
Architecture technique GEO : le guide complet pour plateformes génératives
Découvrez le guide complet pour concevoir, piloter et sécuriser l’architecture technique GEO. Méthodes, schémas et KPIs pour plateformes IA. Accédez à toutes les clés du GEO moderne !

Optimiser sa visibilité dans les réponses génératives n’est plus un « nice to have ». C’est devenu une discipline avec ses méthodes, ses métriques et… son architecture technique. Ce guide vous montre, de façon concrète, comment concevoir une plateforme GEO (Generative Engine Optimization) robuste et observable, capable de suivre les mentions, les citations et le sentiment sur plusieurs moteurs (Google Mode IA/Overviews, Perplexity, ChatGPT). L’objectif: un système reproductible, mesurable et conforme, qui sert autant les équipes SEO/GEO que les architectes data et les directions marketing.
1. GEO en pratique: définitions, moteurs et « citabilité »
Le GEO consiste à optimiser la présence d’une marque et de ses contenus dans les réponses produites par des moteurs génératifs; le SEO reste centré sur l’indexation et le classement de pages dans les SERP classiques. Si vous débutez sur les acronymes du nouvel écosystème (GEO, GSVO, AIO, LLMO), vous pouvez approfondir avec ce panorama francophone: nouveaux acronymes (GEO/GSVO/AIO/LLMO) et optimisation IA.
Côté moteurs: Google explique que ses fonctionnalités d’IA et votre site Web (Search Central, FR) peuvent afficher des liens « utiles et diversifiés » dans les Aperçus IA; aucune exigence technique dédiée en plus des bonnes pratiques d’indexation et de données structurées. Le blog officiel Google (FR) rappelle l’esprit: aider l’utilisateur à explorer des sujets complexes avec des liens de soutien.
Perplexity adopte une approche « citation-forward »: ses réponses exposent les sources, et son API Sonar Pro permet de personnaliser les requêtes et de récupérer les citations. Voir Introducing the Sonar Pro API.
ChatGPT, de son côté, n’affiche pas systématiquement des liens en mode standard. Les capacités de navigation et d’agents évoluent rapidement, mais pour le suivi GEO, il faut rester factuel: concevoir des campagnes de mesure reproductibles et documentées. Références: Introducing ChatGPT Agent et Introducing ChatGPT Atlas.
