
How Tracking Perplexity Rankings Drives AI Search Visibility (2025)
Discover 2025 best practices for tracking Perplexity AI rankings to boost brand search visibility. Actionable KPIs, benchmarks, and expert workflow for SEO pros.
If your brand lives and dies by answer-first experiences, Perplexity is no longer a nice-to-have—it’s a high-velocity surface where credibility and clicks hinge on whether you’re cited and how prominently you appear. Multiple 2025 reports show Perplexity’s rapid growth and investor confidence, framing it as a serious distribution channel for knowledge workers worldwide according to coverage by TechCrunch (2025). The strategic question isn’t “Should we track Perplexity?” but “How do we track it in a way that drives repeatable gains?”
This best-practice guide breaks down what a “ranking” really means in Perplexity, the evidence behind where citations come from, the KPIs that predict visibility, and a weekly workflow you can run without guesswork.
What a “Ranking” Means in Perplexity
Traditional SEO talks in positions. Perplexity talks in citations. To manage visibility, translate “rank” into two measurable outcomes—whether your source is included for the query and how it is positioned within the answer unit, especially among the first three sources. Those placements are most likely to be read, tapped, and mentally associated with the answer. For operational clarity, many teams log “presence + placement” as their proxy for rank, a construct echoed in practitioner guides such as Rankshift’s Perplexity tracking overview (2025). You’ll also want to classify source types—owned, media, and directory—because Perplexity’s source mix can differ from other engines and will determine the levers you pull to improve.
The Evidence: Where AI Citations Actually Come From
In 2025, the most robust cross-engine benchmark came from Yext’s analysis of 6.8M citations across 1.6M queries spanning ChatGPT, Gemini, and Perplexity. The study found that 86% of AI citations originate from brand-managed sources (owned sites and listings), countering the myth that AI answers rely mostly on forums. See the Yext press release (2025) and the methodology and engine-level nuances in Yext’s blog analysis (2025). Two additional takeaways matter for Perplexity tracking: engine preferences differ by source type—Perplexity often leans more on niche/industry directories for some subjective or local queries—and cross-engine overlap is low, with only about 5% of citations overlapping across ChatGPT, Gemini, and Perplexity in Yext’s later recap, underscoring why engine-specific tracking is required; see Yext’s 15 stats marketers need for 2026 (2025).
