
AI-gestützte Entitätsprüfung: Wie KI Web-Entitäten abgleicht
Erfahre, wie KI Web-Entitäten über Quellen prüft, strukturiert verifiziert und Knowledge Graphs, schema.org sowie Wikidata nutzt.

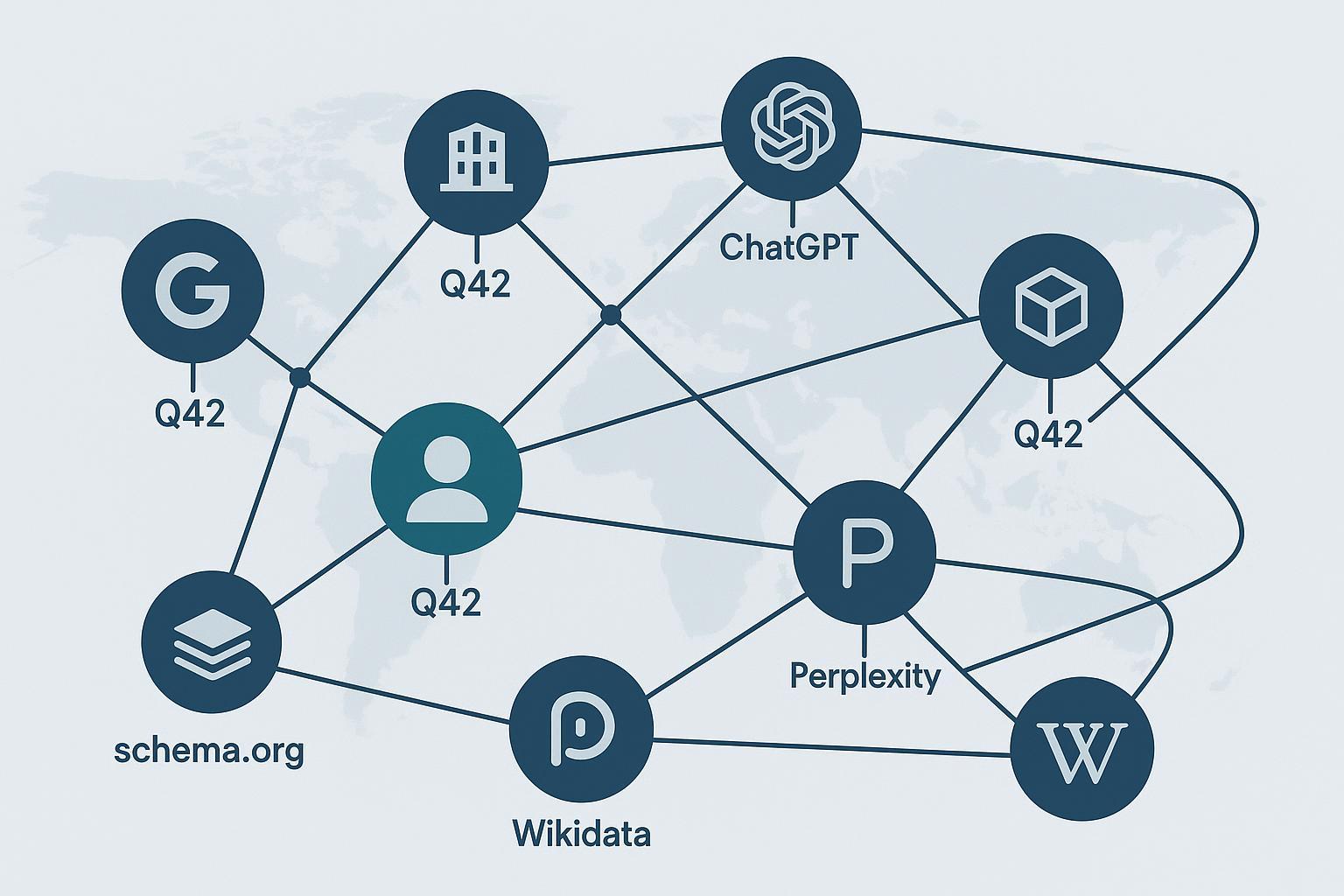
KIs beantworten heute Fragen, fassen Inhalte zusammen und verweisen auf Quellen. Damit Antworten konsistent und zitierbar sind, müssen die Systeme Entitäten – Personen, Organisationen, Produkte, Orte – über verschiedene Quellen hinweg erkennen, abgleichen und verifizieren. Genau das leistet die AI-gestützte Entitätsprüfung: Sie verbindet Textsignale mit Knowledge Graphs, strukturierten Daten und offiziellen Identifikatoren, um Eindeutigkeit herzustellen und Verwechslungen zu minimieren.
