
What Vectors Mean for SEO: A Definitive Agency Explanation
Discover how vectors and semantic clustering are redefining SEO strategy, enabling agencies to monitor and optimize AI-driven brand visibility across platforms.
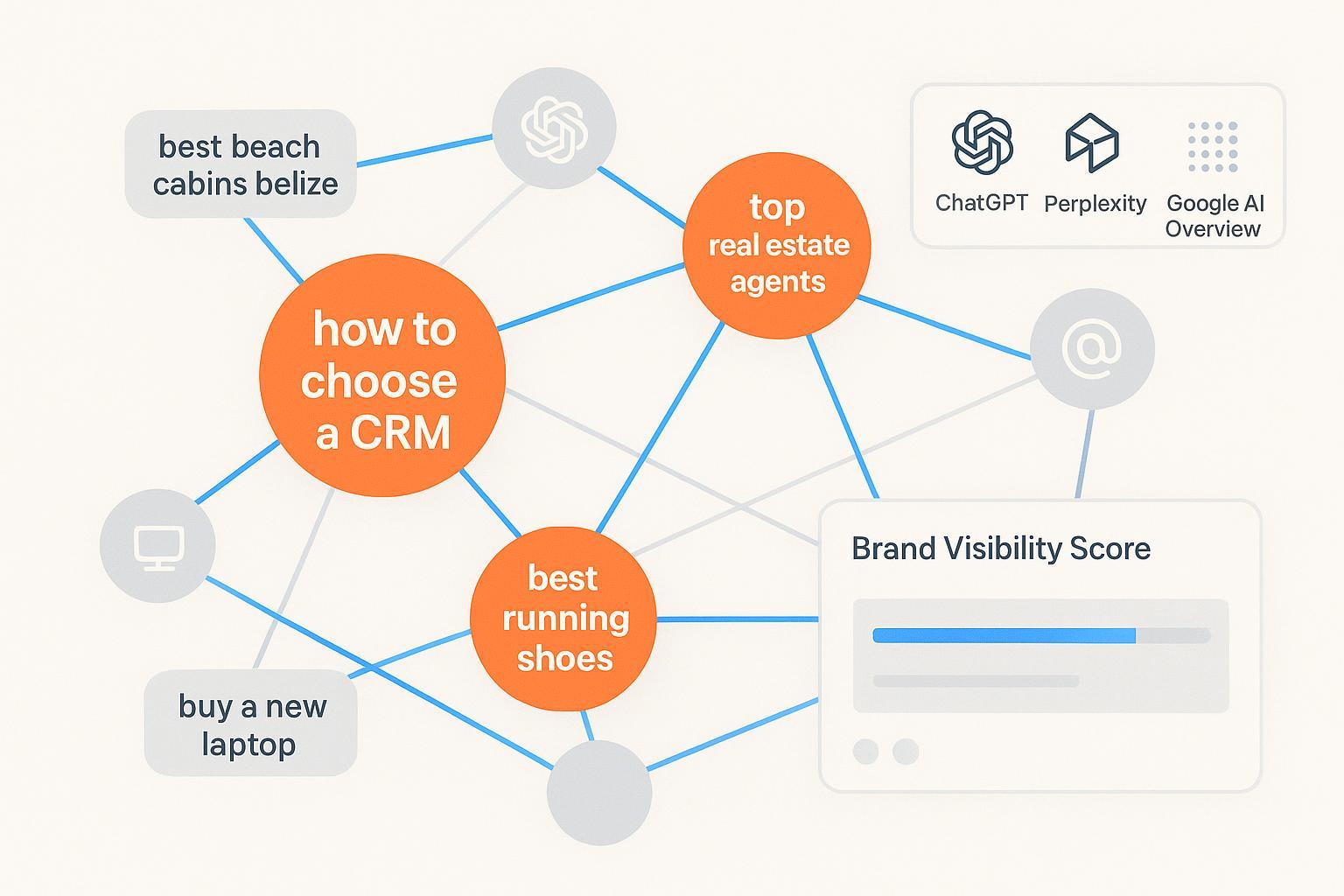
Vectors—also called text embeddings—are the semantic backbone of AI search. If your agency still plans content around single keywords, you’re ignoring the signal modern answer engines actually read: meaning, intent, and topical relationships captured as numbers in a high‑dimensional space. In GEO (Generative Engine Optimization), vectors help systems retrieve, cluster, and rank content so your brand is surfaced in ChatGPT, Perplexity, and Google’s AI Overview.
