
Comment l’IA classe le contenu sans index web traditionnel
Découvrez comment l’IA classe du contenu via RAG, embeddings et recherche vectorielle sans index web classique. Explications et conseils SEO.

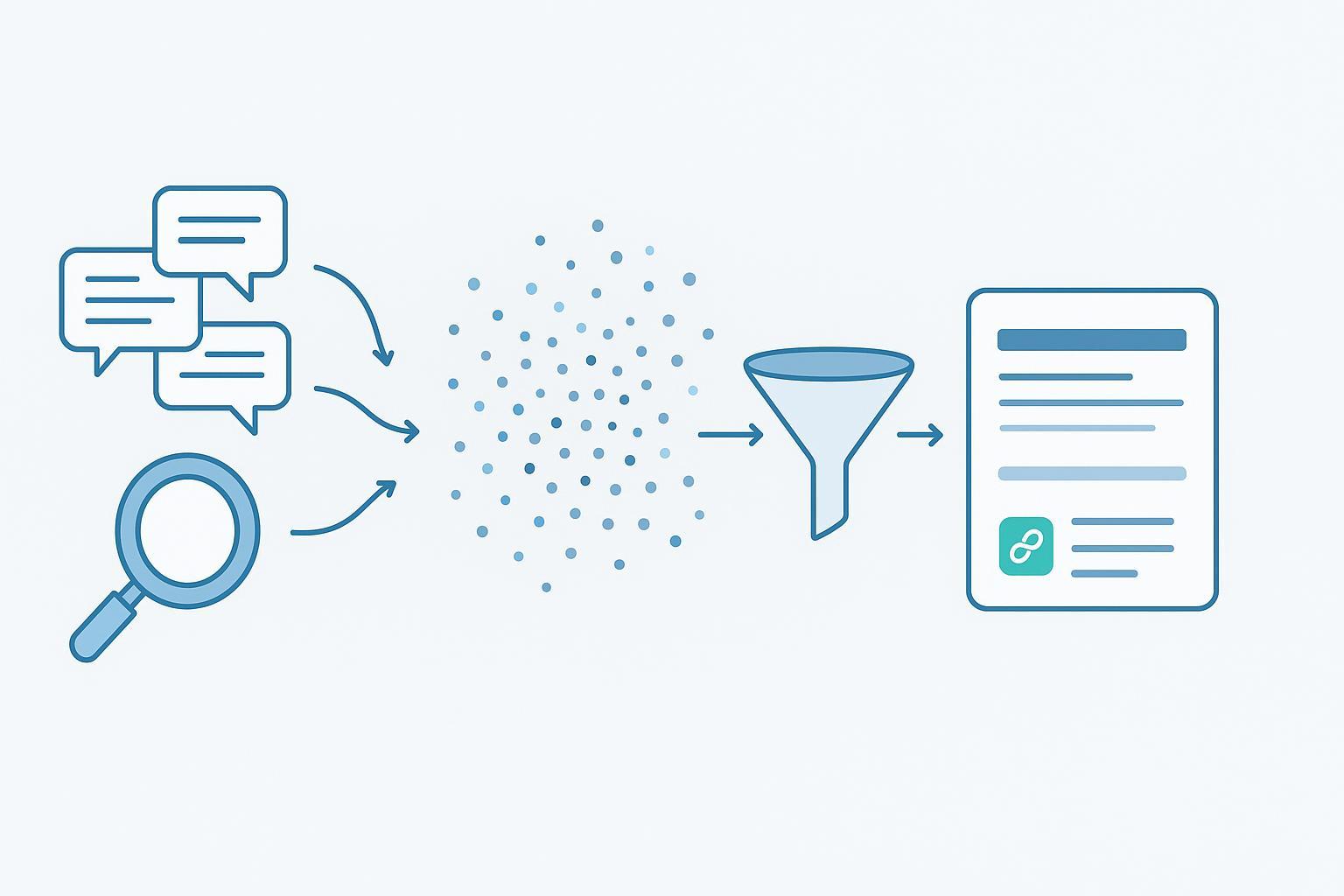
Les réponses générées par l’IA ressemblent à de petits « résumés experts » qui citent parfois des sources. Mais comment choisissent‑elles ces sources si elles ne s’appuient pas (uniquement) sur un index web inversé classique façon moteurs de recherche historiques ? La réponse tient dans un pipeline moderne qui couple embeddings, recherche vectorielle, reranking et RAG (Retrieval‑Augmented Generation). Voyons ce qui se passe sous le capot — et ce que vous pouvez faire, très concrètement, pour que vos contenus soient sélectionnés.
1) Pourquoi parler d’un « classement sans index »
L’index inversé (termes → pages) qui a fait le succès du SEO ne disparaît pas, mais les moteurs « IA » privilégient la similarité sémantique: ils comparent des vecteurs (embeddings) représentant le sens des textes, plutôt que de ne compter que des occurrences de mots. Résultat: la sélection initiale de passages pertinents n’a pas besoin d’un index lexical global identique à celui d’un moteur traditionnel; elle peut s’appuyer sur un index vectoriel et des filtres. Le classement final est ensuite affiné par un reranker plus coûteux mais plus précis, puis une synthèse cite (ou non) des sources.
