
Steps to Integrate Brandlight’s AI Signals into Predictive Scoring Workflows for New Content Topics
Step-by-step guide to mapping Brandlight AI signals to predictive scoring workflows. Includes schema design, field mapping, weights, and troubleshooting.
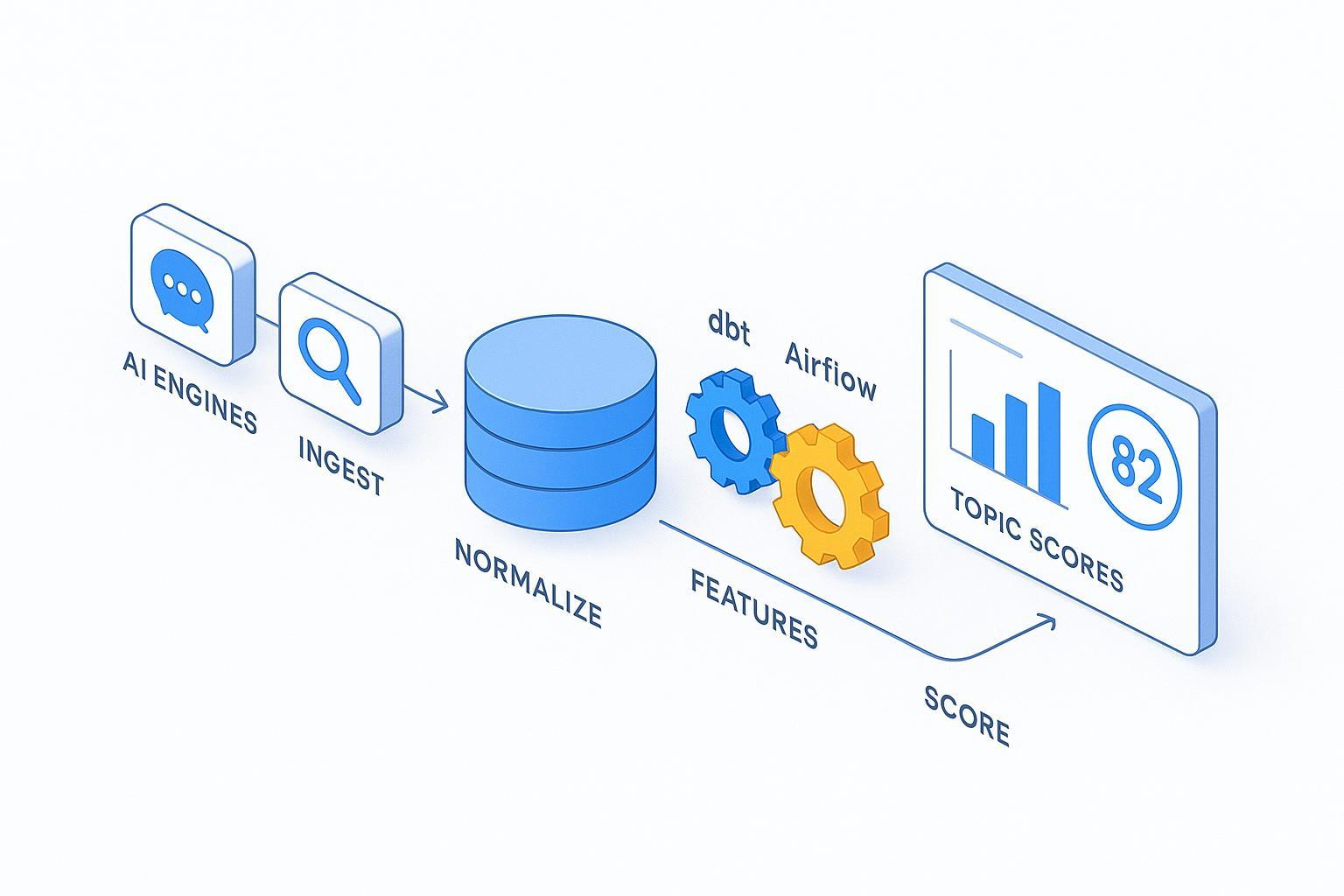
If your editorial roadmap depends on guesswork, you’re flying blind. This guide shows how to turn Brandlight-derived AI signals into a reproducible, warehouse-native predictive score that ranks new content topics by their likelihood to earn AI citations and favorable coverage. You’ll build an end-to-end workflow—ingestion to BI—grounded in explicit schemas, formulas, and governance so ops can ship confidently.
What you’ll get: practical definitions for five core signals (AI citation frequency, cross-engine consistency, sentiment polarity, structured content ratio, indexation latency), a proposed data model you can map to Brandlight exports, step-by-step orchestration with dbt/Airflow, scoring logic with example weights, and a lightweight QA and troubleshooting playbook.
