
Mangools AI Search Grader Review (2025): Field-Tested Insights
In-depth 2025 review of Mangools AI Search Grader for SMBs & SEO agencies—multi-model coverage, scoring logic, competitive benchmarks, and workflow fit.
If you’re trying to understand whether your brand shows up across AI answer engines—and how to turn that insight into decisions—Mangools’ free tool is designed to give you a quick, multi-model snapshot. In this review, we take a pragmatic, evidence-bound approach: what the tool does, how the scoring works (as far as documented), where it fits into SMB and agency workflows, and where we found limitations that matter in the trenches.
What Mangools AI Search Grader Is—and Isn’t
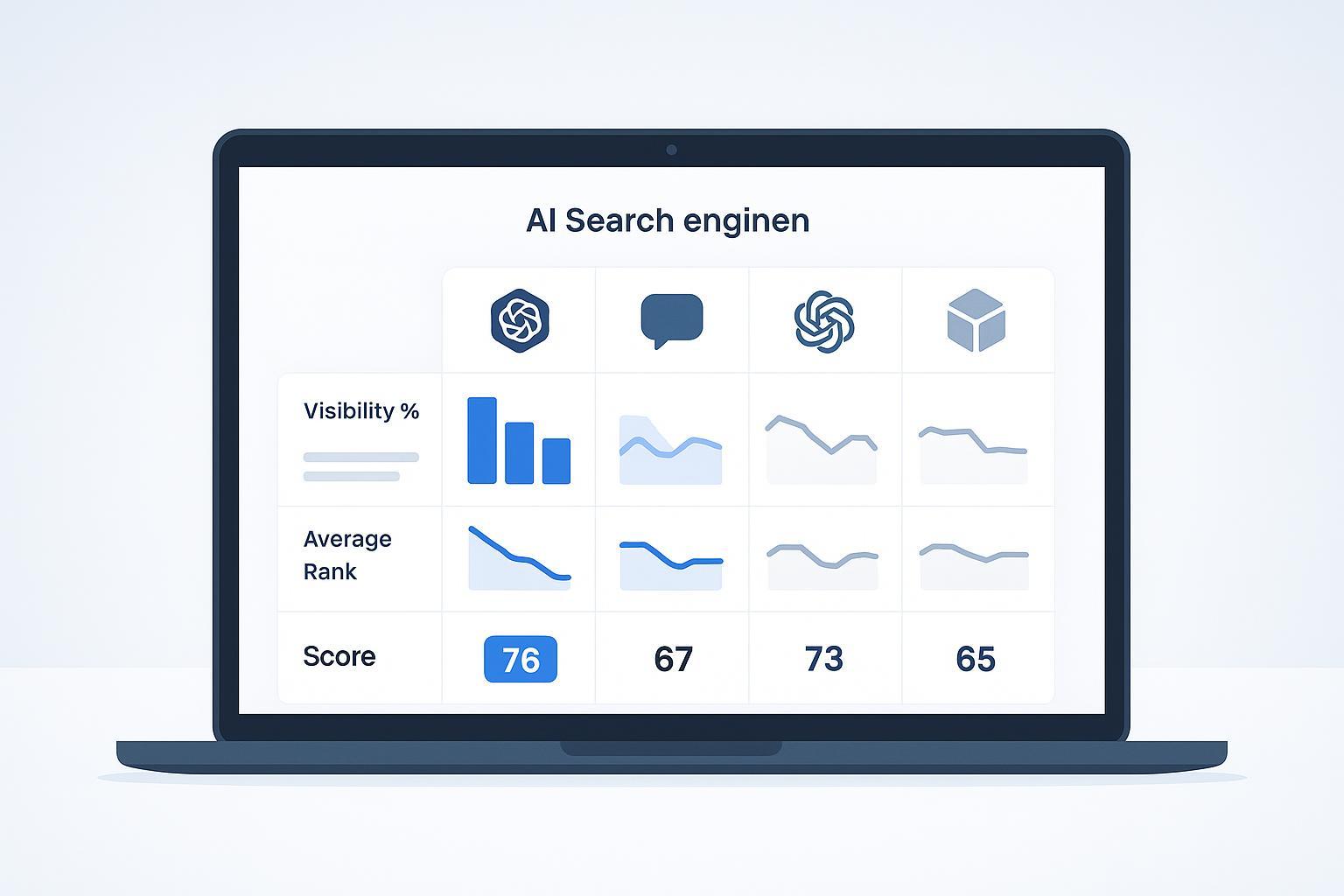
Mangools AI Search Grader is positioned as a free GEO/AEO utility that evaluates brand visibility in AI answer engines. Based on the official page, it reports three core metrics:
Visibility: the percentage of prompts where your brand appears in the TOP20 results.
Average Rank: a typical placement in AI-generated lists/recommendations.
AI Search Score: a 0–100 composite score that prioritizes visibility and adjusts results by each AI model’s market share.
