
What Vectors Mean for SEO in AI‑Driven Search (2025): Entity‑First Architecture and Internal Linking That Earn Citations
Learn expert strategies for entity-first architecture, semantic vector SEO, and internal linking to earn citations and clicks in AI-driven search engines (2025).
If AI answers are where users read, your job is to become cite‑worthy and clickable inside those answers. Vectors changed how content is retrieved (passages, not just pages) and who gets credited (entities with clear provenance). Google confirms AI Overviews synthesize responses and “surface supporting web links,” with eligibility tied to helpfulness, structure, and machine readability, not tricks. See Google’s guidance in 2025 on AI features and presentation in the Search docs: the overview on appearance and controls in AI features documentation (Google, 2025) and product updates on how AI Overviews expand and link out in AI Overviews expansion update (Google, May 2025). Microsoft’s Copilot describes a retrieval‑then‑generation flow where citations must match grounded sources, as outlined in Generative answers with Bing grounding (Microsoft Docs, 2025). Perplexity explicitly shows numbered citations; see How Perplexity works (Help Center, 2024–2025).
This best‑practice playbook shows how entity‑first modeling, vector‑friendly page modules, and hybrid (BM25 + vector) internal linking raise your odds of being cited—and actually clicked—in AI answers.
Build an entity‑first content architecture
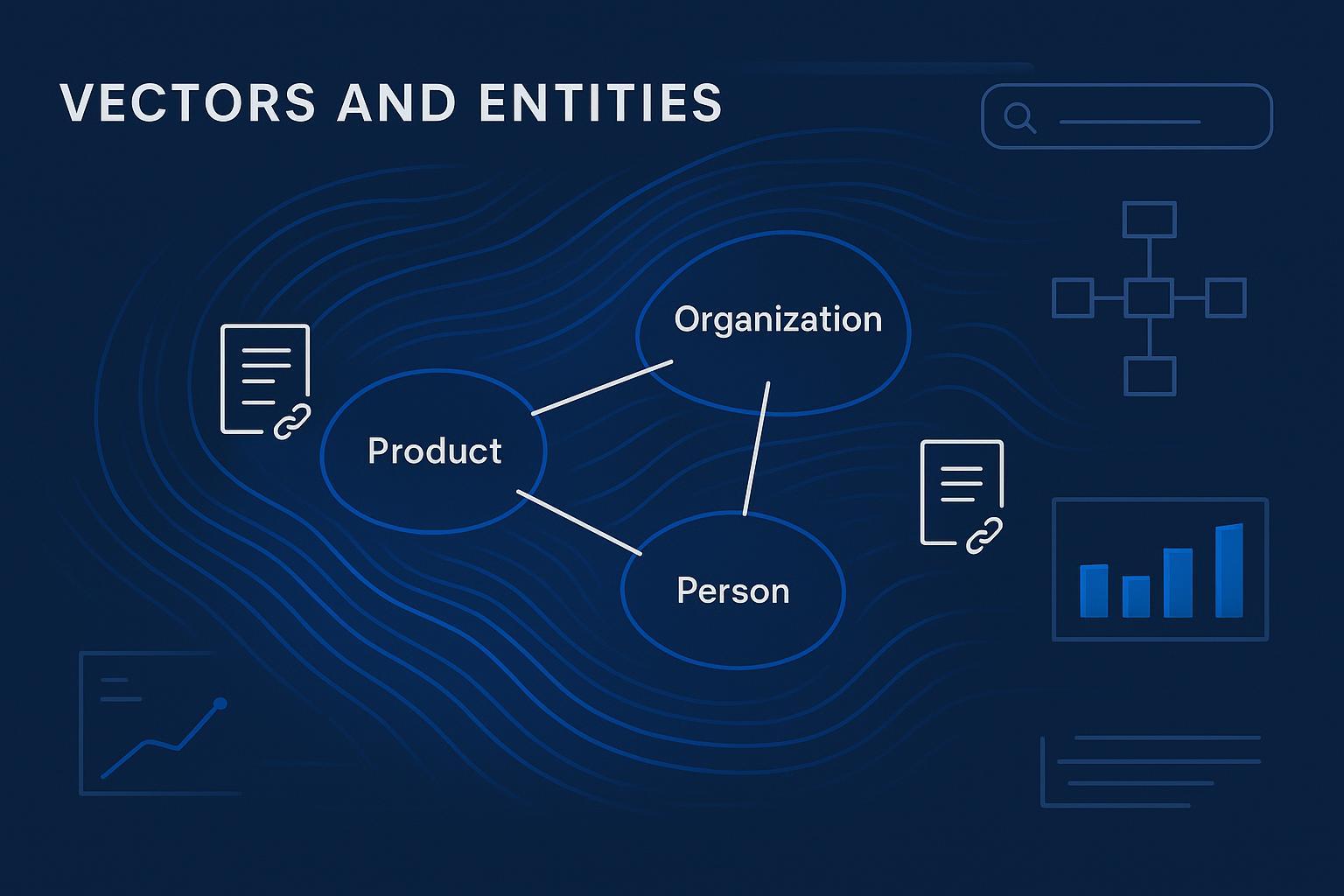
Vectors don’t replace entities; they amplify them. Engines map your text into embeddings and knowledge graphs, then attribute claims to organizations, people, and products. If your pages waffle between identities or share names with other entities, your citations evaporate.