Deux conséquences majeures pour la visibilité:
- la « pertinence sémantique » prime: un contenu clair, bien structuré et riche en entités a plus de chances d’être jugé proche de la requête;
- la « citabilité » compte: sections FAQ/HowTo, preuves, données structurées et PDF techniques offrent des points d’ancrage faciles à extraire.
2) Visualiser le pipeline en une image mentale
Pensez à une grande bibliothèque. Au lieu de classer les livres par mots exacts, un bibliothécaire IA donne à chaque paragraphe une signature mathématique (un vecteur). À la demande, il retrouve les passages « qui ont l’air de parler de la même chose », les remet dans l’ordre, puis rédige un résumé en citant les extraits les plus solides. Voici le schéma textuel typique:
Requête utilisateur
↓ (réécritures / expansions possibles)
Embeddings de la requête
↓
Recherche top‑k en base vectorielle (option hybride avec BM25)
↓
Filtres (métadonnées, fraîcheur, domaine, langue, droits)
↓
Reranking (cross‑encoder ou LLM‑as‑judge)
↓
Constitution du « contexte » (passages diversifiés, dé‑dupliqués)
↓
LLM de synthèse → Réponse
↳ Citations / liens visibles selon la plateforme
↓
Boucles de feedback (préférences utilisateurs, garde‑fous)
Si vous deviez l’expliquer à un collègue non technique, dites‑lui simplement: « l’IA fait d’abord un rappel large avec des vecteurs, puis elle resserre la sélection avec un juge plus précis avant d’écrire une réponse ». Simple, non ?
3) Les briques qui font la différence
Embeddings et recherche vectorielle (ANN)
Des modèles d’« embeddings » transforment requêtes et passages en vecteurs. Une base vectorielle (FAISS, Qdrant, Pinecone…) permet de retrouver rapidement les top‑k éléments les plus proches (cosinus ou produit scalaire) via des index ANN (HNSW, IVF). Pour améliorer la précision en tête de liste, on ajoute souvent un reranking. Pour un aperçu clair de l’intérêt du reranking bi‑encoder → cross‑encoder, voir le guide Pinecone (2024) « Refine Retrieval Quality with Rerank »: améliorer la qualité de la recherche avec le reranking (Pinecone, 2024).
Hybridation lexical + sémantique
La recherche « hybride » fusionne un score lexical (BM25) et un score dense (vecteurs). Utile pour couvrir les termes rares (lexical) tout en conservant la proximité de sens (dense). De nombreux systèmes IA combinent les deux, surtout sur des requêtes techniques ou de marque.
Reranking (cross‑encoders, LLM‑as‑judge)
Le reranker lit chaque paire (requête, passage) et produit un score de pertinence fin. Les cross‑encoders sont coûteux mais très précis en top‑k. Certains systèmes utilisent ponctuellement un LLM pour arbitrer entre passages. Le compromis coût/qualité/latence est clé.
Agrégation et synthèse contrôlée
Avant de rédiger, le système diversifie les sources, élimine les doublons, contrôle la longueur et ajoute des garde‑fous (politiques de sécurité, style). La réponse peut lier explicitement les documents utilisés — selon les plateformes, cette transparence varie.
Variantes avancées utiles à connaître
- Query fan‑out (réécritures multiples): on reformule la requête en plusieurs sous‑requêtes, puis on fusionne les résultats pour augmenter le rappel.
- Late interaction (type ColBERT): plusieurs vecteurs par passage et une interaction « tardive » pour gagner en précision sans exploser la latence. Pour une introduction récente, voir l’aperçu Weaviate (2025) sur la late interaction.
- RAG « out‑of‑db »: récupération sur le web en temps réel plutôt que dans une base interne; très sensible à la fraîcheur, mais aussi à la qualité des sources.
Pour une mise en pratique francophone, le tutoriel de Datacorner (2024) explique très bien similarité sémantique, découpage en « chunks » et RAG: tutoriel RAG et similarité sémantique (Datacorner, 2024).
Pour des définitions « côté business », voyez aussi notre ressource interne sur la visibilité de marque dans la recherche IA.
4) Observations par plateforme: AI Overviews, Perplexity, ChatGPT
Deux constats chiffrés aident à cadrer le sujet:
- Côté transparence des sources, l’étude Ecommerce‑Nation/Profound (2025) rapporte, sur son échantillon (août 2024–juin 2025), que Perplexity affiche des citations visibles dans 98,6% des réponses, Google AI Overviews dans 51,5% et ChatGPT (mode navigation) dans 2,5%. Ces valeurs dépendent du protocole et ne s’extrapolent pas toutes requêtes confondues.
- Côté volume et diversité de liens dans AI Overviews, les séries d’analyses de SE Ranking (2024–2025) sur les AI Overviews notent souvent 6–14 liens par réponse avec des pics >20 pour les réponses longues, et une concentration marquée sur quelques domaines « piliers » (Wikipedia, Reddit, YouTube, médias reconnus).
