
Best Practices for Measuring Sentiment in AI Answers (2025)
Discover actionable 2025 strategies and best practices for measuring brand sentiment in AI-generated answers across ChatGPT, Perplexity, and Google AI Overview. Includes compliance tips, emotion/intent analytics, and Geneo integration for professional teams.
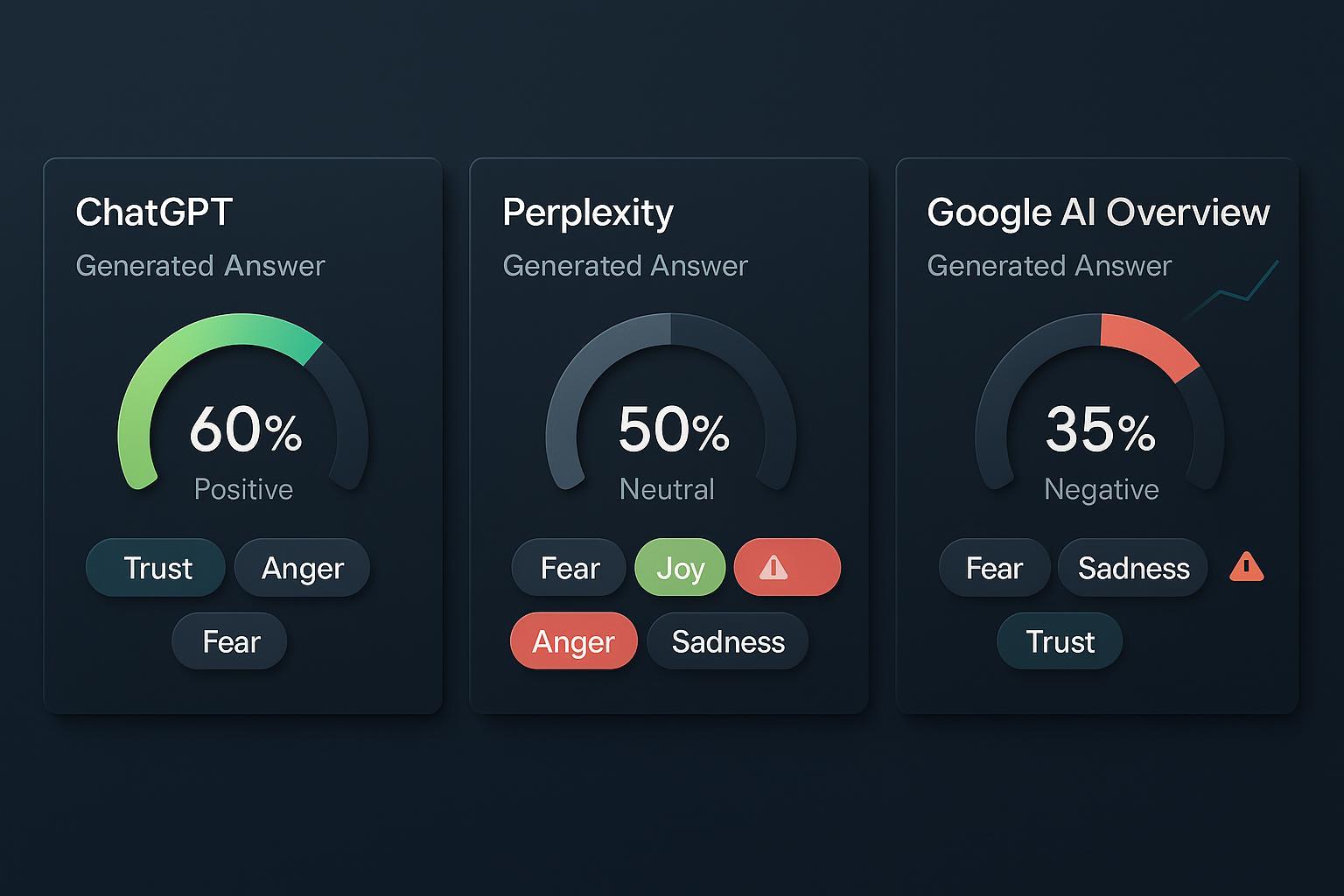
If your brand lives or dies by how it’s described online, you can’t ignore AI‑generated answers. They’re increasingly the first touchpoint for product discovery and reputation cues across ChatGPT, Perplexity, and Google’s AI Overviews. Google itself outlines how AI features are reshaping discovery and intent capture in 2025, making this an urgent measurement domain for marketers, not just an R&D curiosity, as summarized in Think with Google’s own guidance in the 2025 perspective “5 ways AI makes Search work harder for your brand” and broader AI marketing insights (Think with Google 2025 search guidance and Think with Google 2025 AI marketing questions).