Canonical entity per page. Tie title, H1, schema, and on‑page copy to a single, unambiguous entity. Use Organization/Product/Person and Article schema with consistent sameAs links and internal IDs. Author, date, and method notes improve provenance.
Hubs and spokes. Compose a hub for each primary entity or topic, then spokes for sub‑entities and use cases. Connect with descriptive anchors that mirror intent, not just brand terms. Keep the graph coherent and avoid orphaned nodes.
External corroboration. Where claims matter, cite original research or documentation. Engines prefer sources that cite sources.
Quick checklist to validate entity‑first setup (use it in audits):
One page → one canonical entity; consistent naming, schema, and sameAs.
Hub → spoke links reflect real relationships; no “miscellaneous” dumping grounds.
Clear authorship, dates, and references; SSR for all critical elements.
Make pages passage‑retrieval friendly for vectors
Search now favors passages that answer a question crisply. Think of each H2/H3 as a mini landing zone that can be embedded, retrieved, and cited on its own.
Answer‑first blocks. Place a 40–60‑word, plain‑language answer directly under the heading. It becomes a high‑signal chunk for vector matching and summary lifts.
Question‑led headings. “What is…,” “How to…,” “Should I…,” and task verbs align with conversational prompts used in answer engines.
Stable anchors. Assign explicit fragment IDs and avoid renaming headings casually. Stability preserves citation targets and inbound deep links from AI panels.
Freshness and re‑embedding. Material updates warrant re‑indexing and re‑embedding. If your stack allows scheduled re‑embeds, set cadence by content velocity and query volatility.
Table: Elements that strengthen passage retrieval and how to implement them
Page element | Retrieval signal (vector + lexical) | Implementation tip |
|---|---|---|
40–60‑word answer block under each H2/H3 | High‑density semantic match; concise context improves reranking | Keep jargon minimal; define the entity in one sentence, then state the action or verdict |
Question‑style headings | Aligns with conversational queries; boosts intent clarity | Use user language found in logs; avoid clever but vague phrasing |
Stable fragment anchors (IDs) | Durable citation targets; enables deep links from AI answers | Generate deterministic IDs; avoid auto‑renaming on CMS updates |
Schema (Article/Organization/Person/Product) | Provenance and disambiguation signals | Validate in testing tools; match visible content; add sameAs for entities |
In‑section source links | Verifiable support for claims | Link to canonical sources; prefer original documentation or studies |
A brief micro‑workflow for an existing article: restructure headings into questions, write 50‑word answer blocks, add stable IDs, validate schema, submit for recrawl, then monitor whether those passages start appearing as cited chunks.
Redesign internal links for hybrid retrieval (BM25 + vectors)
Most modern retrieval blends lexical scoring (BM25) and semantic vectors. Elastic and OpenSearch advise combining scores (RRF or weighted), not replacing one with the other. See the primer in Hybrid search explained (Elastic, 2025) and OpenSearch’s techniques in Hybrid search best practices (OpenSearch, 2025).
What does that mean for internal links? Preserve lexical signals in anchors (“canonical entity,” “FAQ schema”) and add semantic depth around links. A link wrapped by two sentences of clean context tends to embed better than a lone anchor inside a list. Cluster by intent so hub → spoke paths mirror learn/compare/implement journeys, and cross‑link sibling spokes where users jump between intents. Where possible, use cosine similarity on paragraph embeddings to suggest cross‑links, then manually veto false positives. Always render critical navigation server‑side to keep it crawlable.