This explainer keeps the math light and the operations practical. We’ll show how embeddings are made, why they change SEO strategy, and how agencies can integrate them into content planning, retrieval workflows, and cross‑engine measurement.
A plain definition: vectors (embeddings) without the math
A text embedding is a dense array of numbers that represents the concepts in a piece of text—its meaning, not just its words. Think of an embedding like map coordinates for a paragraph: content with similar meaning ends up “near” each other in that semantic map. In practice, embeddings drive semantic retrieval (finding relevant passages beyond exact keyword matches), clustering (grouping related queries and pages to plan topical coverage), and ranking/synthesis (informing which passages are cited or summarized in generative answers). They are one signal among many—links, freshness, citations, and personalization still matter—but if your content isn’t represented well in vector space, it’s less likely to be pulled into answer engines.
How transformer models turn text into vectors (light-technical)
Modern embeddings are produced by transformer models. At a high level, text is tokenized into subword units, fed through layers of multi‑head self‑attention that learn relationships between tokens, and then pooled into a single vector representing the sentence or paragraph.
If you want canonical detail, OpenAI’s Embeddings guide (updated 2024) explains how embeddings capture concepts and why cosine similarity is commonly used. The Sentence‑Transformers documentation on computing embeddings (2023–2025) shows practical pooling choices (mean pooling vs. CLS token) that produce sentence‑level vectors used in retrieval and clustering.
Why vectors change SEO strategy
Keywords aren’t dead; they’ve grown up. Engines map queries to intents and semantic clusters via embeddings, then retrieve passages that best fit those clusters. Your strategy shifts from “rank a page for a term” to “cover the cluster comprehensively and align passages with the underlying intent.”
Below is a quick translation layer from concepts to implications for SEO:
Concept | What it means for SEO |
|---|---|
Embeddings (vectors) | Represent meaning; optimize content to align with user intent and topical themes, not just terms. |
Semantic clusters | Plan content by clusters of related queries; ensure topical completeness across sub‑themes. |
Chunking | Split long content into meaningful passages so the right chunks can be retrieved and cited. |
Similarity search | Retrieval is “nearest meaning,” not exact match; write with clarity around the intent. |
ANN indexes (HNSW/IVF) | Scalable retrieval depends on approximate nearest neighbor search; relevant at implementation or tool selection time. |
From keywords to semantic clusters: a replicable workflow for agencies
Here’s an agency‑ready way to translate keywords into semantic cluster planning and measurement.
Build intent‑led clusters
Group queries by intent and topical sub‑themes; use embeddings to validate which queries naturally map together.
Name clusters by user need (“compare CRMs,” “oceanfront cabins in Belize”) rather than raw terms.
Plan content for topical completeness
Cover the cluster with cornerstone pages, supporting articles, and FAQs. Ensure each sub‑theme is addressed.
Assign schema and entity tags so passages are richly described when chunked.
Structure content for retrieval
Chunk long pages at semantic boundaries (headings, sections), not arbitrary character counts.
Keep passages self‑contained: clear headings, definitions, and examples in each chunk.
Measure AI visibility across engines
Track brand mentions in answers and citations of your pages per prompt and per engine.
Monitor answer inclusion rate for your content and trends over time; tie shifts back to cluster improvements.
Light technical deep dive: chunking, similarity, and search
You don’t need to build every pipeline in‑house, but you do need guardrails to avoid common failure modes.
Chunking guidelines
Target passage length around 200–500 tokens for most embedding models; go longer only when context requires it.
Use modest overlap (about 10–30%) to preserve continuity where sections meet.
Split on headings, paragraphs, or sentences; prefer semantic or recursive splitters over fixed widths.
Validate chunking with Recall@k and answer accuracy; tune empirically per content type. Practical tutorials like OpenAI’s Cookbook example on parsing PDFs for RAG (2024–2025) show how to preserve layout and attach metadata.
Similarity and scaling
Similarity metrics: cosine similarity and dot product are common; with normalized embeddings they produce equivalent rankings.