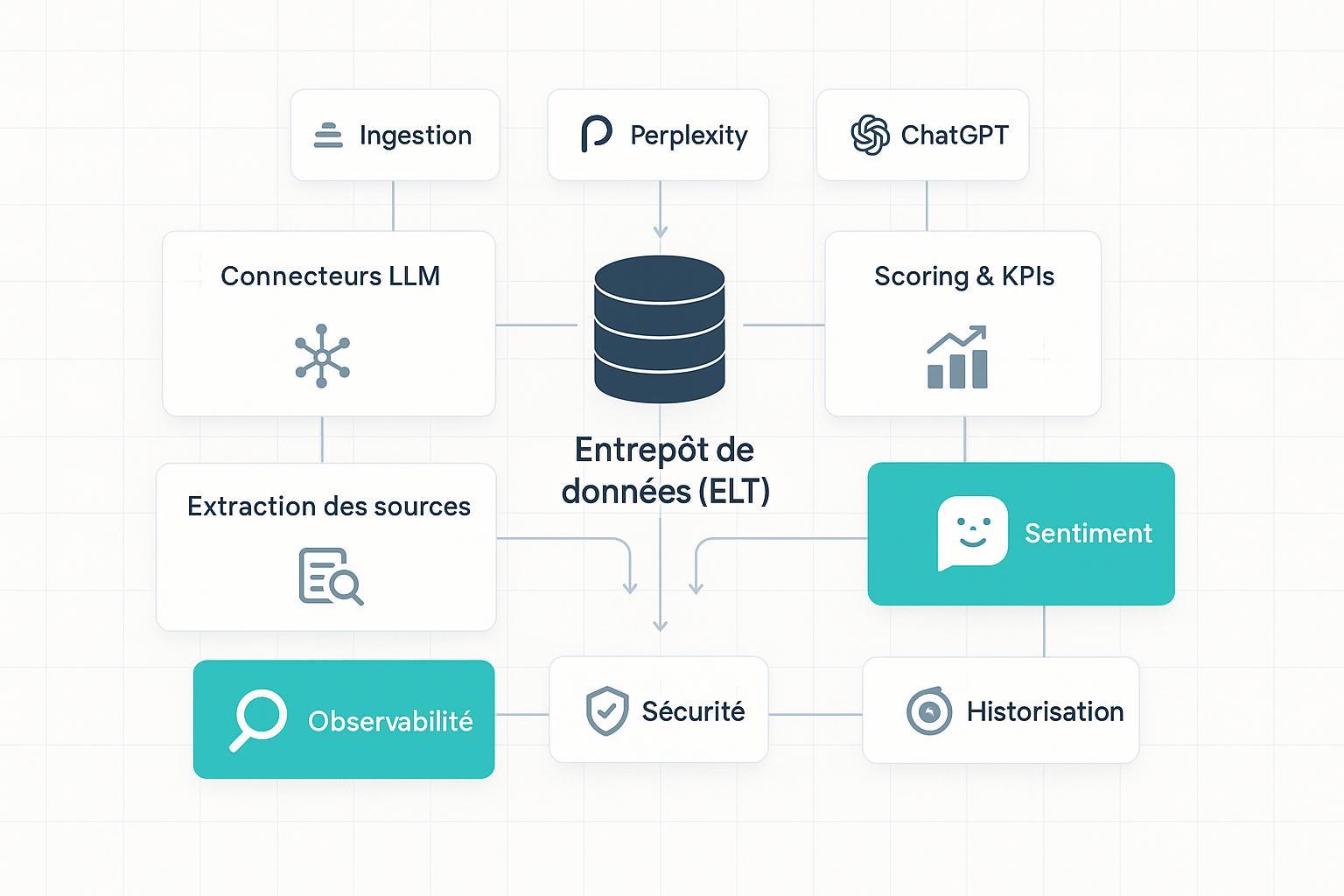
2. Architecture de référence GEO‑RAM (vue d’ensemble)
Pensez votre plateforme GEO comme un système modulaire — GEO‑RAM, pour « Référence d’Architecture Modulaire ». Au cœur: un entrepôt cloud et un pipeline ELT, entourés de connecteurs multi‑moteurs, de modules d’extraction/normalisation des sources, de scoring et de sentiment, d’historisation, d’observabilité, de sécurité et d’APIs.
- Ingestion/connecteurs: intégrations responsables vers Google Mode IA/Overviews (pas d’API dédiée, respect des conditions d’utilisation), Perplexity (API officielle), et scénarios contrôlés pour ChatGPT/agents.
- Stockage/ELT: dépôt des événements bruts horodatés, transformations incrémentales et calculs de métriques.
- Extraction/normalisation: URLs, domaines, entités, intentions, thématiques; déduplication et canonicalisation.
- Scoring/KPIs: définitions transparentes (SOV‑IA, taux de citation, fiabilité des sources).
- Sentiment multilingue: classifieurs dédiés + LLM pour cas ambigus.
- Historisation/observabilité: tables temporelles, OpenTelemetry, dashboards.
- Sécurité/gouvernance: chiffrement, RBAC, isolation multi‑tenant, conformité RGPD/AI Act.
- APIs/Intégrations: REST/GraphQL, exports BI (Power BI, Looker, Tableau).
À quoi bon une telle découpe? Pour isoler les responsabilités, tester chaque module (canary), et corréler métriques, logs et traces quand un connecteur se met à « tousser ».
3. Ingestion et normalisation multi‑moteurs
Votre plan d’ingestion dépend de l’écosystème:
- Google Mode IA/Overviews: pas d’API publique dédiée. Travaillez avec des intégrations conformes, privilégiez les données déjà observables (trafic, logs d’exploration, performances SEO classiques). Restez aligné sur la doc officielle et évitez les pratiques à risque.
- Perplexity: utilisez l’API Sonar Pro pour interroger des requêtes représentatives, récupérer les citations, et consigner les payloads. Paramétrez latence, budget et retries avec une observabilité fine.
- ChatGPT/agents: mettez en place des scénarios reproductibles quand la navigation est disponible; journalisez prompts, versions de modèles et réponses pour la traçabilité.
Normalisation côté données:
- Déduplication et canonicalisation des URLs (suppression des UTM, gestion des redirections).