This piece distills what’s working for enterprise brand teams: a practical measurement framework, step‑by‑step SOPs, advanced techniques for sarcasm/negation, a tooling map, and governance guardrails. I’ll also show how teams operationalize this with Geneo for cross‑LLM monitoring and sentiment/emotion analytics.
The measurement framework (what to capture and why)
What to measure, minimally:
- Polarity: positive / neutral / negative
- Emotions: trust, joy, anger, fear, sadness, disgust, surprise
- Intent context: informational, comparative, complaint, advocacy
- Entity correctness: did the answer get your brand facts right?
- Source quality: which citations are driving the answer?
- Platform/LLM variance: are ChatGPT, Perplexity, and AI Overviews aligned or diverging?
Why this taxonomy? Emotion and intent tagging make insights actionable for teams (PR, CX, product). Benchmarks show LLMs perform well on general sentiment/emotion but degrade on sarcasm/negation and domain shift; that’s exactly where human‑in‑the‑loop (HITL) and better prompting matter, as recent 2024–2025 studies propose via reasoning‑aided prompts and specialized benchmarks on sarcasm robustness (reasoning for sarcasm detection, 2024 and a 2025 sarcasm robustness challenge).
Step‑by‑step SOP you can deploy this quarter
- Data collection (compliant by design)
- Use official endpoints only. For ChatGPT, standardize queries through the OpenAI API or enterprise services under the current OpenAI Services Agreement (2025) and Usage Policies. Avoid scraping interfaces for Perplexity or Google AI Overviews; there is no public API for AI Overviews, and automated scraping violates Google policies (Google Policies index).
- Build weekly prompt sets per market and product. Examples: “Is Brand X good for sensitive skin?”, “Top alternatives to Brand X under $50.” Version control prompts; attach a date and campaign tag.
- Sampling plan: 30–50 prompts per brand/LLM/region weekly for trend stability; expand to 100+ during launches or crises. Keep a human sampling workflow for platforms without sanctioned APIs.
- Labeling and taxonomy
- Tag polarity + emotions + intent for each answer. Record model‑reported confidence when available; otherwise, derive a heuristic confidence from agreement across passes/models.
- Maintain a 300–500 item gold‑set per language. Recalibrate quarterly; target Cohen’s kappa ≥ 0.7 in human agreement to ensure reliability.
- Processing and quality control
- Dual/tri‑pass workflow: pass 1 extracts entities and disambiguates product/SKU; pass 2 runs sentiment/emotion with a reasoning prompt; pass 3 runs a consistency check. Send disagreements to human review within 24 hours.
- Sarcasm/negation guardrails: trigger special prompts that ask the model to identify contradictions/irony; escalate low‑confidence cases. Recent classification studies in 2025 show reasoning prompts and hybrid approaches mitigate these errors (LLM classification benchmarks, 2025 and a hybrid ensemble framework, 2025).
- Thresholds and alerts (decide before you need them)
- Negative spike: >20% week‑over‑week increase in negative share, or absolute negative share >30% on any platform triggers a P1 incident.
- Cross‑LLM disagreement: if net sentiment differs by >25 percentage points between any two platforms, open an investigation—source recency and citation quality are frequent culprits.
- Emerging issue: three or more negative mentions tied to the same defect/claim in 48 hours triggers PR/legal review.
- Reporting cadence and KPIs
- Weekly: net sentiment by platform/LLM, top emotions, top cited sources, answer snapshots, change drivers.
- Monthly: share of voice in AI answers (e.g., inclusion in “top recommended brands”), entity correctness score, time‑to‑mitigation for incidents, content update cycle time.
- Quarterly: benchmark vs. competitors, cross‑language variance, calibration accuracy (F1), and reviewer agreement.
- Routing and integration
- Pipe alerts to Slack/Teams; open Jira/Asana tickets for product and content teams; summarize to CRM for customer‑facing alignment.
- Feed insights to PR/SEO to build authoritative source coverage—editorial authority correlates with presence in AI answers per industry analysis in 2024 on PR’s growing role in AI search visibility (Search Engine Land on PR for AI visibility, 2024 and guidance on optimizing content for AI‑powered SERPs, 2024).
