Métricas LLMO: mide exactitud, relevancia y personalización de IA
Descubre cómo medir la calidad de respuestas IA con métricas LLMO: exactitud, relevancia, personalización y visibilidad en buscadores generativos. Geneo.

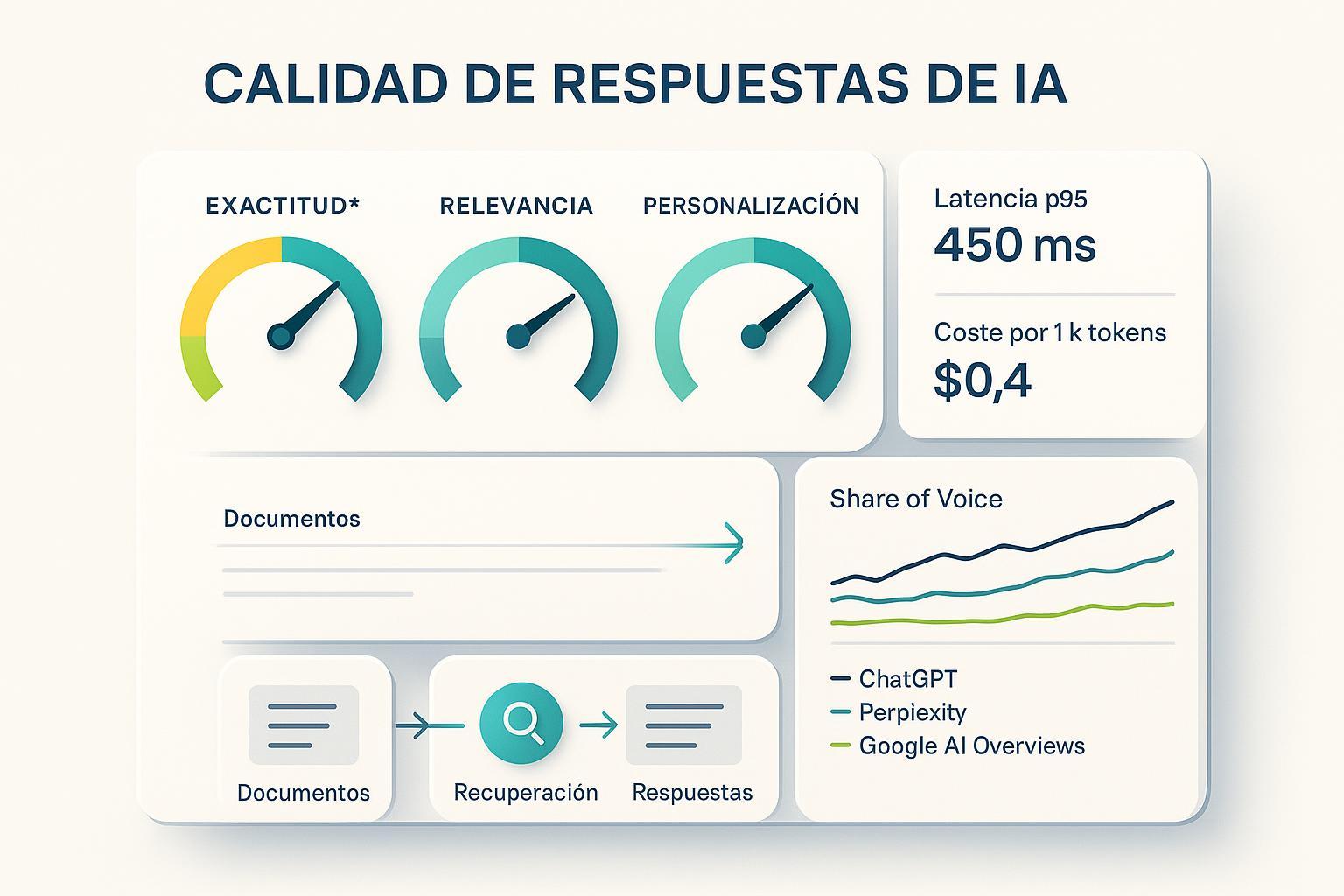
¿De qué sirve “optimizar para IA” si no sabes cómo medir la calidad de las respuestas? Las métricas de LLMO son el puente entre lo técnico y el negocio: te dicen si una respuesta es correcta, útil para la intención del usuario y adecuada al perfil, y si además tu marca gana visibilidad en motores generativos como ChatGPT, Perplexity o los AI Overviews de Google.
En pocas palabras: LLMO es el conjunto de prácticas y métricas para optimizar modelos de lenguaje con foco en calidad percibida y resultados de negocio. No es solo MLOps (infra y despliegue), ni únicamente evaluación académica; combina factualidad, relevancia, personalización, salud del sistema y KPIs de impacto. En evaluación holística, referencias como el marco HELM del Stanford CRFM subrayan dimensiones como factualidad, robustez y seguridad, clave para 2024–2025, según el propio HELM (Stanford CRFM) 2023–2024.
