
Ultimativer Leitfaden: Technische Architektur hinter GEO‑Plattformen
Der umfassende Guide zur technischen Architektur moderner GEO‑Plattformen: Cloud-native Bausteine, Standards, Sicherheit & Best Practices. Jetzt Expertenwissen sichern!

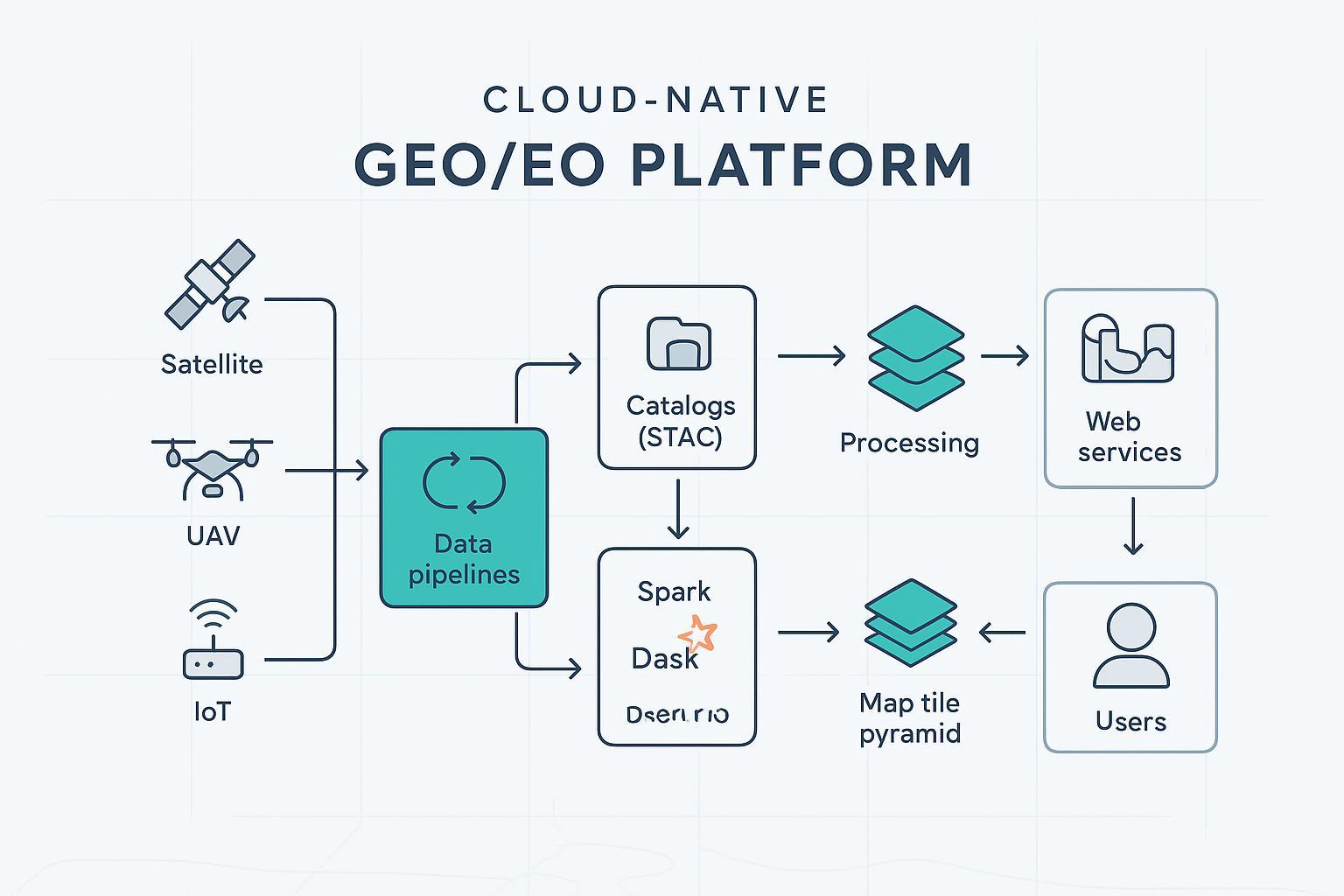
Wer baut heute skalierbare Geodaten‑Systeme, steht vor einer klaren Frage: Welche Architektur trägt von der Aufnahme bis zur Bereitstellung? Dieser Leitfaden beschreibt die Bausteine hinter modernen GEO/EO‑Plattformen – praxisnah, standardsbasiert und ohne Vendor‑Bias.
Einordnung und Systemlandschaft
GEO/EO‑Plattformen verbinden heterogene Quellen (Satelliten, Luftbilder, UAVs, In‑situ/IoT) mit Cloud‑nativen Komponenten für Suche, Analyse und Bereitstellung. Das globale Ökosystem wird als „System von Systemen“ durch GEO/GEOSS koordiniert; der Überblick bei GEO/GEOSS erklärt den interoperablen Ansatz. Europa konsolidiert den Zugang zu Sentinel‑Daten über das Copernicus Data Space Ecosystem; die offizielle Dokumentation zum CDSE beschreibt APIs und Cloud‑Verarbeitung. Für US‑Datenzugänge bietet NASA Earthdata einen zentralen Einstieg.