Advanced techniques that lift accuracy in the messy middle
- Reasoning‑aided prompting: Ask models to explain sentiment classification and explicitly check for negation/irony. The 2024–2025 body of work shows gains in sarcasm detection and classification stability with chain‑of‑thought or contradiction checks (reasoning for sarcasm detection, 2024).
- Ensembles for robustness: Run two different models (e.g., GPT‑4 class and Llama‑3 class) and compare. Disagreements above a threshold route to human review. Recent 2025 research demonstrates hybrid/ensemble stability benefits on noisy text (hybrid ensemble framework, 2025).
- Few‑shot exemplars and context packets: Include 3–5 labeled examples and a short brand fact sheet (positioning, known edge cases, product contraindications) to reduce hallucinations and improve nuance.
- Multilingual calibration: Use per‑locale reviewer pools and region‑specific lexicons; idioms and sarcasm vary widely across markets.
- Confidence scoring and SLAs: Define what “low confidence” means operationally (e.g., ensemble vote <60% or self‑reported confidence <0.6), and set SLAs for human review.
Tooling in 2025: what’s mature, what’s emerging
- Enterprise social listening suites (mature): Brandwatch, Talkwalker, Sprout Social, and others provide robust sentiment pipelines, alerts, and integrations. They’re not purpose‑built for AI Overviews, but they can ingest monitored content for analysis. For overviews of capabilities, see Brandwatch’s AI feature set and Sprout’s 2025 AI tool guidance (Brandwatch AI tools overview and Sprout Social AI marketing tools).
- AI search visibility/answer monitoring (emerging): Industry roundups track tools experimenting with AI answer visibility metrics across ChatGPT, Perplexity, and others; public, primary technical documentation remains limited, so validate vendor claims during trials (AI SEO/search tools roundup, 2025).
- Model/output quality monitoring: Useful if you generate AI content yourself; platforms like H2O.ai emphasize evaluation and risk monitoring (see 2025 overviews in analyst roundups).
Where Geneo fits
- Geneo consolidates cross‑LLM monitoring for brand exposure, link citations, and mentions across ChatGPT, Perplexity, and Google AI Overviews, then layers AI sentiment and emotion analytics, historical trend views, and alerting. For multi‑brand teams, this eliminates manual sampling spreadsheets and siloed tools.
- Practical differentiators for brand teams: real‑time spike alerts, emotion/intent segmentation, historical trails for audit, share‑of‑voice tracking in AI answers, and content strategy suggestions based on which sources each LLM is citing. You can manage multiple brands and regions in one place and route incidents to the right team.
Dashboards that decision‑makers actually use
Must‑have widgets on a weekly dashboard:
- Net sentiment by platform (ChatGPT, Perplexity, AI Overviews), stacked by emotion
- Cross‑LLM disagreement chart with drill‑downs to answer text and cited sources
- Share of voice in AI answers (appearance rate in “top recommended” lists)
- Entity correctness score and top inaccuracies to fix
- Top emerging themes/complaints and their source citations
- Time‑to‑mitigation tracker for P1 incidents
In Geneo, I recommend:
- Create an all‑brands view with filters for product line, market, and query type.
- Set alert thresholds (e.g., a 20% WoW negative jump) and send them to Slack with a direct link to the affected answer snapshots.
- Add a “sources cited by LLMs” panel to prioritize PR/SEO outreach to the publications actually shaping AI answers.
Governance and compliance: non‑negotiables
- Use sanctioned access only. Do not scrape platforms that prohibit it. Work through official APIs and enterprise agreements; OpenAI’s 2025 Services Agreement and Usage Policies define permitted access, logging, and privacy (OpenAI Services Agreement and OpenAI Usage Policies). Google’s policies prohibit scraping AI Overviews; stay within permitted APIs (Google policies index).
- Privacy and retention: Minimize personal data; redact PII in stored answer logs; set retention windows (90–180 days for raw answers is a reasonable starting point), and document your Data Protection Impact Assessment for large‑scale profiling per ISO/IEC 23894 and NIST AI RMF practices (ISO/IEC 23894:2023 risk management and the NIST AI RMF GenAI profile, 2025).
- Bias and fairness: Maintain diverse reviewer pools and audit outcomes by language/region quarterly.
- Vendor contracts: Execute DPAs and set SLAs for incident alerting, breach notification, and model change notices.
Scenario playbooks
- Negative sentiment spike after a product defect rumor
- Detect: Cross‑LLM dashboard shows Perplexity and AI Overviews turning negative; alerts fire as negative share crosses 30%.