Implication: A Perplexity program must measure inclusion and prominence per query cluster and tailor off-site/owned-site plays to the source types Perplexity actually favors for your vertical.
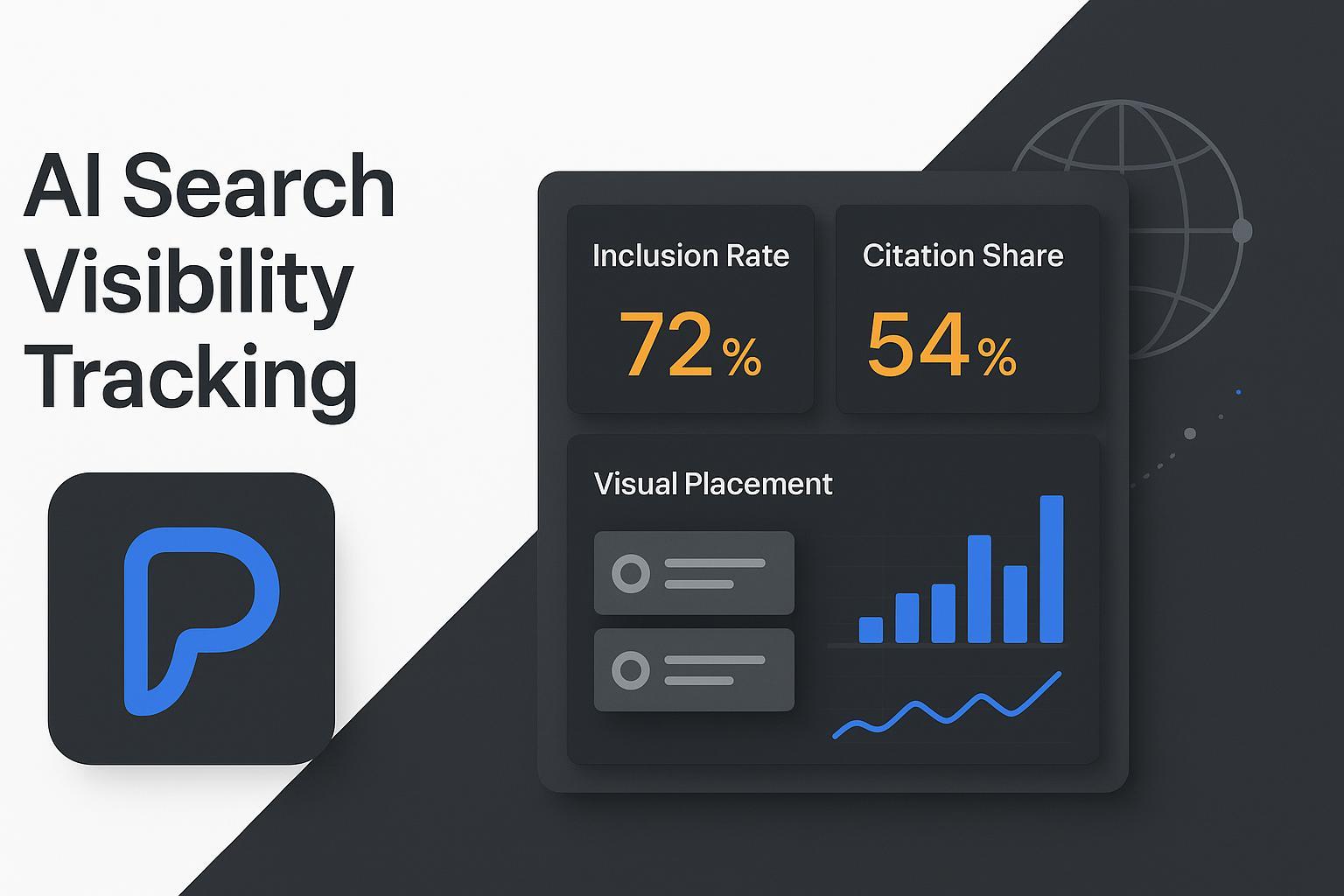
KPIs That Predict Perplexity Visibility
The following KPIs translate Perplexity’s behavior into a measurable operating system. For definitions and extended context on AI visibility, see Geneo’s AI visibility definition and the hands-on guide to optimizing content for AI citations.
KPI | Definition | Why It Matters | Example Action |
|---|---|---|---|
Inclusion Rate | % of tracked prompts that cite your domain | Core visibility indicator | Restructure content on near-miss queries; add direct answers |
Citation Share | % of all citations you capture across a query set | Authority proxy vs. competitors | Refresh winning URLs; build authority pages around gaps |
Visual Placement | Prominence of your citation within answer units | Drives clicks and brand association | Front-load answers; use scannable formatting and data points |
Source Mix | Owned vs. directory vs. media share | Reveals off-site opportunities | Pitch over-weighted directories and trusted media in your niche |
Freshness Velocity | Update cadence and visible recency markers | Fresh content is more likely to be included | Establish quarterly refresh cycles on priority pages |
Entity/E-E-A-T Signals | Author credentials, citations to primary sources, provenance | Strengthens trust and selection | Add expert bios; cite original research with dates |
These KPIs provide the connective tissue from tracking to intervention. If Inclusion Rate is flat but Source Mix skews away from owned properties, your next sprint likely targets third-party coverage and authoritative listings rather than yet another on-site rewrite.
A Reproducible Workflow Agencies Can Run Weekly
The goal isn’t just to “get cited once.” It’s to build a system that compounds. Here’s a Perplexity-specific workflow you can run on a weekly cadence, with 30–60 day evaluation windows.
Define the prompt set. Curate 50–200 high-intent prompts across informational, commercial, and brand queries. Segment by cluster so you can attribute wins cleanly. For scoping ideas and tool options, see Geneo’s roundup of answer-engine workflows and tools in 2025-era guides.
Baseline logging (presence + placement). For each prompt, record whether you’re cited, the position of your citation (track the first three distinctly), the source type, and competitor citations. This mirrors the presence/placement construct from Rankshift’s tracking guide (2025).