Las 3 métricas núcleo de calidad
-
Exactitud (factualidad/groundedness)
- Qué es: proporción de afirmaciones de la respuesta que están respaldadas por evidencia verificable (idealmente citas o contexto recuperado).
- Cómo medir: en sistemas RAG se usa “faithfulness” (p. ej., dividir las afirmaciones soportadas entre el total). Este enfoque está documentado en RAGAS: Faithfulness (docs v0.1.x).
- Por qué importa: reduce alucinaciones y aumenta la confianza del usuario.
-
Relevancia
- Qué es: alineación con la intención de la consulta y el contexto disponible.
- Cómo medir: en la fase de recuperación, métricas de IR como nDCG o MRR; y en la respuesta, similitud semántica consulta–respuesta y cobertura de intención. Guías prácticas recientes integran estas métricas, como LangChain: Evaluating RAG con RAGAS (2024) y el propio HELM (Stanford CRFM).
- Por qué importa: evita respuestas off‑topic y mejora la utilidad percibida.
-
Personalización
- Qué es: grado en que la respuesta se ajusta al perfil/segmento, tono y contexto del usuario sin invadir la privacidad.
- Cómo medir: rúbricas humanas (adecuación al buyer persona, tono), y comprobaciones automáticas de atributos no sensibles presentes/recordados. Estos enfoques se alinean con principios de fiabilidad y transparencia del NIST AI Risk Management Framework 1.0–2024.
- Por qué importa: aumenta satisfacción y conversión cuando la respuesta refleja el contexto del usuario.
Consejo práctico: define umbrales operativos (SLOs) para cada métrica de calidad, por ejemplo “groundedness ≥ 0,8” o “relevancia ≥ 0,85” como objetivos internos; más adelante verás cómo integrarlos en operaciones.
Con RAG cambia la película: evaluar recuperación y generación
En RAG se evalúan dos etapas:
- Recuperación
- ¿Los documentos correctos aparecen arriba? Métricas como nDCG@k y MRR son estándar en IR y ayudan a saber si el re-ranking funciona. Una guía aplicada es LangChain + RAGAS (2024).
- ¿El contexto recuperado cubre lo necesario? Las métricas “Context Recall” y “Context Precision” de RAGAS miden cobertura y pureza del contexto: RAGAS: Context Recall (stable) y RAGAS: Context Precision (stable).
- Generación
- ¿La respuesta se mantiene fiel al contexto? De nuevo, “faithfulness/groundedness” como en RAGAS: Faithfulness.
- ¿Hay trazabilidad? Exigir citas o enlaces a las fuentes permite verificación posterior, una recomendación coherente con evaluaciones holísticas del HELM (Stanford CRFM).
Evaluación automática vs. humana (y el papel del LLM‑as‑a‑judge)
-
Automatizada
- Similitud semántica, cobertura de entidades, detección de toxicidad y comprobación factual sobre el contexto.
- LLM‑as‑a‑judge: benchmarks como MT‑Bench (LMSYS, 2023) mostraron que usar modelos avanzados como jueces puede aproximar preferencias humanas en diálogos multi‑turn, según MT‑Bench de LMSYS (2023) y su ecosistema descrito en LMSYS Arena (2023).
-
Humana
- Rúbricas: utilidad, claridad, tono, adecuación al segmento e intención; side‑by‑side con muestreo estratificado.
- Mitigación de sesgos: la bibliografía 2024 documenta sesgos de posición y de verbosidad en jueces LLM, por lo que conviene aleatorizar orden, usar jueces distintos del generador y combinar con evaluación humana; ver estudio 2024 sobre sesgo posicional y de verbosidad y un panorama metodológico en LLM‑as‑a‑judge 2023–2024.
Conclusión operativa: combina ambas. La evaluación automática escala y detecta regresiones; la humana captura matices de intención, tono y utilidad.
De la calidad al delivery: salud del sistema y LLMOps
Para que las métricas de calidad sean útiles en producción, intégralas con operaciones (LLMOps):
- SLIs/SLOs de sistema: latencia p95/p99, coste por 1.000 tokens, tasa de errores/timeouts y estabilidad del proveedor. La disciplina SRE recomienda definir SLOs claros y monitorizables, como explica Google SRE: Service Level Objectives.
- Pipelines de evaluación continua: experimentación A/B, despliegues canary y trazabilidad de datos/modelos son prácticas comunes en la industria, según Hugging Face: LLMOps (2023), y guías de plataformas como Vertex AI: LLMOps overview (2024) o Azure AI: evaluación y experimentación (2024).
Impacto de negocio en buscadores generativos (contexto 2025)
- Zero‑click sigue siendo real: en 2024, un estudio de SparkToro estimó que “por cada 1.000 búsquedas en EE. UU., solo 374 clics van a la web abierta”, reforzando la necesidad de medir visibilidad más allá del clic, según el estudio Zero‑Click Search 2024 de SparkToro.
