
Brand Knowledge Graph aufbauen: Schritt-für-Schritt Anleitung
Erstellen Sie einen Brand Knowledge Graph mit praxisnaher Schritt-für-Schritt Anleitung – inklusive Entitäten-Modellierung, Validierung, Monitoring & DSGVO-Check.

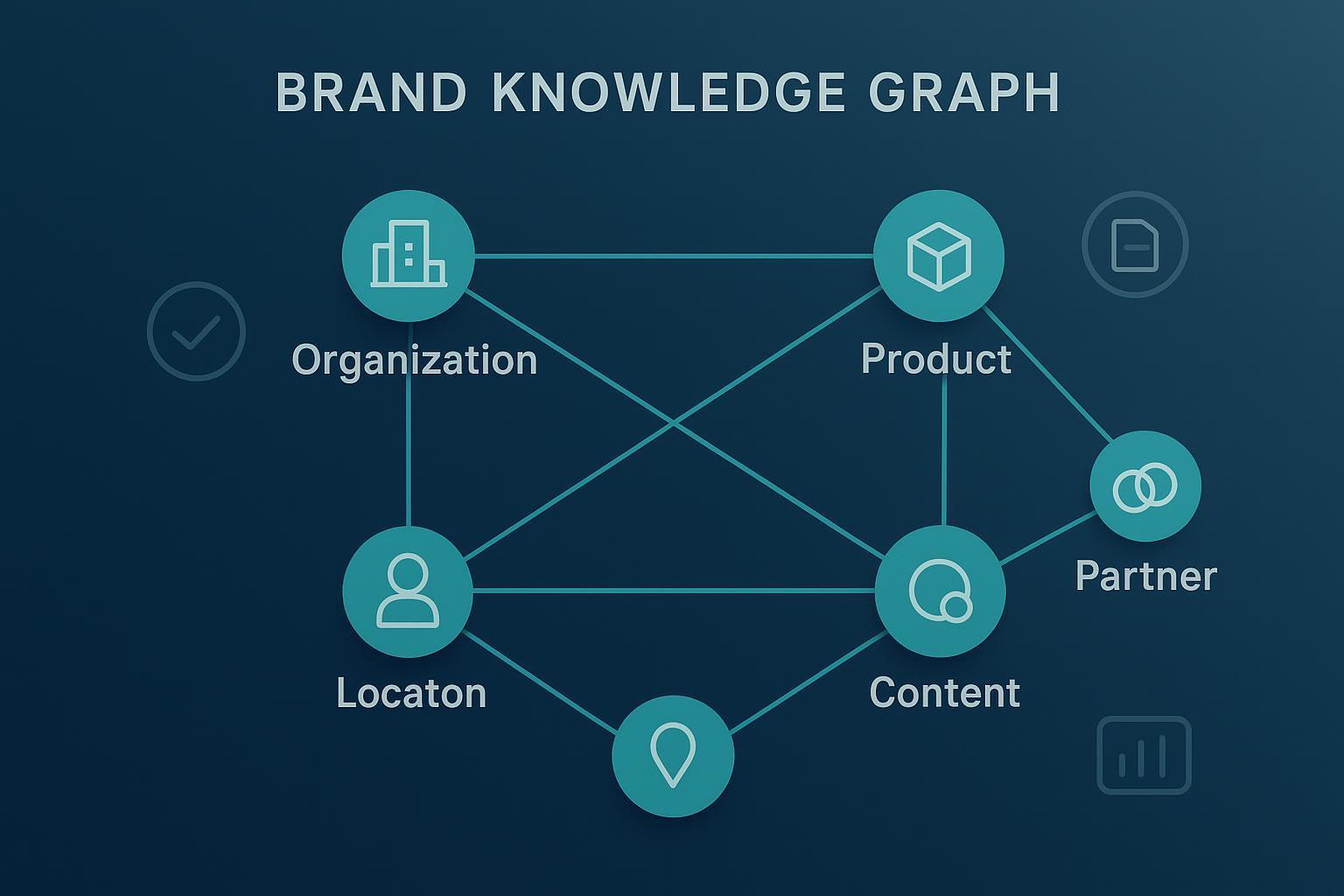
Ein konsistenter Brand Knowledge Graph (KG) verbindet Ihre wichtigsten Markenelemente – Unternehmen, Produkte, Personen, Standorte, Inhalte, Partner – zu einem abfragbaren Wissensnetz. Das bringt Ordnung in Daten‑Silos, stärkt die Sichtbarkeit in KI‑ und Suchoberflächen und verbessert Governance sowie Personalisierung. Oder, kurz gesagt: Er macht Marketingdaten belastbar und nutzbar.