Abgrenzungen und Kernprinzipien
Entität bezeichnet ein eindeutig identifizierbares „Ding“, das in Wissensbasen (z. B. Wikidata) mit stabilen IDs repräsentiert wird. Zwei verwandte, aber unterschiedliche Aufgaben sind wichtig:
- Entity Linking (EL) ordnet Erwähnungen in Texten einem kanonischen Eintrag in einer Wissensbasis zu (typisch: NER → Kandidaten → Kontext-Disambiguierung → Link-Entscheidung). Moderne Pipelines kombinieren symbolische und embedding-basierte Verfahren.
- Entity Resolution (ER) führt verteilte Datensätze zusammen, die dieselbe reale Entität beschreiben, trotz Schreibvarianten oder fehlenden IDs – Ziel ist ein „Golden Record“. Eine umfassende Übersicht zu ER-Verfahren (Record Linkage, Fuzzy-Matching, graphbasierte Ansätze) liefert die Arbeit in Science Advances (2022), siehe die „Entity resolution“-Übersicht (Science, 2022).
Knowledge Graph Alignment bezeichnet den Abgleich von Knoten und Kanten zwischen Graphen (z. B. interne IDs ↔ Wikidata Q-IDs). Dabei geht es um Eindeutigkeits- und Konsistenzprüfungen über Attribute und Beziehungen.
RAG-gestützte Verifikation (Retrieval-Augmented Generation) kombiniert Abruf und Generierung. Vor der Antwort werden Belege geladen, referenziert und auf Autorität, Aktualität und Übereinstimmung geprüft; erst dann dient das Material als Grounding.
Signal-Ökosystem für maschinenlesbare Identität
schema.org: sameAs und Identitätsverknüpfung
Die Property sameAs verlinkt auf eine Referenz-Webseite, die die Identität eines Items eindeutig angibt (z. B. Wikipedia, Wikidata, offizielle Profile). Die Definition ist auf Schema.org dokumentiert; siehe die Typseiten wie Organization und die generelle Beschreibung von sameAs. Konsequenz: Sauber gepflegte sameAs-Verknüpfungen erhöhen die Chance, dass KI-Systeme Entitäten korrekt disambiguieren und zusammenführen.
Wikidata: Q-IDs und externe Bezeichner
Jede Entität besitzt eine stabile Q-ID (z. B. Q42). Über Properties werden weitere Register angebunden (etwa GND, IMDb). Die Community dokumentiert bewährte Methoden zu Identifiers und Referenzen (P248 „stated in“), vgl. Wikidata:Identifiers. Think of it this way: Eine Q-ID ist wie eine Passnummer – sie macht eine Entität über Systeme hinweg eindeutig adressierbar.
JSON-LD-Beispiel (Organization mit sameAs/Q-ID)
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://example.com/#org",
"name": "Beispiel GmbH",
"url": "https://example.com/",
"sameAs": [
"https://www.wikidata.org/wiki/Q123456",
"https://de.wikipedia.org/wiki/Beispiel_GmbH",
"https://www.linkedin.com/company/beispiel"
],
"publishingPrinciples": "https://example.com/publishing-principles"
}
Validieren Sie das Markup und halten Sie es mit den sichtbaren Inhalten auf der Seite konsistent.
Prüfpfade in KI-Systemen (öffentlich dokumentierte Aspekte)
Google AI Overviews: strukturierte Daten und Links
Google beschreibt AI Overviews als generative Zusammenfassungen, die Nutzer mit weiterführenden Links versorgen. Die offiziellen Hinweise betonen, dass strukturierte Daten maschinenlesbare Informationen liefern, die Systeme berücksichtigen. Details finden sich im Search Central-Beitrag „AI-Funktionen und deine Website“ (Google Developers) und im Update „Succeeding in AI search“ (Google, 2025).
Transparenz & Zitationen in Plattformen
Plattformen wie Perplexity heben die Zitationsanzeige hervor: Antworten enthalten Links zu Originalquellen; vgl. die Perplexity-Hilfe: Funktionsweise und Zitationen. OpenAI kommuniziert, dass bestimmte Modi (z. B. Deep Research) Quellen/Links bereitstellen können; siehe OpenAI Deep Research: Transparente Recherchemodi. Die genaue interne Ranking- oder Zitierlogik ist nicht öffentlich dokumentiert – daher bleiben Aussagen hier bewusst allgemein. Warum ist das wichtig? Weil Teams nur auf verifizierte, veröffentlichte Hinweise bauen sollten und interne Heuristiken nicht voraussetzen dürfen.