ANN indexes: algorithms like HNSW and IVF accelerate nearest‑neighbor search at scale. Milvus’s quick reference on ANN explains the recall/latency trade‑offs that matter for production.
Generative search pipelines
Generative engines often fan out a query into sub‑queries, retrieve passages, re‑rank them, and synthesize an answer. iPullRank’s “How AI Mode Works” (2024–2025) describes this flow, including how personal context can tilt retrieval.
Measuring AI visibility across engines
If you can’t measure it, you can’t improve it. Start by defining what “AI visibility” means for your program and make it auditable.
AI visibility: Track whether your brand is named in answers and whether your content is cited as a source across engines and prompts. This definition is expanded in our explainer on AI visibility.
LLMO‑style metrics: Evaluate answer relevance, accuracy/faithfulness (support), and personalization impact. See our guide to LLMO‑style metrics for a reporting framework agencies can use with clients. For retrieval‑grounded evaluation, the TREC RAG 2024 track report (Apr 2025) discusses balancing over‑ and under‑citation with precision/recall and NDCG.
Cross‑engine monitoring: Behavior varies by platform and update cadence. If you are tracking Google’s generative results, see our overview of Google AI Overview tracking tools and consider a routine prompt set per product/service line.
Practical micro‑example (allowed zone): monitoring a cluster across ChatGPT, Perplexity, and Google AI Overview
Disclosure: Geneo is our product.
Imagine an agency focusing on the “temporary email generator” cluster. The goal isn’t to “rank for one term,” but to be included and cited in answers across engines for a set of prompts that represent the cluster.
A neutral, replicable workflow
Define the cluster: prompts like “temporary email generator for signups,” “how secure are disposable inboxes,” and “best temp email tools.”
Prepare content: cornerstone page explaining use cases and limitations; supporting articles on security, deliverability, and integrations; FAQs addressing common concerns.
Structure and embed: chunk pages by sections (use cases, pros/cons, setup), embed with a consistent model, and store with metadata (entities, schema fields, product features).
Monitor: weekly, test the prompt set on ChatGPT, Perplexity, and Google AI Overview. Log where your brand is mentioned, whether any page is cited, and whether your passages are included in synthesized answers. Optionally, see an example output.
Interpret and iterate: if “security” prompts don’t mention or cite your content, add a clearly structured section with authoritative sources and examples, then re‑measure. Over time, aim to lift inclusion rate for the cluster.
No outcomes are promised here; the focus is on building an evidence‑ready repository and a repeatable monitoring routine agencies can present to clients.
Common mistakes to avoid
Treating keywords as the end goal: map terms to intents and semantic clusters, then plan for topical completeness.
Arbitrary chunking: splitting by fixed widths reduces retrieval precision; prefer semantic boundaries and modest overlap.
Determinism myth: embeddings are one signal among many; personalization and platform variability matter.
Not measuring: if you don’t track mentions, citations, and inclusion rate by cluster and engine, you can’t prove progress or secure renewals.
FAQs for leadership and SEO leads
Can we adopt embeddings without writing code?
Yes. Many tools expose embedding and retrieval features; focus your team on content structure (chunking, schema) and measurement. When vendor benchmarks conflict, validate against your own workloads.
What models or databases should we pick?
Choose widely supported embedding models (e.g., Sentence‑Transformers family) and a vector database or search service that supports cosine/dot similarity and filtering. Prioritize reliability, metadata filters, and cost observability over theoretical peak speed.
How long until we see impact?
Expect a few weeks to restructure cornerstone content and start monitoring. Measurable changes in mentions/citations typically follow content improvements and platform updates; set baselines and review trends monthly.
What KPIs can we show clients?
Cluster‑level inclusion rate across engines, brand mentions per prompt set, citations of your pages, and LLMO‑style metrics (relevance, accuracy/faithfulness). Tie movement to specific content changes in your reports.
Closing: build your semantic advantage
Embeddings are the connective tissue of GEO. Agencies that plan by semantic clusters, structure content for retrieval, and measure cross‑engine visibility will win more zero‑click moments and retain clients with transparent reporting.
If you’re ready to see where your brand stands today, Start Free Analysis.