Tableau de lecture synthétique (qualitatif):
| Plateforme | Transparence des sources | Sélection et liens | Style de synthèse |
|---|---|---|---|
| Google AI Overviews (Gemini) | Variable, citations visibles dans une part notable des cas (selon études) | Plusieurs liens par overview, diversité réelle mais souvent centrée sur des domaines d’autorité | Synthèse multi‑sources, tons informatif et prudent |
| Perplexity | Très élevée (sources listées quasi systématiquement) | Recherche sémantique + liens visibles, diversité raisonnable | Réponses concises, citations explicites |
| ChatGPT (navigation) | Variable selon mode/scénario | Liens parfois listés, attribution moins systématique | Synthèse pédagogique, granularité dépend du prompt |
Pour un panorama marketing des moteurs IA (SearchGPT, AIO, Perplexity) et des impacts, voir le panorama Partoo (2025).
5) Implications concrètes pour les marques et équipes contenu
Qu’est‑ce que ce pipeline change pour votre stratégie de contenu ? En pratique, trois axes dominent.
-
Structurer pour être « citable ». Concevez vos pages comme des blocs réutilisables: H2/H3 clairs, paragraphes courts, encadrés FAQ/HowTo, définitions nettes d’entités (produits, personnes, lieux). Les PDF techniques, livres blancs et pages « preuves » (méthodologies, jeux de données) sont souvent mieux repris par les moteurs IA que des pages commerciales vagues.
-
Rendre les entités et données visibles. Utilisez les balisages Schema.org adaptés (Article/BlogPosting, FAQPage, HowTo, Product/Offer/Review, Organization, Breadcrumb). Nommez explicitement les auteurs (bio, expertise), liez vos entités à des références externes (sameAs). Cela aide les embeddings à « comprendre qui parle de quoi » et facilite le reranking.
-
Élargir la couverture et maintenir la fraîcheur. Couvrez vos sujets piliers avec des pages mères et des FAQs associées; mettez à jour régulièrement; multipliez les formats « citables » (schémas, tableaux, vidéos sous‑titrées, PDF). Pour cadrer vos objectifs, vous pouvez vous inspirer d’un cadre de KPI 2025 pour la visibilité et le sentiment côté IA.
Enfin, mesurez votre exposition. Les réponses IA ne sont pas des SERP classiques; mieux vaut suivre votre « part de voix IA » (présence, sentiment, liens) sur plusieurs plateformes et dans plusieurs langues si votre marché est international.
6) Limites, risques et points de conformité
-
Hallucinations et attribution. Le RAG réduit les erreurs mais ne les élimine pas. Si des documents récupérés sont faibles ou biaisés, la synthèse le sera aussi. Certaines plateformes n’affichent pas toujours les sources, ce qui complique la vérification.
-
Biais de corpus et multilingue. Les performances baissent souvent hors anglais grand public; la couverture documentaire varie par langue et par secteur. D’où l’intérêt de produire des sources de haute qualité dans la langue cible.
-
Fraîcheur et sécurité. Les pipelines « avec navigation » exposent à la désinformation fraîche et aux attaques (injection de prompt côté page). Hygiénisez vos pages publiques (bannières, commentaires, scripts) et contrôlez ce que vos PDF exposent.
-
Conformité (France/UE). Appliquez les principes RGPD: base légale claire (consentement/intérêt légitime), minimisation, sécurité, DPIA si nécessaire, respect des droits des personnes et du droit d’auteur. En cas de récupération de sources tierces, respectez les conditions d’usage.
7) Check‑list rapide pour rendre un contenu « AI‑search‑friendly »
- Écrivez des sections brèves et autonomes, avec des titres explicites et des définitions nettes d’entités.
- Ajoutez FAQ/HowTo lorsque pertinent; fournissez des preuves (données, méthodes, captures sourcées).
- Publiez des PDF techniques propres (sommaire, titres, métadonnées) et reliez‑les à la page canonique.
- Balisage Schema.org: Article/FAQ/HowTo/Product/Organization, sameAs, Breadcrumb.
- Nommez vos auteurs, liez leurs profils, exposez leur expérience (E‑E‑A‑T).
- Mettez à jour et versionnez; datez clairement les contenus sensibles au temps.
- Surveillez les réponses IA où vous êtes cité (plateformes, langues) et notez les requêtes déclenchantes.
8) Encadré produit (mention discrète)
Disclosure: Geneo est notre produit. Geneo permet de suivre la visibilité de marque dans les réponses IA (présence, citations, sentiment) sur plusieurs plateformes et de centraliser des signaux actionnables pour vos équipes. En savoir plus: Geneo.
9) Pour aller plus loin
- Pour les définitions et acronymes du champ (GEO, LLMO, AI SEO), consultez les acronymes GEO/LLMO/AI SEO expliqués.
- Si vous construisez votre propre grille de pilotage, voyez notre cadre KPI 2025 pour la recherche IA.
- Côté technique, un rappel utile sur le reranking: améliorer la qualité de la recherche avec le reranking (Pinecone, 2024).