Architekturüberblick: Vom Sensor zur Karte
Ein stabiler Datenfluss gliedert sich in wiederkehrende Bausteine: Ingestion, Orchestrierung/Qualität, Metadaten/Discovery, Speicher, Verarbeitung, Dienste/Standards, Sicherheit/Governance und Observability/SRE. Denken Sie an eine gut organisierte Lagerhalle: Rohware kommt an, wird geprüft, etikettiert, gelagert, verarbeitet und schließlich über eine Lieferkette ausgeliefert – nur dass hier Kacheln, Kataloge und APIs die Rollen übernehmen.
Datenquellen und Ingestion
Quellen variieren von Sentinel/Landsat über Luftbildarchive bis zu UAV‑Batches und IoT‑Streams. Architekturentscheidungen kreisen um Batch vs. Stream, Harmonisierung von Koordinatenreferenzsystemen (CRS) und Zeitstempeln sowie Validierung/Quality Control (QC). Praktisch heißt das: klare Ingestion‑Jobs mit robustem Fehlerhandling, Idempotenz und Wiederholbarkeit. Streaming‑Quellen benötigen Event‑Puffer, Dead‑Letter‑Queues und Schema‑Validierung.
Orchestrierung, Reproduzierbarkeit und Lineage
Workflows werden häufig mit Airflow, Kubeflow oder Dagster orchestriert. Airflow ist stark für zeitgesteuerte, abhängige ETL‑Jobs, siehe Airflow‑Dokumentation. Kubeflow Pipelines adressieren ML‑Workflows mit Artefakt‑Lineage und Versionierung, siehe Kubeflow Pipelines. Dagster bringt Datenvalidierung und deklarative Assets, siehe Dagster Docs. Für EO‑Plattformen ist die Verbindung zur Katalogschicht zentral: STAC‑Items/Collections sollten als Erstklass‑Artefakte entstehen, mit Provenienz und Prozess‑Metadaten.
Metadaten und Discovery
Die SpatioTemporal Asset Catalog (STAC)‑Spezifikation definiert schlanke, Cloud‑freundliche Kataloge mit Collections, Items und Extensions. Der Einstieg über STAC 1.0.x macht Discovery und Interoperabilität alltags‑tauglich. Klassische ISO‑19115‑Profile bleiben relevant, doch STACs HTTP‑native Modell und die STAC API – Search vereinfachen die Praxis. Als Faustregel: STAC für operative Discovery, ISO für langfristige Archivierung und Normenkonformität. Für Raster‑Assets lohnt ein Blick in den offiziellen Standard: OGC Cloud‑Optimized GeoTIFF 1.0.
Speicherarchitektur und Formate
Objektspeicher (S3, GCS, Azure Blob) bilden den Kern von Data Lakes/Lakehouses für EO‑Daten. Raster werden als Cloud‑Optimized GeoTIFFs (COGs) abgelegt; Vektor‑Datensätze profitieren von Parquet/GeoParquet. GeoParquet ist als Community‑Standard bei OGC geführt, siehe GeoParquet Spezifikation. Zentral bleiben Partitionierung (z.B. nach Zeit/Region), Overviews/Pyramiden und Speicher‑Lifecycle‑Policies. Kostenseitig helfen Tiering‑Mechanismen, z.B. S3 Lifecycle/Intelligent‑Tiering, um kalte Daten automatisch zu verschieben. Think of it this way: Heiß genutzte Kacheln liegen vorne im Regal, Archivdaten wandern ins Hinterlager.
Verarbeitung und KI
Verteilte Frameworks wie Spark und Dask tragen Raster‑ und Vektor‑Workloads; Caching und Materialisierung beschleunigen wiederholte Analysen. Serverless‑Cluster mit Auto‑Scaling auf CPU/GPU senken Wartezeiten für kurzzeitig hohe Last. Für EO‑spezifische ML bieten Foundation Models wiederverwendbare Repräsentationen: IBM und NASA veröffentlichen offen nutzbare geospatial Foundation Models; Details und Modelle sind in IBM‑NASA Geospatial Foundation Models dokumentiert. Typische Aufgaben sind Klassifikation, Segmentierung und Change Detection; die Integration in Pipelines erfolgt über standardisierte Artefakt‑Speicher und reproduzierbare Notebooks.