Graph-basierte Vektorsuche und Hybrid-Retrieval
Eine aktuelle Arbeit (2025) klassifiziert Design-Paradigmen für graphbasierte Vektorsuche und zeigt, wie Hybrid-Retrieval (Vektor + Graph) Kandidatenbildung und Re-Ranking verbessert – relevant für Entity-Abgleich und konsistente Antworten. Siehe „Graph-based Vector Search: Design Paradigms“ (arXiv, 2025).
Praxis: Implementierungsschritte und Qualitätssicherung
- Audit der maschinenlesbaren Identität: Welche Entitäten (Organization, Person, Product) sind vorhanden? Sind Profile/IDs konsistent (Website, Social, Wikidata, Wikipedia, Branchenregister)?
- Markup ergänzen und konsolidieren: JSON-LD für Organization/Person/Article, inklusive sameAs, Byline/Bio, Publisher, publishingPrinciples. Prüfen, ob Autoren auch als Person mit IDs (z. B. ORCID, Wikidata) ausgezeichnet sind.
- Offizielle IDs pflegen: Wikidata-Einträge mit Q-IDs und externen Identifiers sauber halten; Referenzen (P248) hinzufügen, um Downstream-Nutzung zu verbessern.
- Validierung & Konsistenz: Rich Results Test/Validator nutzen; Abgleich zwischen sichtbarem Content und Markup sicherstellen; Wording- und Namensvarianten vereinheitlichen.
- Kontextsignale stärken: Interne Linkkarte (Autorenseiten, Organisation, Themencluster), klare Überschriften, präzise Definitionen. Ein konsistentes semantisches Umfeld erleichtert Disambiguierung.
Monitoring & Korrektur-Workflows
Knowledge Panels: Claim/Korrektur und Quellen-Footprint
Branchenbeiträge raten zu einem konsistenten, autoritativen Footprint (Wikidata, Wikipedia, offizielle Website, Social/Branchenseiten). Panels lassen sich claimen/verifizieren, Änderungen erfolgen über Feedback-Pfade; die finale Entscheidung liegt bei Google. Vgl. How to optimize your company’s Google knowledge panel (Search Engine Land, 2025).
Reconciliation mit OpenRefine/Wikidata
Für Datenteams ist OpenRefine ein praktischer Weg, Entitäten mit Wikidata abzugleichen, Werte/Identifiers zu übernehmen und bei Mehrfachwerten korrekt zu aggregieren. Siehe Survey und Forenbeiträge, z. B. den OpenRefine Survey 2024.
KPIs für AI-Entity-Visibility
Für Marketing/SEO-Teams helfen KPIs wie „Performance by Entity“, „Ambiguity Rate“ und „Share of Voice in AI-Antworten“. Eine Begriffsklärung und Metrikbeispiele liefert der Geneo-Artikel zu AI Visibility, siehe Definition von AI Visibility und Messansätze.
Mini-Workflow-Beispiel (neutral, replizierbar)
Disclosure: Geneo ist unser Produkt. In der Praxis können Teams Antworten und Zitationspfade auf ChatGPT, Google AI Overviews und Perplexity regelmäßig prüfen. Ein möglicher, toolgestützter Ablauf:
- Wöchentliches Sampling von Fragen/Prompts je Plattform; Evidence-Logs mit den verlinkten Quellen anlegen.
- Abgleich der genannten Entitäten gegen die eigene Identitätskarte (Website, Wikidata Q-IDs, sameAs-Profile); Abweichungen markieren.
- Korrekturmaßnahmen priorisieren: Markup-Fehler beheben, Wikidata-Referenzen ergänzen, Autoren-IDs pflegen.
- Fortschritt tracken (Visibility-Score, Zitationsanzahl, Sentiment). Eine ausführliche Workflow-Beschreibung finden Sie im Review-Artikel, siehe Geneo Review: AI-Sichtbarkeit tracken. Für Schritte zur Verbesserung von Zitationen in generativer Suche siehe Leitfaden: Content für AI-Citations optimieren.
Fazit
AI-gestützte Entitätsprüfung bringt Ordnung in heterogene Websignale: Durch strukturierte Daten, offizielle IDs und Graph-Alignment werden Entitäten eindeutig und Antworten belastbar. Wer Markup konsistent pflegt, Wikidata sauber führt und Monitoring/Feedback-Schleifen etabliert, reduziert Verwechslungen und erhöht korrekte Marken-Nennungen – quer über Google AI Overviews, ChatGPT und Perplexity. Der nächste Schritt? Prüfen Sie Ihre maschinenlesbare Identität, setzen Sie die JSON-LD-Basics um und starten Sie ein leichtgewichtes Monitoring – kleine, stetige Verbesserungen zahlen sich aus.



