
How AI Models Rank Content Without a Web Index
Explore how AI models rank and cite content without a web index. Learn the retrieval, reranking, and synthesis process with platform tips.
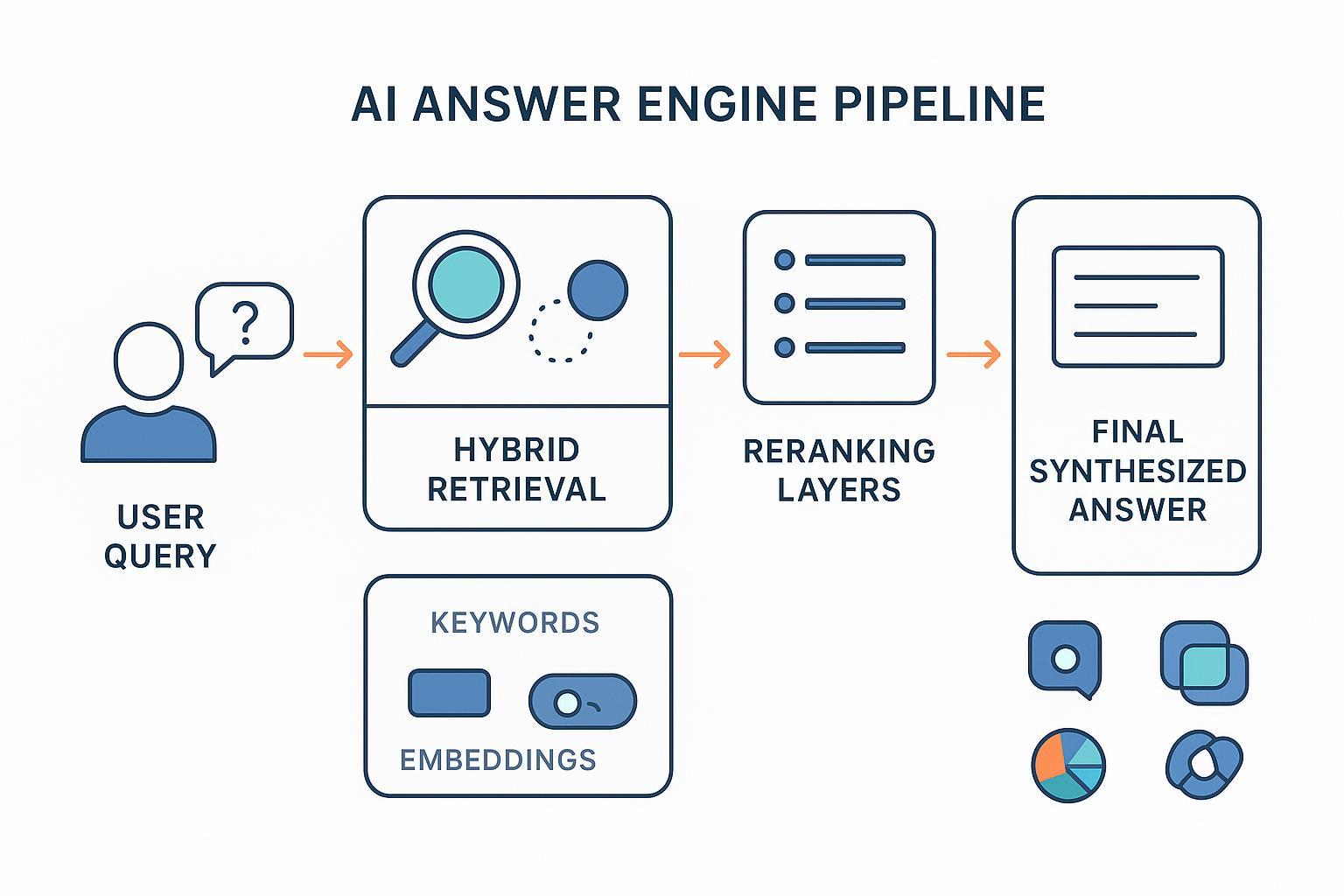
What if “rankings” weren’t precomputed at all—but assembled on the fly, answer by answer? That’s the shift behind AI answer engines like Google AI Overviews, Perplexity, ChatGPT with browsing/search, and Microsoft Copilot. They don’t depend on one monolithic, static web index to decide who’s on top. Instead, they retrieve fresh passages at query time, rerank them with neural models, and synthesize a grounded response with a handful of citations.