Dienste und Standards
Die OGC API‑Familie modernisiert klassische OWS durch REST/OpenAPI‑basierte Dienste. Einstiegspunkte: OGC API – Features (IS) und OGC API – Tiles (IS). Für Kachel‑Dienste ist WMTS weiterhin verbreitet; der Standard definiert Tile‑Matrix‑Sets und Pyramiden, siehe OGC WMTS. Ein bewährter Baustein zur COG‑Bereitstellung ist TiTiler; die Projektseite TiTiler erklärt OGC‑Tiles‑kompatible Endpunkte und Cache‑Strategien. Bildlich gesprochen: Die Kachelpyramide ist Ihr Etagenregal – je weiter oben die Zoom‑stufe, desto feiner die Ware, und CDNs liefern sie mit hoher Cache‑Trefferquote.
APIs und SDKs
REST/OpenAPI‑Design mit klaren Conformance‑Klassen, Paginierung, Filterung und Rate‑Limits ist Standard. Für Kataloge erleichtern PySTAC die Arbeit, siehe PySTAC. Notebooks sind ein natürlicher Einstieg für Data Scientists; die STAC‑Übersicht im Planetary Computer zeigt Beispiele.
Sicherheit und Governance
Identität und Zugriff werden üblicherweise über OAuth2/OIDC gelöst; die OpenID Connect Core 1.0‑Spezifikation und RFC 6749 (OAuth 2.0) beschreiben die Grundlagen. Für Zugriffskontrolle lohnt der Vergleich von RBAC und ABAC; NIST liefert mit SP 800‑162 eine solide Basis. Multi‑Tenant‑Isolierung umfasst organisatorische und technische Maßnahmen (Mandanten‑IDs, getrennte Buckets/Namespaces, strikte IAM‑Policies) sowie Audit‑Logging gemäß Compliance‑Vorgaben.
Observability und SRE
Ohne Messwerte bleibt Architektur Theorie. Sinnvolle SLIs: Pipeline‑Latenz (Ingestion‑bis‑Serve), Datenaktualität/Freshness, Tile‑Cache‑Hit‑Rate, API‑Latenz/Fehlerquote, Kosten pro Anfrage/Job. Praktikabel sind standardisierte Telemetrie (OpenTelemetry), Metrik‑Sammler (Prometheus) und Dashboards (Grafana). Ziel sind belastbare SLOs und gelebte Incident‑Runbooks. Für Kachel‑Dienste wirkt ein hoher CDN‑Cache‑Hit direkt auf Latenz und Kosten – designen Sie Header und Cache‑Keys entsprechend Ihrer Kachelpyramiden.
Referenzbeispiel: Sentinel‑2 Pipeline
Ein kompakter Ablauf verbindet Discovery, Katalogisierung, Konvertierung und Bereitstellung:
- Discovery: Suche nach Sentinel‑2‑Items via STAC‑API, z.B. mit einem öffentlichen Dienst.
- Katalogisierung: Erstellen Sie STAC Items/Collections mit PySTAC; tragen Sie EO/Projection‑Extensions für Bänder, CRS und Geometrien ein.
- Konvertierung: Ableiten/Maskieren und als COG schreiben – die OGC COG‑Spezifikation definiert Anforderungen; in der Praxis nutzen Teams GDAL/rio‑cogeo.
- Bereitstellung: Publizieren Sie Tiles über TiTiler oder einen OGC API‑Server; CDN davor, Cache‑Header sauber setzen.
Ein Minimalbeispiel für eine Airflow‑Task, die ein COG erzeugt:
# Vereinfachtes Beispiel: Sentinel-2 Asset zu COG (Pseudo-Code)
gdal_translate -of COG source.tif output_cog.tif
# Overviews und Tiling werden durch COG-Optionen erstellt; prüfen Sie die GDAL-Dokumentation.
Entscheidungsleitfaden und Trade‑offs
- Kosten vs. Latenz: Aggressives Caching und CDN‑Verteilung senken Latenz, treiben aber Speicher/Transferkosten; Lifecycle‑Policies puffern dies.
- Genauigkeit vs. Performance: Höhere Zoom‑Stufen und feinere Raster steigern Präzision, erhöhen aber I/O und CPU; Voraggregationen/Overviews helfen.
- Eigenbau vs. Dienste: Eigene Pipelines bieten Kontrolle, verlangen aber SRE‑Disziplin; Managed‑Dienste beschleunigen Start, binden an Anbieter und Limits.
- Standards vs. proprietär: OGC/STAC/COG sichern Interoperabilität; proprietäre Erweiterungen können Features liefern, riskieren jedoch Lock‑in.
Weiterführende Schritte
Bauen Sie zuerst ein Minimum Viable Platform: klare Datendomänen, STAC‑Kataloge, COG/GeoParquet‑Ablage, ein OGC API‑Tiles‑Dienst vor einem CDN, und SLOs für Freshness und Latenz. Dokumentieren Sie QC‑Regeln, Versionierung und Incident‑Runbooks.
Disclosure: Geneo ist unser Produkt. Für eine praxisorientierte, neutrale Schritt‑für‑Schritt‑Anleitung zum Betrieb von GEO‑Monitoring und Architektur empfehlen wir als weiterführende Lektüre: GEO Monitoring System: Schritt‑für‑Schritt Anleitung und Architektur.