For a practical refresh, extract your H2/H3 passages and embed them, compute similarities to find 5–10 high‑affinity cross‑links you don’t yet have, then replace vague anchors with exact intent/entity phrases that still read naturally. Add short context sentences before and after newly inserted links and confirm SSR.
A quick example: Suppose your “Entity‑first SEO” hub has a subsection on “stable anchors.” Embeddings show strong similarity to a spoke on “FAQ schema for micro‑answers.” Add a sentence such as, “If you structure short Q/A blocks with FAQPage markup, you’ll create additional stable fragments worth citing,” then link “FAQPage markup” with a precise anchor.
Measurement that prioritizes AI citation rate and clicks
You can’t manage what you don’t measure. Set KPIs that reflect how AI answers actually attribute and drive traffic: AI citation count by engine and query family; attribution rate (share of answers that include your URL among displayed citations); position‑weighted share of voice (SOV); and downstream behavior like external clicks from AI panels, time on page, scroll depth, and micro‑conversions. Early public notes suggest external click rates may be modest in some AI modes, so visibility plus engagement quality matters.
In practice, Google Search Console currently rolls AI features into Web search. Isolate impacts via landing‑page comparisons, branded vs non‑branded filters, and time‑series diffs. See configuration notes in AI features and presentation in Search (Google, 2025). Capture answer panels programmatically with headless browsers and store snapshots tagged by intent, engine, and whether your link appeared. Centralize multi‑engine tracking; for example, Geneo provides cross‑engine AI citation and visibility monitoring (brand mentions, reference counts) and competitive benchmarking, which can sit alongside GA4/Looker Studio as the AI‑specific layer.
A sustainable cadence works best. Weekly, poll priority queries across engines, log citations and positions, and annotate content pushes. Monthly, correlate citation presence with engagement deltas on affected landing pages and review entity/anchor drift. Quarterly, refresh anchors, schema, and hub mappings and reassess cluster coverage against new intents. Two analyst questions to ask every month: Are we cited more often on the intents we rewired last sprint? When we are cited, do those sessions behave like high‑intent visits or skim and bounce?
A 90‑day runbook (field‑tested)
Start with a one‑week baseline across three to five clusters where answer panels already exist, recording current citation count, attribution rate, SOV, and engagement. In the same window, audit entity clarity and schema on your top pages and flag ambiguous naming, missing sameAs, or thin provenance.
Through weeks two to four, normalize titles, H1s, and schema so each page maps to a single canonical entity; add answer‑first blocks to all sections that match real intents; assign stable anchors; submit for recrawl; and watch early shifts. Then, in weeks five to seven, refresh the hybrid link graph: embed passages, compute similarities, propose new internal cross‑links, replace vague anchors with precise intent/entity phrases, and add two lines of supportive context around each new link. Ensure SSR and crawlability, patch canonical/render mismatches, and retire “miscellaneous” pages that muddle the graph.
By weeks eight to ten, harden measurement: automate query polling and panel capture, populate a dashboard with per‑engine citation presence and positions, and compare engagement on sessions arriving from answer panels versus classic results, segmented by intent. Iterate on passages that never win citations—tighten the 50‑word answers, add corroborating sources, or split overloaded sections. In weeks eleven and twelve, close competitive gaps by identifying intents competitors dominate, expanding hub coverage with new spokes or deeper comparisons, and strengthening provenance via authorship bios and links to original research and authoritative documentation.
Keep an eye on three risks as you go. Vector drift happens when edits shift embeddings away from the intent you need; re‑embed after changes and regression‑check similarities. Anchor decay occurs when CMS renames break fragment IDs; preserve or 301 old anchors when possible. Schema gaps appear after design refreshes; keep structured data validated and consistent with visible copy.
Further reading and workflows
For a tactical on‑page playbook to earn citations with answer‑first blocks and schema, see the methodology in How to Optimize Content for AI Citations.
To stand up a full monitoring loop and baseline your current presence, use the workflow in How to Perform an AI Visibility Audit for Your Brand.
Disclosure: Geneo is referenced as one example of AI visibility monitoring; teams should evaluate any toolset against their stack, data needs, and governance.