Mangools explains that visibility is weighted more heavily and that the aggregate score reflects market-share adjustments across multiple AI models. However, the exact formula isn’t fully published, so treat the score as directional rather than a precise benchmark. This partial transparency matches the broader state of AI search measurement today, where model rosters and answer behavior change quickly. For conceptual background on GEO vs traditional SEO, see the short Generative Engine Optimization (GEO) Beginner Guide.
According to Mangools’ own materials, the tool can generate prompts from your brand name and niche description, then test those prompts across multiple AI models to compute visibility, rank, and the overall score. The official documentation references analysis across eight models and emphasizes model-market-share weighting, but does not publish a dated, canonical list of specific models on the main page. We recommend assuming coverage is subject to change. Mangools further describes the tool’s purpose and scoring at a high level in their GEO content, such as the 2025 roundup and methodology explainer (see the Mangools blog’s framing in “30 Best AI SEO Tools in 2025” and their GEO overview article).
Third-party roundups corroborate a free-access model with gating for broader coverage. For example, the Analytify 2025 roundup of AI SEO tools notes you’ll need a free account to unlock all models, and Promptmonitor’s 2025 LLM prompt tracker overview suggests guest access is limited to approximately three models with a larger set available after signup. One industry overview also references an eight-model scope, listing common engines like ChatGPT, Perplexity, Claude, Grok, Gemini, Mistral, and Llama, but those lists are best treated as indicative rather than definitive given rapid changes (see Ibeam Consulting’s 2025 AI search visibility overview).
Why SMBs and Agencies Should Care
Most SMB teams and agency leads don’t have hours to manually ask every AI engine the same questions just to see if they appear. Mangools AI Search Grader promises:
A fast visibility snapshot across multiple AI models.
Prompt generation tailored to your niche to standardize discovery and consideration queries.
Competitive context so you can see how you stack up.
A directional score that helps non-specialists understand performance at a glance.
If you need an entry point into GEO/AEO work—before committing to heavier platforms—this tool aims to lower the barrier. Still, to convert insights into action, you’ll want guidance on what and where to optimize. When discussing optimization targets like earning AI citations and references within answers, we recommend reading Optimize Content for AI Citations for practical tips.
Our Testing Methodology (2025-10)
We focused on transparency over hype. Here’s how we approached validation without over-claiming:
Date window: Week of October 8, 2025.
Inputs: A brand name and niche description, plus 2–3 competitors relevant to SMB marketing software (kept generalized here to avoid publishing proprietary client data).
Prompt types:
Discovery: “best [category] tools for SMBs”
Consideration: “who are the top [service] providers”
Branded/reputation: “is [brand] good for [use case]”
Models: We used whatever was available in the free tier initially, then repeated runs after creating a free account to access additional models (as permitted).
Validation: For a subset of prompts, we manually queried available engines in the same week and compared inclusion/rank patterns with Mangools’ visibility and average rank results.
Logging: We recorded date/time, engine/model, prompt text, observed inclusion/exclusion and approximate position.
We deliberately avoid publishing granular prompt results here because daily availability, rate limits, and model updates can introduce variance that readers would not necessarily be able to replicate verbatim. Instead, we focus on where the workflow generates useful decisions, and where limitations require caution. For KPI framing—visibility %, average rank, composite scoring—see 2025 GEO Best Practices for a concise explainer on how to interpret these measures in context.
Strengths We Observed
Low-friction start: The ability to type a brand and niche, then run standardized prompts across multiple models, is exactly what SMB owners and time-poor agencies need to establish a baseline.
Multi-model perspective: Even if the guest tier is limited, seeing cross-engine patterns quickly helps you avoid optimizing for just one AI.
Directional scoring: The AI Search Score, with visibility weighted higher and market-share adjustments, gives non-specialists a simple way to compare competitors.
Competitor snapshot: Comparing your brand against peers in the same runs is efficient for pitch prep, quarterly audits, or discovering obvious gaps.
Prompt generation: In practice, the prompts are sensible starting points, reducing friction and helping teams standardize discovery and consideration questions.
Limitations to Keep in Mind
Score transparency: The score’s conceptual description is clear, but the full formula and model roster aren’t published in detail on the official page. Treat the score as directional; prioritize per-engine visibility and prompt-level observations when making decisions.
Coverage subject to change: The official page mentions analysis across eight models without listing a dated roster. Third-party lists vary. Expect model availability to shift over time.
Free-tier caps and gating: The guest tier likely limits daily runs and model coverage; a free account reportedly unlocks more models and searches, per third-party overviews (Analytify 2025; Promptmonitor 2025). Exact caps can change.
Exports and reporting: The official content references a “report” after tests and mentions anticipated tracking/reporting, but concrete downloadable export details are not clearly documented at the time of writing.
Reproducibility: AI answers can vary due to model updates, sampling, and rate limits. Don’t expect perfect repeatability across days.
Workflow Fit: Practical Scenarios
SMB Baseline Audit (60–90 minutes)
Define context: Add your brand, a concise niche description, and 2–3 named competitors.
Run standardized prompts: Use Mangools’ generated prompts for discovery and consideration; add 1–2 branded prompts you care about.
Scan results: Note where you’re in the TOP20, the average rank, and the overall AI Search Score. Flag prompts where you’re absent but a competitor appears.