Architecture at a glance
The table below maps each stage to tool choices and outputs. Treat it as a blueprint; adapt names to your warehouse conventions. Fields and table designs are proposed and should be mapped to Brandlight’s actual export schema when available.
Stage | Primary tools | Inputs | Core transforms | Outputs |
|---|---|---|---|---|
Ingest | Airflow (or Snowpipe/BigQuery Data Transfer) | Brandlight export files/API by engine; site page catalog | Load per-engine answer data; normalize engine codes; basic QC flags | stg_ai_answers_{engine}, stg_site_pages |
Normalize | dbt | Staging tables | Field mapping, type casting, de-duplication, sentiment calibration | fact_answers_normalized + dimensions |
Feature engineering | dbt | Normalized facts, site pages | Windowing (7/30d), z-scores, CV, cosine/Jaccard, structured ratio, latency stats | feat_topic_engine_window, feat_topic_window |
Scoring | dbt/SQL | Feature tables | Weighted aggregation, confidence, caps, cold-start priors | topic_score |
BI & ops | Looker/Power BI | Scoring outputs + lineage | Dashboards, alerts, audit samples | Topic scoreboards, SLA monitors |
Reference context on signals and multi-engine divergence is available in Brandlight’s public writing; for example, they outline multi-engine signal families and divergence patterns in the article “Brandlight AI tackles divergence across engines” and related pages: see the overview in the Brandlight signal framework explainer and their note on divergence in Brandlight’s take on cross-engine divergence. Speed-to-visibility (how fast engines reflect site changes) is discussed in Brandlight’s speed-to-visibility note.
Signal definitions and measurement windows
Below are implementation-ready definitions with measurement windows and normalization guidance. The formulas are operator-friendly and designed for cross-engine comparability. For normalization basics, see Google’s ML Crash Course on normalization, and for smoothing momentum, see Rob J. Hyndman’s exponential smoothing overview.
AI citation frequency (per engine e, topic t, window W days):
citation_frequency_e,t,W = citations_e,t,W / total_answers_e,t,W
Windows: 7-day for near-term signal, 30-day for stability. Winsorize tails (1–5%) before z-scoring by engine.
Cross-engine consistency (topic t, window W):
cosine_mean: average pairwise cosine similarity across engines on answer embeddings
jaccard_mean: average pairwise Jaccard similarity on per-answer citation sets
cv_citation_freq: coefficient of variation across engines of citation_frequency
cross_engine_consistency = w1cosine_mean + w2jaccard_mean + w3*(1 - cv_norm) with w1+w2+w3=1
Sentiment polarity (per engine/topic/window):
Average calibrated sentiment score in [-1,1] per answer about the brand/topic. Use a hybrid classifier (lexicon + transformer) with calibration against human-labeled samples; report mean and variance.
Structured content ratio (topic t, window W):
structured_ratio_t,W = structured_pages_t,W / total_pages_t,W
structured_pages: pages with validated JSON-LD of FAQPage/HowTo/Product etc., or strong HTML structure (tables/definition lists) mapped to topic.
Indexation latency (topic t, window W):
Synthetic monitoring: latency_e per engine = first_seen_in_answer_ts_e - page_updated_at
Aggregate by median (p50) and p95 per topic; create an availability score for scoring via 1 - latency_norm.
Data model and field mappings (proposed designs)
Because Brandlight’s export field names aren’t public, use these vendor-agnostic schemas as a starting point and map actual fields when you receive customer documentation.