- Diagnose: Drill into cited sources; identify a misinterpreted forum post being treated as authoritative.
- Act: PR publishes a corrective statement; product team updates FAQs; SEO refreshes product pages with explicit clarifications; request corrections where applicable.
- Measure: Track time‑to‑mitigation (<72 hours target) and rebound in net sentiment the following week.
- Market entry in a new region
- Detect: Low share of voice and high “neutral with fear” emotion in AI answers.
- Diagnose: Sparse authoritative local citations; inconsistent entity attributes (pricing, availability) across answers.
- Act: Develop local editorial/PR placements; unify product schema and pricing pages; seed region‑specific FAQs.
- Measure: Quarterly lift in share of voice and improved entity correctness score.
- Competitive comparison queries during a launch
- Detect: ChatGPT lists your brand 3rd with mixed sentiment; Perplexity omits you.
- Diagnose: Missing comparative content and third‑party reviews; LLMs cite outdated articles.
- Act: Publish fresh comparisons, expert reviews, and spec sheets; PR secures updated coverage; paid tests AI‑integrated placements.
- Measure: Inclusion in “top recommended brands” and positive emotion mix within four weeks.
Common pitfalls and how to avoid them
- Chasing every fluctuation: Small week‑to‑week changes are noise. Use statistically meaningful sample sizes and defined thresholds before escalating.
- Ignoring sarcasm and negation: They’re the leading causes of misclassification. Add reasoning prompts and human review queues, as supported by 2024–2025 research on sarcasm robustness and contradiction checks.
- Treating platforms as interchangeable: Cross‑LLM differences are a signal. Investigate divergences; they often reveal source gaps or recency issues.
- Violating platform policies: Scraping can get you blocked and erode trust. Stick to official endpoints and sanctioned access.
- One‑and‑done setup: Models drift, markets change. Re‑benchmark quarterly against your gold‑set and recalibrate thresholds.
30/60/90‑day implementation roadmap
-
Days 0–30
- Define taxonomy, prompts, and thresholds; create the gold‑set (≥300 items/language)
- Stand up dashboards; connect Slack/Teams and ticketing
- Pilot weekly sampling across two LLMs and two regions
-
Days 31–60
- Expand prompts to 50+/LLM/region/week; enable ensemble scoring
- Add emotion/intent tagging and confidence‑based human review queues
- Begin monthly reporting (share of voice, entity correctness, time‑to‑mitigation)
-
Days 61–90
- Roll out multilingual review pools; integrate insights with PR/SEO calendars
- Build quarterly calibration (κ and F1) and fairness audits by region/language
- Socialize a crisis playbook; run a live fire‑drill using historical cases
What good looks like (KPIs)
- Net sentiment improving quarter‑over‑quarter with variance narrowing across LLMs
- Share of voice gains in AI answers for priority queries
- Entity correctness score >90% on core facts
- Time‑to‑mitigation <72 hours for P1 incidents
- Calibration: human agreement κ ≥ 0.7 and F1 trending upward on your gold‑set
Where to start today
- Standardize your prompt set and thresholds.
- Build a small but reliable gold‑set and a weekly sampling cadence.
- Stand up a unified dashboard with alerting and human review queues.
- Validate tool capabilities via trials and contractual SLAs—especially for AI answer monitoring vendors.
If you want a purpose‑built way to operationalize this across ChatGPT, Perplexity, and Google AI Overviews—with sentiment, emotion, alerts, and historical trails—try Geneo. It’s designed for multi‑brand, multi‑region teams who need reliable monitoring, collaboration, and data‑driven content recommendations. Explore Geneo at https://geneo.app.
—
References and further reading
- Google’s 2025 perspective on AI‑enabled search demand and brand visibility: 5 ways AI makes Search work harder for your brand and AI marketing questions 2025
- Why PR/editorial authority drives AI answer presence (2024): Search Engine Land analysis on PR for AI visibility and optimizing content for AI‑powered SERPs
- Robust classification under sarcasm/negation and reasoning‑aided prompts (2024–2025): Reasoning for sarcasm detection, sarcasm robustness challenge 2025, LLM classification benchmarks 2025, and a hybrid ensemble framework 2025
- Platform and compliance anchors: OpenAI Services Agreement, OpenAI Usage Policies, Google policies index, ISO/IEC 23894:2023, and the NIST AI RMF GenAI profile (2025)