In other words, “without a web index” doesn’t mean “no indexing anywhere.” It means the decisive work happens at answer time: dynamic retrieval, multi‑stage reranking, and careful citation selection, rather than a single inverted index determining a fixed order of blue links.
What “without a web index” really means
Classical search is built around a universal inverted index and link graph, updated on a crawl cycle. AI answer engines still use indices (including vertical or lightweight caches), but the ranking you see emerges during the session. Think of it like asking a research librarian: they don’t hand you a pre-ranked list from last month’s shelf—they run down the stacks right now, pull the best chapters, compare them, and then explain the answer while pointing to the sources.
The pipeline that creates “ranking” at answer time
At a high level, most systems follow a similar arc from question to cited answer:
- Query understanding and fan‑out
- Hybrid retrieval (lexical + dense)
- Multi‑stage reranking and filtering
- Citation selection and anchoring
- Freshness, authority, and safety checks
- Synthesis with guardrails
1) Query understanding and fan‑out
Engines often rewrite or decompose your question into sub‑queries to cover facets, entities, and constraints. Google describes “query fan‑out,” issuing related searches across subtopics so it can compose an overview with links people can explore. According to Google’s Generative AI in Search (2024), AI Overviews are designed to provide a concise synthesis alongside source links so people can “learn more” from the web, not replace it entirely. See Google’s explanation in the product blog: Generative AI in Search (2024).
2) Hybrid retrieval (lexical + dense)
Candidate passages are recalled with a blend of keyword‑based methods (e.g., BM25) and semantic vector retrieval (embeddings). This hybrid approach reduces vocabulary mismatch and improves conceptual matches. A 2025 research survey summarizes why hybrid retrieval and external knowledge grounding improve factuality in RAG systems; see the academic overview: RAG and LLM‑as‑judge survey (2025).
3) Multi‑stage reranking and filtering
After recall, engines apply neural rerankers (e.g., cross‑encoders) or even “LLM‑as‑judge” passes to score evidence quality and topic fit. These layers prune noisy or off‑topic material and prioritize the best paragraph‑level matches. De‑duplication and diversity controls help avoid a “single‑source monoculture.”
4) Citation selection and anchoring
Next, the system selects a small set of representative sources and tries to anchor key claims to specific snippets. Different engines render citations differently (numbered footnotes, inline links, cards), but the goal is similar: ground the synthesis in verifiable passages.
5) Freshness, authority, and safety checks
Time‑aware boosts, trust policies, and safety filters shape which candidates survive. Recency matters more for newsy or fast‑moving topics. Authority signals (organizational trust, author credentials, original data) make it easier for a model to justify citing your page.
6) Synthesis with guardrails
Finally, the LLM composes a concise answer constrained by the retrieved evidence and platform policies. OpenAI notes that ChatGPT Search provides answers with links to the sources it consulted to increase transparency; see the announcement: Introducing ChatGPT Search (2025). Perplexity positions itself as citation‑first, and its Deep Research runs many sub‑queries and compiles fully cited reports; see Perplexity Deep Research. Microsoft frames Copilot as retrieval‑augmented, often presenting source links in responses; see the product overview: Microsoft Copilot.
How platforms differ in practice
Behaviors vary by query type, freshness needs, and safety rules. Still, some tendencies show up repeatedly in public materials and comparative studies.
| Engine | Retrieval source(s) | Citation style | Notable tendencies |
|---|---|---|---|
| Google AI Overviews | Google Search index + query fan‑out | Links below or alongside the overview | Conservative citation count; leans toward established sources; freshness matters for newsy queries. See Google’s product description (2024) above. |
| Perplexity | Live web retrieval with iterative sub‑queries | Inline numbered citations and fully cited reports | Citation‑first; willing to include forums/niche sources for long‑tail topics. See Deep Research post linked above. |
| ChatGPT (Search/Browsing) | Real‑time web access when enabled | Inline links to consulted sources | Cites a small set of sources; behavior varies by query and mode. See OpenAI’s announcement (2025). |
| Microsoft Copilot | Bing retrieval + LLM synthesis | Prominent source links in responses | Short, direct answers; citation presence is common in web‑grounded responses. See Microsoft’s Copilot page. |
External observers echo some of these patterns. For example, SE Ranking’s 2025 comparison across ChatGPT, Perplexity, Google AI Overviews, and Bing Copilot reports systematic differences in citation richness and source types (SE Ranking comparison, 2025). ClickGuard’s 2025 analysis suggests AI Overviews frequently cite Reddit, YouTube, Quora, and LinkedIn for certain queries, indicating a community and video tilt (ClickGuard analysis, 2025). Treat these as directional, not universal; methodologies and query sets differ.