Staging (per engine): stg_ai_answers_{engine}
answer_id (string, PK within engine)
engine_code (chatgpt, perplexity, gemini, claude, google_ai_overview)
topic_key (string)
query_text (string), answer_text (string)
citations (array URLs), sentiment_score (float)
answer_ts (timestamp), observed_at (timestamp)
geo (string, optional), lang (string, optional), qc_flags (array)
Staging (site pages): stg_site_pages
page_url (PK), topic_key, schema_types (array), has_table_html (bool)
updated_at, first_seen (timestamps)
Normalized facts/dimensions
dim_engine(engine_code, engine_name, weight_default)
dim_topic(topic_key, topic_name, entity_type)
fact_answers_normalized(answer_sk, engine_code, topic_key, answer_ts, observed_at, sentiment_score_raw, sentiment_score_calibrated, citations_count, citations_set_hash, answer_len, qc_flags)
Feature store
feat_topic_engine_window(engine_code, topic_key, window_days, citation_frequency, sentiment_mean, embedding_vector_ref, citations_set_ref, answers_count, updated_at)
feat_topic_window(topic_key, window_days, cross_engine_cosine_mean, cross_engine_jaccard_mean, cross_engine_cv_citation_freq, cross_engine_consistency, structured_ratio, indexation_latency_p50, indexation_latency_p95, updated_at)
Scoring output
topic_score(topic_key, window_days, score, contributing_signals JSON, weights JSON, confidence, run_id, scored_at)
Example dbt model: normalize answers (BigQuery syntax)
-- models/fact_answers_normalized.sql
{{ config(materialized='incremental', unique_key='answer_sk') }}
WITH base AS (
SELECT
TO_HEX(SHA256(CONCAT(engine_code, ':', answer_id))) AS answer_sk,
engine_code,
topic_key,
answer_ts,
observed_at,
SAFE_CAST(sentiment_score AS FLOAT64) AS sentiment_score_raw,
ARRAY_LENGTH(citations) AS citations_count,
TO_HEX(SHA256(TO_JSON_STRING(citations))) AS citations_set_hash,
LENGTH(answer_text) AS answer_len,
qc_flags
FROM {{ ref('stg_ai_answers_all_engines') }}
{% if is_incremental() %}
WHERE observed_at > (SELECT IFNULL(MAX(observed_at), TIMESTAMP('1970-01-01')) FROM {{ this }})
{% endif %}
)
SELECT
b.*,
-- placeholder for calibration (e.g., isotonic or temperature scaling)
sentiment_score_raw AS sentiment_score_calibrated
FROM base b;
Example feature aggregation (7- and 30-day windows)
-- models/feat_topic_engine_window.sql
{{ config(materialized='incremental', unique_key='engine_code_topic_window_days') }}
WITH w AS (
SELECT 7 AS window_days UNION ALL SELECT 30
),
answers AS (
SELECT * FROM {{ ref('fact_answers_normalized') }}
)
SELECT
a.engine_code,
a.topic_key,
w.window_days,
SUM(a.citations_count) / NULLIF(COUNT(*), 0) AS citation_frequency,
AVG(a.sentiment_score_calibrated) AS sentiment_mean,
COUNT(*) AS answers_count,
CURRENT_TIMESTAMP() AS updated_at
FROM answers a
CROSS JOIN w
WHERE a.answer_ts >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL w.window_days DAY)
GROUP BY 1,2,3;
Step-by-step integration (end to end)
Ingest Brandlight exports by engine and set up staging
Configure your ingestion to land per-engine answer data (files or API) into stg_ai_answers_{engine}. Keep engine_code canonical and attach observed_at. Record qc_flags for missing fields or parse errors. For site readiness metrics, maintain stg_site_pages with topic mappings and schema detections.
Validation checkpoint: row counts by engine and day, not_null on answer_id/engine_code/topic_key, and dedupe ratio (<1% duplicates target).
Normalize and calibrate
Use dbt to cast types, de-duplicate, and standardize fields into fact_answers_normalized and dimensions. Implement sentiment calibration once you’ve labeled a small gold set; start with identity mapping and improve iteratively. Build a crisp lineage view so analysts can trace fields back to sources.
Validation checkpoint: dbt tests (unique, not_null, relationships). Spot-check 20 random answers per engine for correct topic mapping and citation parsing.
Engineer features in 7- and 30-day windows
Compute per-engine features (citation_frequency, sentiment_mean). Build cross-engine aggregates (cosine_mean, jaccard_mean, cv_citation_freq) and structured_ratio, plus indexation latency p50/p95. Normalize skewed metrics with winsorization and per-engine z-scores for fair comparisons, following Google’s normalization guidance. For momentum, optionally apply exponential smoothing per Hyndman’s overview of exponential smoothing.
Validation checkpoint: sanity thresholds (e.g., 0 ≤ structured_ratio ≤ 1), distribution checks on z-scores, and recomputation samples against raw data.
Compute topic scores with transparent weights and confidence
Start with reasoned weights that reflect operational impact for new topics: citation frequency (0.30), cross-engine consistency (0.25), sentiment (0.20), structured content ratio (0.15), and indexation availability (0.10 via 1 - latency_norm). Keep weights in a small reference table so business stakeholders can tune them.
Validation checkpoint: score bounds (0–100), monotonicity checks (e.g., higher citation frequency should not reduce score), and review of top-10 topics by editors for face validity.
Expose in BI and wire alerts
In Looker/Power BI, build a topic scoreboard with filters for window (7/30d), engine subset, and confidence. Add drill-through to sample answers and citations. Wire alerts on score changes beyond control limits and on data freshness breaches.
Validation checkpoint: BI-to-warehouse reconciliation (spot-check 10 topics), dashboard load time SLA, and owner on-call rotation for ingestion failures.
Weighting strategy and score computation
Store weights and compute the score as a 0–100 index to keep it interpretable. Include a confidence measure that down-weights sparse or volatile topics.
