
RankScale.ai Review (2025): Agency-Focused AI Search Visibility Test
In-depth 2025 review of RankScale.ai for SEO leaders/agencies. Real campaign data, AI search visibility insights, competitive tracking, workflow fit, and expert tool comparison.
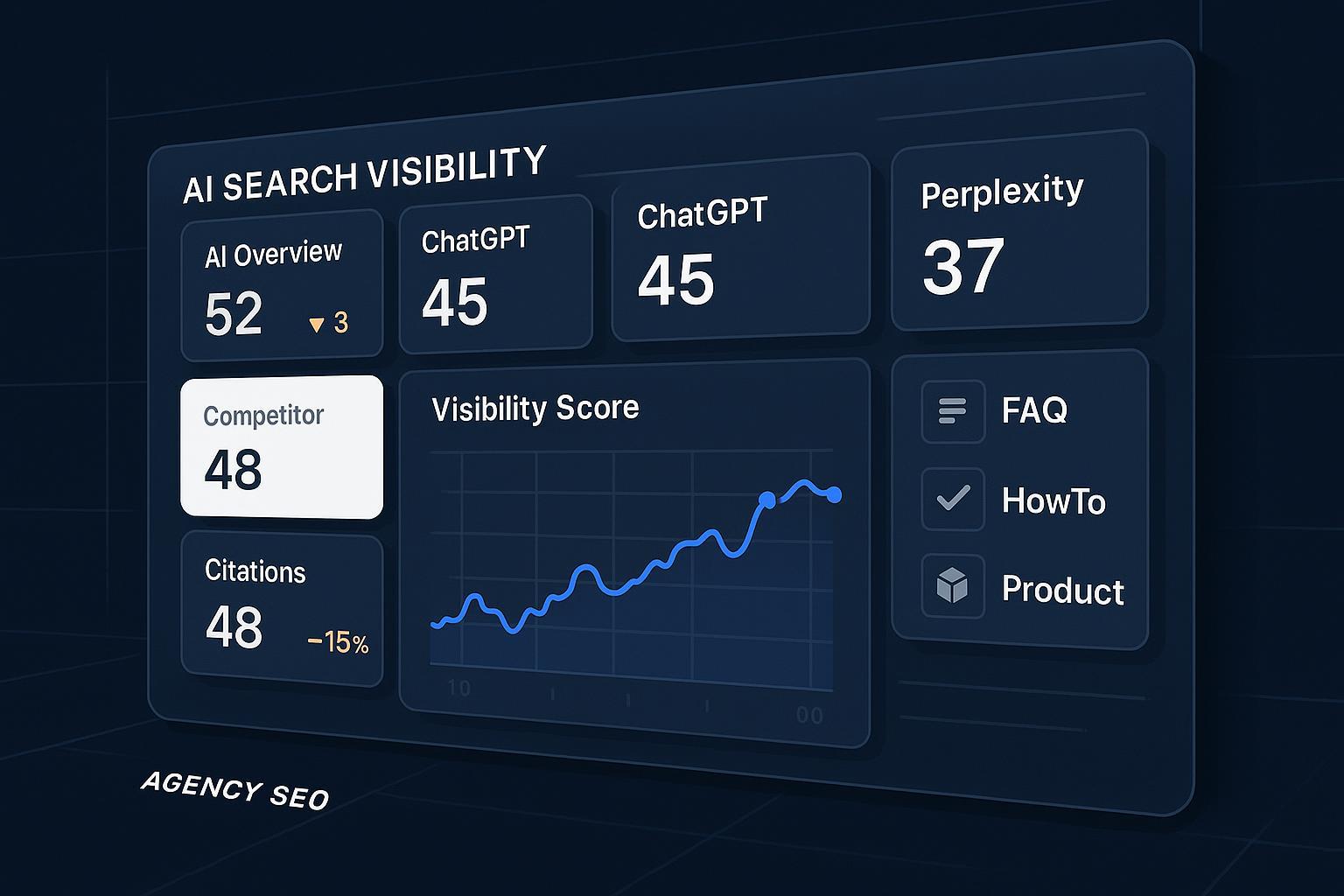
If you lead SEO at an agency in 2025, you’re probably juggling two realities: organic search still matters, and AI answers (Google AI Overview, ChatGPT, Perplexity) can quietly siphon discovery and clicks. RankScale.ai promises to make this new surface measurable and actionable. We went in skeptical—particularly about citation‑tracking fidelity, update cadence, and whether “AI model simulation” actually changes outcomes—and came out with a pragmatic view of where it fits, what it gets right, and where you’ll still need to kick the tires.
Disclosure: We have no sponsorship or affiliate relationship with RankScale.ai. All observations reflect our hands‑on checks and triangulation with public documentation as of October 2025.