Im Folgenden führe ich Sie Schritt für Schritt von Zielen und Datenquellen über Modellierung, Aufbau, Validierung und Integration bis zu Monitoring, Governance und DSGVO. Zwischendurch finden Sie Copy‑Paste‑Snippets, Checks und typische Stolperfallen.
Grundlagen und Architektur: Was gehört in einen Brand Knowledge Graph?
Ein KG modelliert Entitäten (z. B. Organization, Product, Person) und deren Relationen (brandOf, worksFor, locatedIn). Technischer Unterbau und Zweck der wichtigsten Standards:
| Standard/Vokabular | Zweck im KG |
|---|---|
| RDF/RDFS | Datenmodell/Triples und Basisschema |
| OWL 2 | Logik/Reasoning für Klassen/Beziehungen |
| SKOS | Kontrollierte Vokabulare/Taxonomien |
| SPARQL | Abfragen und Auswertungen |
| SHACL | Validierung gegen „Shapes“/Regeln |
| PROV‑O | Provenienz: Quelle, Zeitpunkt, Lizenz |
Für eine kompakte Einführung in Unternehmens‑KGs empfehle ich den Überblick von Neo4j mit Definition und Szenarien im Beitrag What is a Knowledge Graph? sowie die Enterprise‑Perspektive von SAP in der Ressource Knowledge Graph. Beide liefern den Kontext, warum Marken von verknüpftem Wissen profitieren.
Schritt 1 – Ziele und Scope festlegen
Starten Sie mit klaren, messbaren Use Cases: Sichtbarkeit (einheitliche Entitäten für KI‑Antworten und SERPs), Content‑Governance (kanonische Beziehungen zwischen Marken, Linien, Produkten, Personen) sowie Personalisierung/Analytics (Segmente, Branchen, Features, Kampagnen als verknüpfte Knoten). Definieren Sie parallel, welche Entitäten und Relationen im ersten Scope enthalten sind und welche Metriken den Erfolg messen (Coverage, Accuracy, Konsistenz, Aktualität). Legen Sie fest, welche Referenzen als autoritativ gelten (z. B. Handelsregister, offizielle Socials, Wikidata) und dokumentieren Sie diese Wahl.
Schritt 2 – Ontologie und URIs definieren
Wählen Sie Vokabulare pragmatisch: Für Websichtbarkeit sind schema.org‑Typen zentral; ergänzend eignen sich FOAF, SKOS und ggf. eigene Namensräume. Eine fundierte Einführung in strukturiertes Daten‑Markup bietet die Anleitung Einführung in strukturierte Daten von Google. Entwickeln Sie eine URI‑Strategie mit eindeutigen, kanonischen IDs pro Entität (z. B. https://example.com/#organization, https://example.com/produkte/p123#product) und versionieren Sie Ihr Modell (z. B. v1 → v1.1) nachvollziehbar.
Schritt 3 – Datenquellen kuratieren (intern und extern)
Pflegen Sie eine kuratierte Mischung: intern (CRM, PIM, CMS, Support‑FAQs, Event‑/PR‑Kalender, DAM) und extern (Wikidata, DBpedia, Handelsregister, Branchenverzeichnisse). Für die Websichtbarkeit setzen Sie JSON‑LD auf Ihren Seiten ein und validieren das Markup mit dem Schema Markup Validator sowie dem Google Rich Results Test. Erfassen Sie für jede externe Übernahme Provenienz (Quelle, Zeitpunkt, Lizenz) im KG, idealerweise mittels PROV‑O.
Schritt 4 – Graph aufsetzen (RDF‑Stack oder Neo4j)
Zwei robuste Wege:
- RDF‑First mit Apache Jena/TDB und Fuseki für SPARQL; SHACL‑Validierung integriert. Die Apache‑Jena‑Dokumentation zur SHACL‑Validierung führt durch Einrichtung und CLI.
- Property Graph mit Neo4j und dem Plugin neosemantics (n10s) für Import/Export von RDF/JSON‑LD; der Überblick von Neo4j erklärt, wann dieser Ansatz sinnvoll ist. Für Enterprise‑Integrationen lohnt ein Blick auf Altair Graph Studio.