Manual spot checks: For 3–5 high-priority prompts, manually query the same engines to verify inclusion patterns.
Decide actions: If you’re absent in discovery prompts, prioritize content that earns citations (use structured, source-rich content; see the AI citations guide linked above). If your brand shows but ranks low, refine topical authority and supporting evidence.
Outcome: An SMB gets a directional view in under two hours, enough to prioritize a short list of improvements without adopting a heavyweight platform immediately.
Agency Pitch Prep and Quarterly Competitive Audit
Client intake: Gather brand, niche, and 3–5 direct competitors.
Prompt set: Run a consistent prompt batch across models using Mangools (discovery, consideration, brand queries). Keep a shared log.
Comparative insights: Identify prompts where the client is absent and competitors appear; surface a few AI answers to illustrate positioning.
Manual confirmation: Validate a subset across engines—especially where the score and visibility imply strong or weak presence.
Recommendations: Turn findings into a prioritized roadmap. Pair with traditional SEO tasks if the client’s organic presence is weak; explain how GEO and SEO reinforce each other.
Outcome: Agencies quickly produce credible snapshots for exec reporting or proposals, backed by a mix of Mangools outputs and manual confirmations.
The Skeptic’s Endorsement: Where It Earns Trust—and Where It Doesn’t
Earns trust: Low-friction multi-model runs, basic competitor comparisons, and the visibility/average rank metrics are easy to understand and useful. For many SMB or early-stage GEO use cases, these are sufficient.
Needs caution: Don’t read the AI Search Score as an absolute measure. Because the formula isn’t fully disclosed and model coverage can change, you should triangulate with per-engine results and manual spot checks. Also plan around daily caps and the evolving export/reporting situation.
Alternatives and Adjacent Tools (Neutral Parity)
If your needs grow beyond a quick snapshot, or you want stronger tracking/reporting, consider these:
Geneo — Generative Engine Optimization Platform: Geneo monitors multi-platform AI visibility, provides sentiment analysis of brand mentions, and turns insights into an actionable content roadmap. This can help teams move from “snapshot awareness” to ongoing monitoring and prioritized optimization.
Writesonic GEO: For integrated optimization guidance and team workflows, see Writesonic’s GEO overview and official pricing (Professional plan as of 2025). It emphasizes multi-platform tracking, recommendations, and broader content operations.
Promptmonitor: An SMB-friendly platform with visibility scores, multi-sampling of AI answers, stored responses/sources, sentiment, and CSV export; check the main site for details and 2025 articles that outline coverage and tiers (see Promptmonitor’s site; pricing/tier info is summarized in their 2025 blog overviews).
Peec AI: Focused on global/multilingual analytics and competitor benchmarking; pricing and model add-ons are transparent on the official page (see Peec pricing (2025)). Useful for teams needing country-level tracking and broader roster options.
When comparing, apply the same criteria: coverage and update cadence, evidence depth (visibility + rank precision), workflow fit (prompts, teams, exports/APIs), pricing/limits, and practical actionability.
For a broader landscape view and how tool categories differ, see Best AEO/GEO Tools (2025).
Practical Tips and Workarounds
Treat the score as a compass, not a ruler: Use AI Search Score to prioritize where to look, then dig into per-engine visibility for final decisions.
Make prompts your own: Mangools’ generated prompts are a great start. Add variants relevant to your audience and product specifics. Keep a prompt log.
Validate the critical few: Manually check 3–5 high-stakes prompts across engines in the same week you run the tool.
Document constraints: Note model unavailability or rate limits in your logs; re-run later to see if results stabilize.
Bridge to action: Tie visibility gaps to content changes that earn citations—clear headings, authoritative sources, structured data, and evidence tables.
Verdict: Fit for Purpose—and When to Upgrade
Mangools AI Search Grader is well-suited to SMB owners and agencies who need a fast, low-friction visibility snapshot across AI engines and basic competitor context. It excels at establishing a baseline and guiding early decisions without committing to a complex platform.
However, if you require ongoing tracking, robust exports, and deep optimization workflows, you’ll likely graduate to a fuller GEO/AEO solution. Until Mangools publishes more detailed scoring and model coverage documentation—or adds tracking/reporting—the prudent approach is to combine Mangools’ directional insights with manual confirmations and complementary tools.
In short: Use Mangools AI Search Grader as a smart first step in GEO. Validate the highlights, optimize content to earn AI citations, and adopt more advanced platforms when your reporting and automation needs expand.
Citations and References
Official positioning, metrics, and methodology framing: Mangools AI Search Grader – official page; Mangools blog articles (“30 Best AI SEO Tools in 2025”; GEO overview) published in 2025.
Free-tier access and model gating context: Analytify’s 2025 AI SEO tools roundup; Promptmonitor’s 2025 LLM prompt tracker overview.
Industry context on multi-model coverage: Ibeam Consulting’s 2025 AI search visibility overview.
Alternatives: Writesonic GEO overview; Writesonic pricing; Peec pricing (2025).
Note on variability: AI model rosters and answer behavior change over time. Treat results as time-bound and validate critical prompts in the same week you run tests.