What you can influence: a practical optimization checklist
-
Structure for passage‑level recall. Use clear H2/H3s, brief Q&A sections, and concise paragraphs. Make claim sentences self‑contained so they’re easy to quote. For broader context on why this matters for brand exposure, see our explainer: What Is AI Visibility?.
-
Strengthen authority and verifiability. Cite primary data and standards; add author bios and org‑level trust signals. Make it obvious why your page is safe to cite.
-
Maximize clarity and coverage. Name entities, include precise numbers, and cover constraints so query fan‑out still finds complete answers on your page. For prompt‑level differences across engines, see this review: Peec AI Review 2025: Prompt‑Level Visibility.
-
Add machine‑readable cues. Use appropriate schema (FAQ, HowTo, Article/NewsArticle, TechArticle, Organization, Person) and ensure clean canonicalization and stable URLs.
-
Keep it current. Update dates and facts for recency‑sensitive topics. For context on shifting patterns in Google’s ecosystem, see Google Algorithm Update October 2025.
-
Safety and quality. Avoid thin, spammy, or misleading content. Engines apply safety and quality filters that can down‑weight low‑trust sources.
Practical example: Monitor and compare citations across engines
Disclosure: Geneo is our product.
Here’s a neutral, reproducible workflow marketing teams can use to keep tabs on where they’re cited.
- Define priority prompts. List top questions customers ask that mention your brand, products, or category.
- Capture platform responses. For each prompt, record AI Overviews (where present), Perplexity answers, ChatGPT Search results, and Copilot responses.
- Log citations at the passage level. Note which domains are cited, the exact snippets, and how often each engine references them.
- Track changes over time. Repeat weekly for a month to understand volatility and the impact of content updates.
- Compare patterns. Identify which pages get cited, which answers omit you, and whether forums/video sources dominate for certain queries.
- Prioritize fixes. Strengthen pages that nearly earn citations (add explicit definitions, numbers, and schema) and build missing assets for high‑intent prompts.
This cadence turns abstract “AI visibility” into observable evidence you can act on—especially when you pair changes (e.g., reworking a definition or adding a data table) with shifts in which passages get cited the following week.
Common misconceptions to drop
“AI engines don’t use any index.” Not quite. They often maintain vertical indices and caches, and they tap search infrastructure under the hood. The key difference is that the decisive ranking is assembled during retrieval, reranking, and synthesis—answer by answer.
“Keywords don’t matter anymore.” Keywords still help for lexical recall and disambiguation, especially for entities and constraints. The trick is to pair plain‑language phrasing with passage‑level clarity so dense retrievers and rerankers can confirm relevance.
“All engines treat citations the same way.” They don’t. Citation count, placement, and source mix vary. Google’s AI Overviews keeps citations conservative; Perplexity often lists more sources inline; ChatGPT Search and Copilot show links in different formats depending on mode and task.
Why this matters for teams
When ranking emerges at answer time, you’re optimizing less for a static list and more for being the best snippet to ground a claim. That shifts effort toward structure, clarity, authority, and recency. It also rewards organizations that monitor which passages get quoted and then improve those passages deliberately. Think of each paragraph as a candidate “evidence tile.” If it can stand on its own, it’s easier to cite—and easier for a model to trust.
Where the field is heading
Academic and industry trends point to tighter loops between retrieval and reasoning: agentic workflows that decide when to retrieve again, stronger rerankers, and more explicit citation anchoring. A 2025 survey highlights the rise of hybrid retrieval and LLM‑as‑judge techniques to reduce hallucination and improve grounding; see the RAG and LLM‑as‑judge survey (2025). Platform UX is also converging on transparent citations—Google, OpenAI, Perplexity, and Microsoft all describe experiences that surface links to the underlying sources (Generative AI in Search, Google 2024; Introducing ChatGPT Search, OpenAI 2025; Perplexity Deep Research; Microsoft Copilot).
Next steps
If you’re responsible for search and brand performance, start by auditing a dozen prompts, logging the citations you do—and don’t—earn, and fixing the passages that nearly qualify. When you’re ready to operationalize monitoring and reporting across teams, you can explore our platform: Geneo.