- Extraction du domaine, du type de page (Article, FAQ, Produit), et des entités (organisation, auteur, produit) via NER multilingue.
- Détection d’intention et de thématique pour agréger les résultats par cluster.
Un mot sur les données structurées: JSON‑LD reste recommandé par Google; veillez à la cohérence entre balisage (schema.org) et contenu visible. C’est ce qui rend vos pages plus « citables » quand un moteur cherche des sources vérifiables.
4. Stockage et pipeline ELT: modèles et schémas de données
Privilégiez un entrepôt cloud (BigQuery, Snowflake, Redshift) avec un ELT hybride:
- Bronzes: événements bruts (requête, réponse, citations, moteur, locale, horodatage, latence).
- Silvers: tables normalisées (URLs canonicalisées, entités, thématiques, attributs qualité).
- Golds: métriques agrégées (SOV‑IA, taux de citation, fiabilité par domaine; comparaisons par période/langue).
Schémas utiles:
- Faits « citation_event »: id_event, moteur, requête, id_reponse, url_source, domaine, type_source, is_brand, sentiment, timestamp.
- Dimension « source »: domaine, organisation, auteur, pays, langue, fiabilité_estimée.
- Dimension « requête »: texte, langue, intention, cluster_thématique.
- Snapshots quotidiens/hebdomadaires pour comparer les périodes et visualiser les tendances.
Stream vs batch? Si vous suivez des volumes élevés ou des campagnes sensibles au temps (lancement produit, crise), combinez un flux d’événements (Kafka/Kinesis) avec des agrégations batch pour les tableaux de bord.
5. Extraction des sources et KPIs de visibilité
Les moteurs ne se comportent pas de la même façon. Perplexity expose les citations de manière native; Google Mode IA montre des liens « utiles »; ChatGPT peut ne pas en afficher. Votre méthodologie doit absorber ces différences sans biaiser vos KPI.
| KPI | Définition opératoire | Calcul (proposé) |
|---|---|---|
| IA Share of Voice (SOV‑IA) | Part des réponses IA qui mentionnent la marque dans un corpus de requêtes | (Nombre de réponses IA mentionnant la marque) / (Nombre total de réponses IA) × 100 |
| Taux de citation | Part des mentions de la marque accompagnées d’un lien ou d’une source explicite | (Nombre de citations explicites de la marque) / (Nombre total de mentions de la marque) × 100 |
| Indice de fiabilité des sources | Score composite par domaine/auteur, calibré par secteur | Somme pondérée: expertise/auteur vérifiables + affiliation + méthodologie/dates |
Méthode conseillée:
- Échantillonner 50–100 requêtes par thématique/langue/pays.
- Interroger périodiquement plusieurs moteurs (Perplexity, Google Mode IA/Overviews; ChatGPT/agents si applicable).
- Parser les réponses et extraire mentions, citations, URLs; stocker les événements et calculer les KPI par période.
- Documenter les limites: variabilité temporelle, différences d’exposition des liens, évolutions des modèles.
6. Analyse de sentiment multilingue et calibration
Pour le français, des classifieurs comme CamemBERT ou FlauBERT fonctionnent bien; pour le multilingue, XLM‑R ou mBERT. Combinez‑les avec des LLM (Llama/Mistral/GPT) pour trancher les cas ambigus avec des prompts calibrés.
Bonnes pratiques:
- Standardisez 3–5 prompts par concept (positif, neutre, négatif), et définissez des seuils de confiance.
- Évaluez sur des jeux publics (MARC, SemEval) et un corpus interne annoté; reportez précision, rappel, F1.
- Surveillez les biais linguistiques ou thématiques; ajustez les pondérations par vertical.
7. Historisation, observabilité et traçabilité
Sans observabilité, vous pilotez à l’aveugle. Instrumentez MELT — métriques, événements, logs, traces — avec OpenTelemetry (CNCF) et exposez des tableaux de bord (Grafana, Datadog, Elastic). Pour les LLM, tracez prompts, latence, erreurs, appels d’outils et feedbacks.
Contrôles qualité:
- Tests canary avant déploiement d’un nouveau connecteur ou réglage de prompt.
- Détection d’anomalies sur les taux d’erreur/latence.
- Journaux d’audit complets pour rejouer et expliquer les résultats.