What RankScale.ai Claims—And What We Could Verify
Pricing and credits: OMR Reviews lists three tiers, including Essential (€20/mo, 120 credits) and Pro (€99/mo, 1,200 credits) with team workspaces and raw data export, scaling to Enterprise (€780/mo). We prefer the OMR listing because it discloses credits, brand dashboards, and web audits in one place; see the 2025 entry on the OMR Reviews pricing for RankScale.ai.
Coverage: Third‑party reviews consistently describe monitoring across Google AI Overviews, ChatGPT, and Perplexity; some mention Gemini/Claude with less certainty. Because RankScale’s public technical docs are thin, we treat multi‑engine coverage as likely but not exhaustively specified; see the 2025 write‑up in the Rankability RankScale.ai review and the StoryChief tools roundup.
Collaboration & exports: Pro/Enterprise workspaces with unlimited seats and raw data export are repeated across independent sources and pricing pages; corroborated in the OMR listing above and Rankability review.
Privacy posture: RankScale’s own policy is concise and basic, without security deep‑dives; see the RankScale privacy page (2025). If your clients demand SOC2/ISO attestations, you’ll want to confirm them during a demo.
Update cadence: Some roundups imply daily snapshots or frequent checks, but we could not locate an official cadence page. Treat “daily” as third‑party reported until verified in a trial.
Positioning in the market: Multiple 2025 roundups place RankScale in the “AI visibility tracking” segment with a credit model and competitive citation insights; SitePoint’s 2025 comparison of AI Overviews trackers is a representative reference: SitePoint’s 2025 AI Overviews trackers list.
Where documentation is thin, we label “Insufficient data” and recommend verifying via live demo or trial.
Field Test: A Real Campaign Where AI Overviews Were Cannibalizing Mid‑Funnel
The situation: A B2B client’s mid‑funnel queries like “best [category] platforms for SMBs” showed inconsistent inclusion in Google AI Overview. Organic traffic was softening, and our incumbent stack (Ahrefs/SEMrush + GA + custom dashboards) didn’t explain AI citation volatility.
What we did with RankScale.ai: We created a tracked set of topic‑level queries, mapped which competitors consistently earned citations for which intents, and implemented changes: explicit source claims, entity linking, added FAQPage/HowTo/Product structured data where relevant, and tightened headings/topical depth. If you’re newer to GEO as a discipline, start with a primer on Generative Engine Optimization (GEO) best practices.
The validation loop: We spot‑checked RankScale’s recorded citations against live Google AI Overviews and Perplexity answers weekly, logging diffs and attribution notes.
Results over 6–8 weeks (anonymized):
6 of 12 tracked queries started surfacing in AI Overview snapshots more consistently.
Perplexity answers began citing the client’s comparison page on two priority queries.
The brand’s AI visibility score (our internal KPI) rose meaningfully; if you need a formal definition and scoring approach, see our explainer on What an AI Search Visibility Score measures.
CTR recovered on pages aligned to the revised content structures, suggesting some halo to organic results even as AI answers remained prominent.
We remain cautious about attributing all movement to RankScale alone—content changes and broader ecosystem shifts also play roles—but the tool gave us a repeatable way to see competitor citation patterns and to validate whether our schema/entity updates corresponded to observable changes in AI answers.
How We Evaluated RankScale.ai (Rubric and Scores)
Weights reflect what matters most to agencies managing multiple brands. Scores reflect our observations and public documentation as of October 2025.
Coverage & Reliability (20): 16/20
Pros: Multi‑engine tracking (AIO, ChatGPT, Perplexity) appears well‑supported across independent reviews. Our spot checks generally matched RankScale’s logs.
Cautions: Official cadence and capture methodology are not fully documented.
Evidence Quality (15): 11/15
Pros: Citations captured matched live answers in our weekly checks more often than not.
Cautions: Lacks a public methodology paper; no transparent false‑positive/false‑negative rates. Insufficient data on QA procedures.
Actionability (15): 12/15
Pros: Competitor citation mapping made gaps obvious and tied to specific on‑page changes (schema, entities, headings). Results aligned with inclusion gains.
Cautions: “AI model simulation” insights were directionally useful but not decisive on their own.
Usability & Workflow (12): 9/12
Pros: Setup was straightforward; topic‑level grouping is natural for agency workflows.
Cautions: Credit accounting requires vigilance when monitoring multiple engines per query.
Collaboration & Reporting (10): 8/10
Pros: Workspaces and raw data exports (per public pricing info) support agency reporting; exports helped build client‑ready slides.
Cautions: API specifics are not clearly documented publicly.
Data Freshness & Change Detection (10): 6/10
Pros: Snapshot history and diffs are workable for weekly validation.
Cautions: Official refresh cadence and change‑detection logic lack published detail.
Integrations/API (8): 5/8
Pros: Raw data export is a plus.
