoires critiques).
Astuce rapide: pensez « lisible par un humain, compréhensible par une machine ». Si la page n’est pas claire pour un lecteur pressé, elle ne sera pas « extractible » pour un modèle.
3) Étape 1 — Cartographier vos entités (Knowledge Graph interne)
Commencez par l’inventaire des entités de premier niveau: Organization (votre marque), Product/Service, Person (auteurs, experts), Topic (sujets piliers). Créez une fiche par entité avec URL canonique stable, et reliez-les avec sameAs (profils officiels, Wikidata/Wikipedia le cas échéant) et about/mentions sur les pages de contenu. C’est votre « carte d’identité » pour la compréhension machine.
Exemple minimal pour Organization + Person (à enrichir) :
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Votre Marque",
"url": "https://votremarque.com",
"logo": {
"@type": "ImageObject",
"url": "https://votremarque.com/logo.png"
},
"sameAs": [
"https://www.linkedin.com/company/votremarque/",
"https://www.wikidata.org/wiki/Qxxxxxx"
],
"employee": {
"@type": "Person",
"name": "Prénom Nom",
"jobTitle": "Rédacteur technique",
"image": "https://votremarque.com/auteurs/prenom.jpg",
"sameAs": [
"https://www.linkedin.com/in/prenomnom/"
]
}
}
Deux conseils terrain: gardez les URL d’entités stables dans le temps, et vérifiez la parité multilingue (hreflang) si vous publiez en plusieurs langues.
4) Étape 2 — Concevoir du contenu « passage‑first » (chunking)
Pensez votre page comme une série de mini‑réponses autonomes. Chaque H2/H3 adresse une sous‑question précise, introduite par une définition courte, suivie d’étapes concrètes ou d’un exemple. Ajoutez un TL;DR en haut et une FAQ statique en bas si c’est pertinent. Ce « design par passages » facilite l’extraction par les systèmes IA qui synthétisent des morceaux de pages, pas uniquement des pages entières.
Deux tests utiles: 1) un collègue peut‑il copier un seul paragraphe pour répondre à une question sans sortir du contexte ? 2) les titres H2/H3 sont‑ils suffisamment descriptifs pour être compris isolément ?
5) Étape 3 — Balisage schema.org qui compte
Les données structurées aident les moteurs à comprendre votre contenu et à activer des résultats enrichis, même si elles ne « garantissent » pas une citation dans AI Overviews. Priorisez Article/BlogPosting, HowTo, FAQPage, Product, Organization, Person, BreadcrumbList et WebSite/SearchAction. Références officielles: voir l’introduction aux données structurées de Google et les types spécifiques (2024–2025).
Extrait Article/BlogPosting minimal (alignez toujours le JSON‑LD avec ce qui est visible dans la page) :
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Titre de l’article",
"image": ["https://exemple.com/cover.jpg"],
"datePublished": "2025-11-30",
"dateModified": "2025-12-05",
"author": {"@type": "Person", "name": "Nom Auteur", "sameAs": ["https://www.linkedin.com/in/auteur/"]},
"publisher": {"@type": "Organization", "name": "Votre Marque", "logo": {"@type": "ImageObject", "url": "https://exemple.com/logo.png"}},
"about": [{"@type": "Thing", "name": "Recherche IA"}]
}
Prudence: Google a réduit la visibilité publique de HowTo/FAQ en 2023–2024; ces schémas restent pertinents si le contenu est réellement pédagogique et stable.
6) Étape 4 — Sitemaps et discoverability fiables
Segmentez vos sitemaps par type (articles, produits, FAQ/HowTo) et maintenez un index. Assurez un
Flux de maintenance simple: lors de chaque ajout/modification/suppression significative, regénérez le sitemap correspondant, mettez à jour l’index, et laissez une trace de contrôle (changelog interne). Déclarez l’URL du sitemap principal dans robots.txt.
7) Étape 5 — Attribution et stratégie de citations sortantes
Les systèmes IA valorisent la fiabilité. Citez des sources primaires et pérennes; utilisez des ancres descriptives dans le corps du texte, pas des « cliquez ici ». Préférez des institutions, des normes, des guides officiels et des études originales. Montrez votre méthode: auteurs visibles, dates claires, bibliographie utile — cela renforce E‑E‑A‑T et la probabilité d’être choisi comme source.
8) Étape 6 — Contrôler les bots IA sans casser le SEO
Décidez ce que vous autorisez: l’entraînement et/ou le grounding pour les produits IA, ou seulement l’indexation search classique. Les contrôles s’effectuent principalement via robots.txt. Quelques repères officiels:
- OpenAI documente GPTBot et l’opt‑out robots.txt. Voir la page dédiée OpenAI — GPTBot.
- Google‑Extended est un jeton robots.txt (pas un user‑agent distinct) pour autoriser/refuser l’usage IA des contenus; cela n’affecte pas l’indexation classique. Voir robots d’exploration communs de Google.
- Vérifiez l’authenticité de Bingbot via reverse DNS (utile si vous ouvrez à Copilot). Voir Microsoft — Verify Bingbot.
- PerplexityBot: pas de documentation officielle centralisée; des analyses Cloudflare 2025 rapportent des comportements de crawlers « stealth ». L’information n’émane pas de Perplexity. À lire avec précaution: Cloudflare — Perplexity using stealth crawlers.