-- models/topic_score.sql
WITH weights AS (
SELECT 'citation_frequency' AS k, 0.30 AS w UNION ALL
SELECT 'consistency', 0.25 UNION ALL
SELECT 'sentiment', 0.20 UNION ALL
SELECT 'structured_ratio', 0.15 UNION ALL
SELECT 'availability', 0.10
),
feat AS (
SELECT
f.topic_key,
f.window_days,
-- Assume these are already normalized to 0..1
f.citation_frequency_norm,
f.cross_engine_consistency_norm AS consistency_norm,
(f.sentiment_mean_norm) AS sentiment_norm,
f.structured_ratio AS structured_ratio_norm,
(1 - f.indexation_latency_norm) AS availability_norm,
f.answers_count,
f.cross_engine_cv_citation_freq
FROM {{ ref('feat_topic_window_normalized') }} f
)
SELECT
topic_key,
window_days,
100 * (
0.30 * citation_frequency_norm +
0.25 * consistency_norm +
0.20 * sentiment_norm +
0.15 * structured_ratio_norm +
0.10 * availability_norm
) AS score,
TO_JSON_STRING(STRUCT(
citation_frequency_norm AS citation_frequency,
consistency_norm AS consistency,
sentiment_norm AS sentiment,
structured_ratio_norm AS structured_ratio,
availability_norm AS indexation_availability
)) AS contributing_signals,
TO_JSON_STRING((SELECT AS STRUCT ARRAY_AGG(STRUCT(k, w)))) AS weights,
-- Simple confidence example: sample-size and dispersion aware, capped to [0,1]
LEAST(1.0, GREATEST(0.0, LOG10(1 + answers_count) * (1 - COALESCE(cross_engine_cv_citation_freq, 0)))) AS confidence,
GENERATE_UUID() AS run_id,
CURRENT_TIMESTAMP() AS scored_at
FROM feat;
Cold start guidelines
When answers_count is very low (e.g., < 50 in 30 days), widen error bars and emphasize supply-side readiness: structured_ratio and availability. Consider a “new-topic prior” by vertical so editors aren’t penalized for nascent areas.
Refit weights quarterly using backtests that correlate scores with downstream success (e.g., AI citation lifts after publishing). Keep the process documented and reversible.
QA and governance checklist
Data tests: dbt unique/not_null/relationships; freshness on ingestion sources; accepted_values for engine_code; custom tests for window completeness.
Provenance and lineage: auto-generate docs; keep change logs with every weight tweak; store run_id and scored_at for each batch.
Alerting and rollback: on ingestion failure, QC thresholds exceeded (e.g., sudden z-score drift), or BI freshness breaches; default to last good score until fixed.
Sampling: weekly human review of 30 random answers across engines for sentiment and citation parsing accuracy; record disagreements.
Error budgets: define acceptable missing-data percentages by engine; if exceeded, freeze score updates for that engine until recovered.
Troubleshooting and edge cases
Multi-engine divergence: If cosine/Jaccard drop while one engine spikes, prioritize remediation where lift is feasible. Brandlight documents divergence patterns; their primer on divergence in cross-engine behavior provides context for interpreting gaps.
Delayed indexation: If indexation availability is low, verify server-rendered content, add/validate JSON-LD, and increase polling cadence. Brandlight discusses speed-to-visibility and measuring how quickly engines reflect site changes in their note on speed-to-visibility.
Sparse data (new topics): Fall back to 7-day momentum with higher smoothing alpha, use structured_ratio to guide readiness work, and set editorial SLAs to gather evidence (FAQs, how-tos, authoritative references).
Sentiment volatility: Track variance. If swings are jarring, review answer snippets and disambiguate entities in content; calibrate the classifier quarterly with fresh labels.
Reporting and next steps
Operational cadence
Daily ingestion for volatile engines; weekly for slower-changing ones. Recompute features daily; publish scores after data quality checks. Review top movers in an editorial stand-up and assign experiments.
Where to go deeper
For foundational context on multi-engine visibility, see our overview of AI visibility in what “AI visibility” means in practice. For improving citations, review practical ways to optimize content for AI citations. And for robust sentiment scoring practices, see best practices for measuring sentiment in AI-generated answers.
Disclosure: Geneo is our product. You can use it alongside Brandlight to monitor cross-engine AI visibility, maintain evidence logs, and educate stakeholders while your predictive scoring workflow matures.
Notes on Brandlight sources
Brandlight outlines signal families and export-to-pipeline usage patterns in several public posts. See the Brandlight signal framework explainer for a high-level map, and consider their divergence and speed-to-visibility posts cited above for operational interpretation.
That’s the workflow. It’s structured so you can ship a minimal version in weeks and harden it over time without rewriting the foundation. When your editors ask, “Which topics should we greenlight next?”, you’ll have an answer backed by data and a clear audit trail.