8. Sécurité, gouvernance et conformité (RGPD/AI Act)
La conformité ne se traite pas à la fin du projet. Intégrez‑la dès la conception:
- Chiffrement: TLS 1.2+ en transit, AES‑256 au repos; gestion des clés par locataire.
- Accès: RBAC strict, MFA, accès conditionnel; séparation des journaux par tenant.
- Journalisation: registre des traitements (art. 30 RGPD), traçabilité des accès et des actions.
- Droits des personnes: accès, rectification, effacement, portabilité sous 30 jours; information claire sur l’usage des données.
- Transferts hors UE: pays adéquats/BCR/SCC; chiffrement et documentation.
- Conservation: durée limitée des données et des logs selon finalité.
Côté cadre réglementaire 2025, voyez la FAQ de la CNIL sur l’entrée en vigueur du règlement européen sur l’IA et ses recommandations IA et RGPD. Pensez aussi multi‑tenant: isolez données et clés par locataire, et documentez la résidence des données.
9. APIs et intégrations (REST/GraphQL, CMS/CRM/BI)
Exposez des APIs propres et stables:
- Authentification: OAuth 2.0/Client Credentials, rotation de clés, scopes par ressource.
- Pagination et filtres: date, moteur, langue, thématique, domaine.
- Webhooks: événements de citation/sentiment pour alimenter des workflows internes.
- Exports BI: connecteurs vers Power BI, Looker, Tableau; dictionnaire de données partagé.
Un conseil simple mais décisif: versionnez vos schémas d’API et vos contrats d’événements; publiez des changelogs clairs pour éviter les intégrations cassées.
10. Exemple pratique / Workflow GEO
Disclosure: Geneo est notre produit.
Objectif: suivre la SOV‑IA, les citations et le sentiment pour une thématique clé sur 3 moteurs.
Étapes (micro‑démo sans image produit):
- Définir un corpus de 60 requêtes FR par thématique (intent mixte: information, comparatif, transactionnel).
- Orchestrer des interrogations périodiques: Perplexity via API Sonar Pro; observation de Google Mode IA; campagnes contrôlées sur ChatGPT/agents si disponibles.
- Ingestion vers l’entrepôt: événements bruts (requête, réponse, moteur, citations, latence).
- Normaliser les URLs et enrichir les entités (organisation, auteur, produit).
- Calculer SOV‑IA, taux de citation et indice de fiabilité; tracer les écarts par période/langue.
- Analyser le sentiment en français; escalader les cas ambigus vers un LLM avec prompts calibrés.
- Exposer un tableau de bord: SOV‑IA par moteur, sources dominantes, sentiment agrégé, tendances.
Ce workflow peut être exécuté avec Geneo pour le monitoring multi‑plateformes; l’outil aide à centraliser les requêtes, les mentions et le sentiment, puis à produire des exports pour votre BI.
11. Bonnes pratiques et écueils courants
- Définir des KPI avant d’écrire du code: sinon vous optimisez dans le vide.
- Documenter vos « instruments » de mesure (modèles de sentiment, prompts, versions): pensez laboratoire, pas magie.
- Éviter le scraping agressif ou non conforme: personne n’a envie d’un incident de sécurité.
- Limiter les affirmations sans études: les moteurs évoluent; privilégiez des observations datées et des campagnes reproductibles.
- Corréler logs, traces et métriques: quand la latence grimpe, vos KPI chutent — montrez‑le.
12. Prochaines étapes
- Formaliser un référentiel de requêtes par marché/produit, mis à jour trimestriellement.
- Publier une page « Architecture & APIs » détaillant schémas, endpoints, politiques d’auth et exemples BI.
- Mettre en place des tests canary sur les connecteurs et un registre de modèles pour le sentiment.
- Instaurer une gouvernance GEO: responsabilités, cycles de revue, et audits de conformité.
Envie de démarrer sans réinventer la roue? Essayez une configuration prête à l’emploi avec Geneo pour centraliser le monitoring multi‑moteurs et exporter vos KPI vers votre stack BI.
Sources et documents utiles (sélection)
- Google Search Central — Fonctionnalités d’IA et votre site Web (FR)
- Blog officiel Google (FR) — IA générative dans la recherche
- Perplexity Hub — Introducing the Sonar Pro API
- OpenTelemetry — Site officiel
- CNIL — FAQ: entrée en vigueur du règlement européen sur l’IA; Recommandations IA et RGPD