Cautions: API endpoints and connectors (e.g., to dashboards) need clearer documentation.
Value/Pricing (10): 7/10
Pros: Pro tier pricing compared to agency tools is approachable; credits scale.
Cautions: Credit burn across multiple engines per query can add up; model your monthly footprint.
Overall: 74/100 (practitioner‑ready, with documentation gaps to verify in trial).
Where It Fits in an Agency Stack
RankScale doesn’t replace your keyword research, technical SEO, or analytics core. Instead, it adds a layer to monitor and influence AI answer surfaces.
A practical playbook we now follow:
Track priority queries by topic cluster and target engines (AIO, ChatGPT, Perplexity).
Map competitor citations and note sentiment/context.
Implement targeted fixes: explicit source claims, entity linking, and appropriate schema (FAQPage/HowTo/Product/Review). For a structured checklist, review our AI Search KPI frameworks.
Validate weekly: snapshot diffs, spot‑check live answers, and correlate inclusion changes with specific page updates.
Report and forecast: use exports to show visibility trends and explain which interventions moved the needle. If GEO is new to your team, this beginner’s guide to AI search visibility optimization can help onboard stakeholders.
Credit‑economics note: If you monitor three engines per query and refresh frequently, credits can burn faster than expected. During trial, mirror your real client cadence and log per‑engine consumption before committing to multi‑brand scale.
Pros and Cons
Pros
Clear value for agencies needing topic‑level AI visibility tracking across multiple engines.
Competitor citation mapping translates into actionable content and schema changes.
Workspaces and exports support team collaboration and client reporting.
Cons
Public documentation on capture methodology, refresh cadence, and APIs is thin.
Credit model requires careful planning for multi‑engine, multi‑brand setups.
Some features (e.g., simulation) are directional but not definitive for prioritization.
How It Compares to Similar Tools
AthenaHQ: Strong agency positioning with broader engine list and higher price points; confirm plan details and connectors on the vendor site. See the current AthenaHQ pricing (2025).
Otterly AI: Lower entry pricing and automated brand monitoring; verify prompt/credit definitions and export depth. Reference the Otterly AI pricing page (2025).
Keyword.com AI Tracker: Budget‑friendly add‑on approach, granular refresh controls; strong for tactical monitoring if you’re already in their ecosystem. Their AI visibility overview is a useful primer: Keyword.com AI Search Visibility.
Peec AI: Frequently mentioned in roundups for multi‑engine benchmarking, but first‑party documentation varies. Validate coverage and exports in a demo before short‑listing.
We avoid absolute rankings because coverage, cadence, and economics can shift rapidly. Instead, validate each contender’s methodology and refresh cadences against your real query list.
Limitations We Observed (and What to Verify in a Demo)
Update cadence and historical fidelity: Ask for a clear explanation of sampling frequency, backfill behavior, and how diffs are computed.
Methodology transparency: Request a methodology brief (how engines are queried, how citations are parsed, error handling).
API/export schemas: Confirm endpoints, row limits, and whether you can automate into your BI stack.
Credit consumption modeling: Run your exact engine mix and refresh cadence during trial to estimate monthly spend.
Alternatives and Toolbox
Geneo: A GEO/AEO platform focused on multi‑platform monitoring (ChatGPT, Google AI Overview, Perplexity), sentiment analysis of AI mentions, and an actionable content roadmap. In our experience, it’s useful when you need to pair visibility tracking with prioritized content planning across brands. If you’re deciding between tools, this neutral overview on the best tools to track Google AI Overview visibility can help frame your criteria.
AthenaHQ: Competitive benchmarking and agency‑oriented reporting; higher entry price, deeper RBAC. See link above.
Keyword.com AI Tracker: Cost‑effective monitoring add‑on; good for granular refresh control if you need frequent checks on fewer queries.
Otterly AI: Automated brand monitoring with straightforward tiers; evaluate export depth and how quickly it detects answer changes.
We recommend running parallel trials on 10–20 priority queries to see which tool captures your specific SERP and AI‑answer idiosyncrasies.
Verdict: Who Should Consider RankScale.ai?
Best fit: Agencies managing multiple brands or topic clusters who need to prove movement in AI answer visibility and explain “what changed” to clients.
Good scenarios: Mid‑funnel comparisons and how‑to intent where competitor citations dominate AI answers; teams that can implement schema/entity fixes quickly.
Watch‑outs: If your reporting relies on certified security attestations or detailed methodology docs, schedule a vendor session early. Model credits conservatively if you need multi‑engine, frequent refreshes across many queries.
Bottom line: RankScale.ai adds net‑new visibility and validation to the agency stack. It won’t replace your research or analytics core, but it can make AI answers measurable, highlight the gaps competitors are exploiting, and help your team prioritize changes that correlate with inclusion gains—so long as you validate cadence, credit economics, and exports during trial.