Diagnose extractability and trust. Map on-site content to the prompt’s intent; front-load a direct answer; validate JSON-LD (Article, FAQPage, HowTo) and ensure the content is server-rendered and crawlable. Check E-E-A-T markers: author bios with credentials, outbound citations to primary sources, and visible update metadata. For a deeper checklist, see Geneo’s optimize for AI citations workflow.
Expand authority footprint where Perplexity looks. If Perplexity favors directories in your vertical (as Yext observed), pursue high-trust listings and media coverage that echo your core claims. Avoid generic link-building; target sources Perplexity actually cites for your topics.
Iterate and attribute. Re-measure after each 30–60 day sprint. Track Inclusion Rate uplift, changes in Citation Share, shifts in Visual Placement, and competitive SOV. Where analytics allow, correlate with referral lift from cited sources and branded search.
Think of it this way: you’re training the model with clearer signals and better provenance while giving it more credible places to point.
Field Notes: What Usually Doesn’t Move the Needle
LLMs.txt is not a lever for citations. A 300k-domain analysis reported no measurable relationship between llms.txt presence and AI citation frequency across major LLMs, per Search Engine Journal’s report (2025). Maintain robots.txt hygiene and crawl accessibility, but don’t expect llms.txt to change your Perplexity numbers. Thin updates rarely change inclusion—tacking on a paragraph won’t fix extractability or credibility. Rework structure, surface data, and improve author/entity signals. And don’t over-rely on one off-site tactic. If your Source Mix is skewed, address the weak leg (owned content, directories, or media) rather than doubling down on what’s already saturated.
Practical Tools and a Brief Example (Disclosure)
Disclosure: Geneo is our product.
How a team operationalizes this without drowning in tabs: define your prompt set, then centralize weekly presence/placement metrics, source mix, and competitor citations. A practical setup is a shared dashboard or sheet for raw logging plus a tool to monitor AI citation presence and SOV across engines. For background on prompt-level visibility concepts, see Geneo’s Peec AI review (2025), and for definitions/methods see Geneo’s AI visibility explainer.
In a typical sprint, you’d baseline Inclusion Rate and Visual Placement for 100 prompts, fix extractability on five core URLs, secure two niche-directory placements, then remeasure 45 days later. If Inclusion Rate rises but Placement lags, your next sprint focuses on answer structure and data presentation rather than net-new content.
Pitfalls and Quality Checks Before You Ship
Teams commonly misread intent—if a prompt seeks a process, don’t answer with a definition. Align headings and schema to the question users actually ask. Opaque authorship is another trust killer; add expert bios and cite primary research with dates. Finally, ensure important content isn’t client-rendered only or blocked by robots and headers; Perplexity can’t cite what it can’t reliably crawl.
Quick QA pass:
Does the page lead with a direct, sourced answer, with dated, attributed data?
Is JSON-LD validated, and are FAQ/HowTo blocks genuinely helpful (not filler)?
Are update timestamps visible, and does internal linking support the entity/topic cluster?
Reporting Cadence and the Stakeholder Narrative
Weekly tracking feeds a monthly narrative. Your executive summary should show Inclusion Rate change across clusters and the interventions that drove the lift, Citation Share versus key competitors with notes on new third-party sources Perplexity began citing, and Visual Placement trends for your top revenue-critical prompts. Every 60 days, refresh your benchmark and confirm whether Perplexity’s source preferences remain stable for your vertical. If directories are rising in your cluster, reallocate outreach accordingly. If owned-site citations improved after structured rewrites, scale the pattern to adjacent pages. The point isn’t a static “rank report,” but an evidence-backed narrative that earns budget for the next sprint.
Bring It Together
Perplexity visibility is a function of being the source the model wants to cite—and being cited where users will see you. Track inclusion and prominence, measure the source mix that actually feeds Perplexity in your vertical, and iterate in 30–60 day cycles. When you can point to KPI movement and tie it to specific interventions, you’re no longer guessing—you’re operating.
Want to see how teams instrument this without reinventing the stack? Book a short Geneo demo and pressure-test this workflow on your queries.