Tableau de synthèse (références et contrôles):
| Bot / Jeton | Contrôle recommandé | Doc / Référence |
|---|---|---|
| Google‑Extended | Autoriser/Refuser via robots.txt; n’impacte pas l’indexation | Google — crawlers communs |
| GPTBot (OpenAI) | Allow/Disallow dans robots.txt | OpenAI — GPTBot |
| Bingbot (Microsoft) | robots.txt + vérif reverse DNS | Microsoft — Verify Bingbot |
| PerplexityBot | Règles robots.txt + surveillance logs/WAF | Cloudflare (contexte) |
Modèles robots.txt (adaptez selon votre politique):
Autorisation sélective IA
User-agent: Googlebot
Allow: /
User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: ClaudeBot
Allow: /
Sitemap: https://votresite.com/sitemap.xml
Politique restrictive IA (tout en gardant l’indexation classique)
User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
Sitemap: https://votresite.com/sitemap.xml
Tip opérationnel: contrôlez vos journaux serveur (user‑agents, reverse DNS), configurez des alertes de volumétrie anormale, et documentez vos changements pour revenir en arrière si besoin. Pensez‑y comme à un « robinet » d’accès IA que vous ajustez par segment.
9) Étape 7 — E‑E‑A‑T et transparence éditoriale
Mettez en avant l’expérience vécue et l’expertise des auteurs (bio complète, certifications, travaux), des relectures par des spécialistes, des sources externes, des dates visibles et une politique de corrections. Google rappelle que le contenu « people‑first » et la page experience soutiennent la qualité et l’éligibilité aux fonctionnalités d’IA. Voir « People‑first content » sur le blog Google Search Central.
10) Étape 8 — Mesure et boucle d’amélioration continue
Sans mesure, pas de progrès. Suivez trois axes: visibilité (apparitions, citations, diversité des domaines), qualité de réponse (accuracy, relevance, personalization) et perception (sentiment). Établissez un rituel: audit mensuel des citations, mise à jour des passages faibles, ajout/ajustement de schémas, rafraîchissement des preuves, surveillance des bots IA.
Pour cadrer vos KPIs IA, consultez notre cadre « AI Search KPI Frameworks 2025 » et la grille « LLMO Metrics — Accuracy, Relevance, Personalization ». Pour la vision d’ensemble, voici notre définition de la visibilité en recherche IA.
Exemple pratique — Vérifier vos citations et boucler l’amélioration
Disclosure: Geneo est notre produit.
Workflow neutre d’usage: importez vos requêtes stratégiques (non‑marque et marque). Suivez les occurrences où votre domaine est cité dans les réponses de ChatGPT/Perplexity et les AI Overviews, notez le contexte, la page source et le sentiment. Repérez les requêtes où vous n’êtes pas cité mais où vos concurrents le sont. Revenez sur la page concernée: renforcez la section « passage‑first » correspondante, ajoutez une source primaire manquante, complétez le schéma (Article/HowTo/FAQPage si pertinent), puis re‑mesurez deux à quatre semaines plus tard.
Ce cycle simple « mesurer → enrichir → re‑mesurer » évite les refontes hasardeuses et vous rapproche des critères réellement utilisés par les moteurs de réponses.
Troubleshooting — 7 pannes fréquentes et correctifs rapides
- Bots IA hors contrôle: robots.txt incohérent ou non respecté. Mettez à jour vos règles, validez les UA (reverse DNS pour Bingbot), surveillez les logs et ajustez WAF/rate‑limits au besoin.
- Schémas invalides: utilisez le Rich Results Test et le validateur Schema.org; corrigez les propriétés obligatoires; évitez le « mismatch » entre JSON‑LD et contenu visible.
- Entités ambiguës: renforcez sameAs (profils officiels, Wikidata), créez des fiches entités stables, reliez depuis vos hubs thématiques.
- Sitemaps « bruyants »: lastmod erroné, URLs non indexables; nettoyez et segmentez, puis resoumettez.
- Hreflang instable: assurez parité de contenu et schémas; testez via Search Console et outils tiers.
- Contenu peu « answerable »: reformulez en définitions nettes, étapes numérotées, FAQ statiques; clarifiez les H2/H3.
- Signaux off‑site faibles: ajoutez des preuves externes (publications, normes, UGC de qualité), développez des pages auteurs solides.
Prochaines étapes
- Faites l’audit express (section 2) et cartographiez 10–20 entités clés (section 3).
- Convertissez vos 5 pages prioritaires au design « passage‑first » (section 4) et ajoutez les schémas (section 5).
- Sécurisez sitemaps et robots.txt (sections 6–8), puis lancez une itération de mesure (section 10) pendant 30 jours.
- Si vous souhaitez centraliser la mesure des citations IA et accélérer les boucles d’amélioration, vous pouvez utiliser Geneo en appui.
Ressources officielles citées (sélection)
- Google — AI features and your website (2025) : Search Central — AI features
- Google — Sitemaps : Build and Submit a Sitemap
- Google — Données structurées : Intro structured data
- Google — People‑first content : Blog Search Central
- OpenAI — GPTBot
- Microsoft — Verify Bingbot
- Cloudflare (contexte) — Perplexity stealth crawlers