Mini‑Beispiele:
- n10s Import aus JSON‑LD:
CALL n10s.graphconfig.init();
CALL n10s.rdf.import.fetch("https://example.org/data.jsonld", "JSON-LD");
- SPARQL (Qualitätslücke: Personen ohne Name):
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?entity WHERE {
?entity a foaf:Person .
FILTER NOT EXISTS { ?entity foaf:name ?name }
}
LIMIT 100
Schritt 5 – Web‑Markup mit JSON‑LD (Copy‑Paste‑Vorlagen)
Binden Sie schema.org‑Typen als Script‑Tag im Head oder Body ein. Eine grundlegende Einführung liefert Googles Leitfaden Einführung in strukturierte Daten; die Typseiten bei schema.org sind die maßgebliche Referenz.
- Organization:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://www.example.com/#organization",
"name": "Beispiel GmbH",
"url": "https://www.example.com",
"sameAs": [
"https://www.facebook.com/beispiel",
"https://twitter.com/beispiel",
"https://www.linkedin.com/company/beispiel"
],
"brand": {
"@type": "Brand",
"@id": "https://www.example.com/#brand-beispielmarke",
"name": "Beispielmarke"
}
}
</script>
- Product:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Product",
"@id": "https://www.example.com/produkt123#product",
"name": "Beispielprodukt",
"image": "https://www.example.com/images/produkt123.jpg",
"description": "Ein großartiges Beispielprodukt.",
"brand": {
"@type": "Brand",
"@id": "https://www.example.com/#brand-beispielmarke",
"name": "Beispielmarke"
},
"offers": {
"@type": "Offer",
"price": "19.99",
"priceCurrency": "EUR",
"availability": "https://schema.org/InStock",
"url": "https://www.example.com/produkt123"
}
}
</script>
- Person:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Person",
"@id": "https://www.example.com/#person-john-doe",
"name": "John Doe",
"sameAs": [
"https://www.linkedin.com/in/john-doe",
"https://twitter.com/johndoe"
],
"worksFor": {
"@type": "Organization",
"@id": "https://www.example.com/#organization",
"name": "Beispiel GmbH",
"url": "https://www.example.com"
}
}
</script>
Validieren Sie Ihr Markup mit dem Schema Markup Validator und dem Google Rich Results Test – beide liefern klare Fehlermeldungen und Hinweise auf Pflichtfelder.
Schritt 6 – Validierung mit SHACL und Reasonern
Mit SHACL beschreiben Sie Soll‑Eigenschaften für Knotenklassen und prüfen automatisiert gegen Regeln. Die W3C‑Spezifikation zu SHACL erklärt Konzepte und Beispiele; die Apache‑Jena‑Dokumentation führt die praktische Validierung.
Ein kleines Shape‑Beispiel:
@prefix sh: <http://www.w3.org/ns/shacl#> .
@prefix ex: <http://example.org/ns#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
ex:PersonShape a sh:NodeShape ;
sh:targetClass ex:Person ;
sh:property [ sh:path ex:name ; sh:minCount 1 ; sh:datatype xsd:string ] ;
sh:property [ sh:path ex:age ; sh:datatype xsd:integer ; sh:minInclusive 0 ] .
CLI‑Validierung:
shacl validate --data data.ttl --shapes shapes.ttl --out report.ttl
Reasoner wie HermiT oder Pellet ergänzen Konsistenzprüfungen und leiten implizite Aussagen her – nützlich, um Modellierungsfehler aufzuspüren.
Schritt 7 – Integration und Entity Resolution
Führen Sie doppelte/ähnliche Entitäten über stabile, kanonische IDs zusammen und setzen Sie owl:sameAs sorgfältig. Verlinken Sie externe Knoten (Wikidata, DBpedia) erst nach überprüfter Übereinstimmung und dokumentieren Sie Provenienz mit PROV‑O (Quelle, Zeitpunkt, Lizenz, erzeugende Aktivität/Agent). Normalisieren Sie Namen, Datentypen, Datumsformate und Sprachen konsequent.
Kleiner SPARQL‑Check für fehlende Identitätslinks:
PREFIX owl: <http://www.w3.org/2002/07/owl#>
SELECT ?entity WHERE {
?entity a <http://schema.org/Person> .