- AI Overviews: su presencia varía por vertical; reportes de mediados de 2024 situaron la visibilidad por debajo del 15% de consultas en EE. UU., como recoge Search Engine Land: visibilidad de AI Overviews en 2024.
- Medición oficial: Google introdujo impresiones y clics de “Visiones Generales con IA” en Search Console (2024–2025), útil para evaluar impacto de cambios de contenido y SGE/GAI, según Google Search Console: métricas de AI Overviews (2024–2025) y las actualizaciones de Google Search 2024–2025.
KPIs de negocio recomendados para LLMO:
- Share of voice en respuestas generativas (por plataforma, país, categoría).
- Sentimiento de menciones en respuestas de IA y asistentes.
- CTR/engagement dentro de módulos generativos cuando existan datos.
- Conversiones/lead quality atribuibles o asistidas por interacciones con IA.
Framework práctico paso a paso
- Define tu “verdad base” y la taxonomía de intents/personas.
- Construye un banco de consultas realistas (incluye long‑tail de tu sector).
- Instrumenta evaluación automática: scripts para recuperación (nDCG/MRR), groundedness (RAGAS) y checks de seguridad/toxicidad.
- Monta un panel de evaluación humana: rúbricas claras, side‑by‑side, muestreo estratificado por intent/persona.
- Para RAG: primero mide recuperación (recall/precisión), después generación (faithfulness) y por último UX (citas utilizables).
- Define SLOs: por ejemplo, p95 ≤ 2,5 s; groundedness ≥ 0,8; nDCG@10 ≥ 0,85; coste objetivo por 1.000 tokens.
- Ejecuta A/B de prompts, modelos y ventanas de contexto; registra datasets y versiones.
- Cierra el loop: etiqueta errores frecuentes y ajusta (prompting, re‑ranking, afinado ligero o datos); despliega canary antes de generalizar.
Ejemplos aplicados a marketing y SEO
- Producto con fichas técnicas: detectas caída de groundedness en AI Overviews para consultas “comparativas de…”; priorizas mejorar FAQs con datos verificables y referencias. Resultado: groundedness +0,12 y aumento de impresiones en el módulo generativo (medido en Search Console).
- Contenido B2B por segmento: tras enriquecer páginas para cada industria, sube la puntuación de personalización (evaluación humana) y el sentimiento de menciones en Perplexity, correlacionando con más leads cualificados en CRM.
¿Dónde encaja Geneo en todo esto?
Si tu objetivo es monitorizar y mejorar la visibilidad de marca en buscadores generativos, una capa de inteligencia de mercado es clave. Geneo es una plataforma para optimizar la visibilidad en motores y asistentes generativos que:
- Monitorea el share of voice de tu marca en respuestas de ChatGPT, Perplexity y AI Overviews de Google.
- Agrega análisis de sentimiento de menciones y su evolución temporal.
- Conserva históricos de consultas y menciones para construir un banco de prompts realista.
- Sugiere acciones de contenido cuando caen señales de visibilidad o relevancia en queries críticas.
Un workflow típico con Geneo:
- Usa históricos de consultas/menciones para seleccionar queries críticas por mercado.
- Observa la tendencia de share of voice y sentimiento; cuando caen, prioriza mejoras de contenido (fichas, FAQs, guías) y enlaza fuentes verificables.
- Tras el cambio, evalúa antes/después: impresiones y clics en AI Overviews (Search Console), evolución de menciones y sentimiento en Geneo, y métricas de negocio (leads/conversiones).
Conoce más o prueba la plataforma en Geneo.
Nota de alcance: si necesitas verificación factual automática a nivel de frase, combínala con pipelines RAG y muestreos humanos; Geneo hoy destaca en monitoreo de visibilidad/sentimiento y en recomendaciones de contenido accionables.
Riesgos, límites y buenas prácticas
- Overfitting a métricas automáticas: valida periódicamente con evaluación humana.
- Sesgo y privacidad en personalización: evita atributos sensibles y sigue principios de gestión de riesgos del NIST AI RMF 2024.
- Sesgos del juez LLM: aleatoriza orden, usa jueces distintos del generador y combina con humanos, considerando hallazgos de 2024 como los sesgos posicional/verbosidad.
- Cambios de plataformas: los algoritmos de motores generativos evolucionan; monitoriza continuamente y mantén SLOs operativos (ver Google SRE: SLOs).
En resumen
Las métricas de LLMO convierten la optimización para IA en un proceso medible: exactitud (groundedness), relevancia y personalización conectadas a salud del sistema y KPIs de negocio. Con una evaluación mixta (automática + humana), prácticas LLMOps y un monitoreo constante de visibilidad en buscadores generativos, puedes reducir alucinaciones, elevar utilidad y ganar cuota de respuestas donde tus clientes ya buscan.
Si tu prioridad es ver y mejorar cómo aparece tu marca en respuestas de IA, comienza instrumentando tu framework y apóyate en herramientas como Geneo para el seguimiento continuo y la activación de mejoras de contenido.