FILTER NOT EXISTS { ?entity owl:sameAs ?sameAs }
}
LIMIT 100
Schritt 8 – Monitoring und Aktualisierung (inkl. AI‑Antwortoberflächen)
Richten Sie wiederkehrendes Monitoring ein und halten Sie Ihren KG in Bewegung. Messen Sie Coverage (Abdeckung), Accuracy (Korrektheit), Konsistenz und Aktualität; bauen Sie SPARQL‑Reports zu Pflichtfeldern, Widersprüchen und Verwaisungen sowie ein Änderungslog. Nutzen Sie inkrementelle Updates mit Zeitstempeln und Re‑Validierung nach jedem Import.
Beobachten Sie zudem KI‑Answer‑UIs: Welche Entitäten/Beziehungen erscheinen, welche Quellen werden zitiert, welches Sentiment dominiert? Ein aktueller Trendbeitrag von PingCAP (2025) beleuchtet die Verbindung von Knowledge Graphs und ML in Machine Learning and Knowledge Graphs.
Praktisches Beispiel: Disclosure: Geneo ist unser Produkt. Sie können Geneo verwenden, um Marken‑Erwähnungen samt Quelle und Sentiment über Chat‑/Answer‑Plattformen zu erfassen und als Knoten „Erwähnung“ mit Kanten zur „Antwortquelle“ in Ihren KG zu integrieren. So entsteht ein auswertbarer Feedback‑Layer. Für Messgrößen von KI‑Antworten siehe den Leitfaden LLMO Metrics: Measuring Accuracy, Relevance, Personalization in AI Answers. Für teamweite Aktivierung und Sichtbarkeit empfiehlt sich zudem der Beitrag LinkedIn Team Branding for AI Search Visibility: 2025 Best Practices. Und wenn Sie die Konvergenz von SERP‑Monitoring und AI‑Sichtbarkeit einordnen möchten, hilft der Überblick Google Algorithm Update October 2025: No Confirmed Update but AI Visibility Monitoring.
Schritt 9 – Governance und DSGVO‑Compliance
Definieren Sie Rollen (Data/Graph Engineering für Schema, SHACL, Pipelines; SEO/Brand für Kanonisierung, sameAs‑Profile, Monitoring; Legal/Privacy für Rechtsgrundlagen, AV‑Verträge, Löschkonzepte) und Prozesse (Change‑Requests, Ontologie‑Board, Versionskontrolle, Dokumentation der Mappings und Entitäten‑Register). Beachten Sie DSGVO‑Grundsätze wie Datenminimierung, Rechtsgrundlagen nach Art. 6, Betroffenenrechte nach Art. 12–23, Löschung nach Art. 17 sowie technische und organisatorische Maßnahmen nach Art. 32. Der konsolidierte Rechtsrahmen steht bei EUR‑Lex; Auslegungsleitlinien veröffentlicht der EDSA/EDPB im Guidelines‑Hub.
Kompakte Checkliste:
- Rechtsgrundlage dokumentiert und Rollen-/Zugriffskonzepte aktiv?
- Provenienz (PROV‑O) gesetzt und Quell‑Lizenz geprüft?
- SHACL‑Report ohne kritische Violations und Reasoner‑Konsistenz gegeben?
Troubleshooting: Häufige Fehler – schnelle Lösungen
- Fehlende oder wechselnde @id: Verwenden Sie stabile, kanonische URIs; Empfehlungen finden Sie im schema.org‑Getting‑Started und in Googles Einführung in strukturierte Daten.
- Inkonsistente sameAs‑Links: Nur offizielle, autoritative Profile verlinken; regelmäßige Reviews einplanen.
- Pflichtfelder fehlen: Nutzen Sie den Schema Markup Validator sowie den Rich Results Test; ergänzen Sie SHACL‑Regeln für Pflichtangaben.
- Typfehler in JSON‑LD: Validatoren in die CI einbinden; vermeiden Sie Mischformen (Microdata/RDFa/JSON‑LD gleichzeitig).
- Widersprüche zwischen sichtbarem Content und Markup: Redaktions‑QA vor Release; halten Sie sich an die Richtlinie für strukturierten Inhalt von Google.
Ein Brand Knowledge Graph ist kein Einmal‑Projekt, sondern ein System. Der Weg führt von sauberer Zielsetzung und Ontologie über kuratierte Daten, robusten Aufbau und strenge Validierung bis hin zu Monitoring, Governance und Datenschutz. Wenn Sie klein anfangen, konsistent versionieren und Ihre Qualität regelmäßig messen, wächst der Graph gesund – und Ihre Marke wird in KI‑ und Such‑Umgebungen eindeutiger verstanden. Anders gesagt: Erst Struktur, dann Sichtbarkeit. Los geht’s.



