
RAG × GEO: How Retrieval‑Augmented Generation Systems Interact with Generative Engine Optimization Signals
Learn how GEO signals shape each stage of RAG systems for better AI citation, retrieval, and brand visibility. Actionable insights for technical SEO and ML teams.
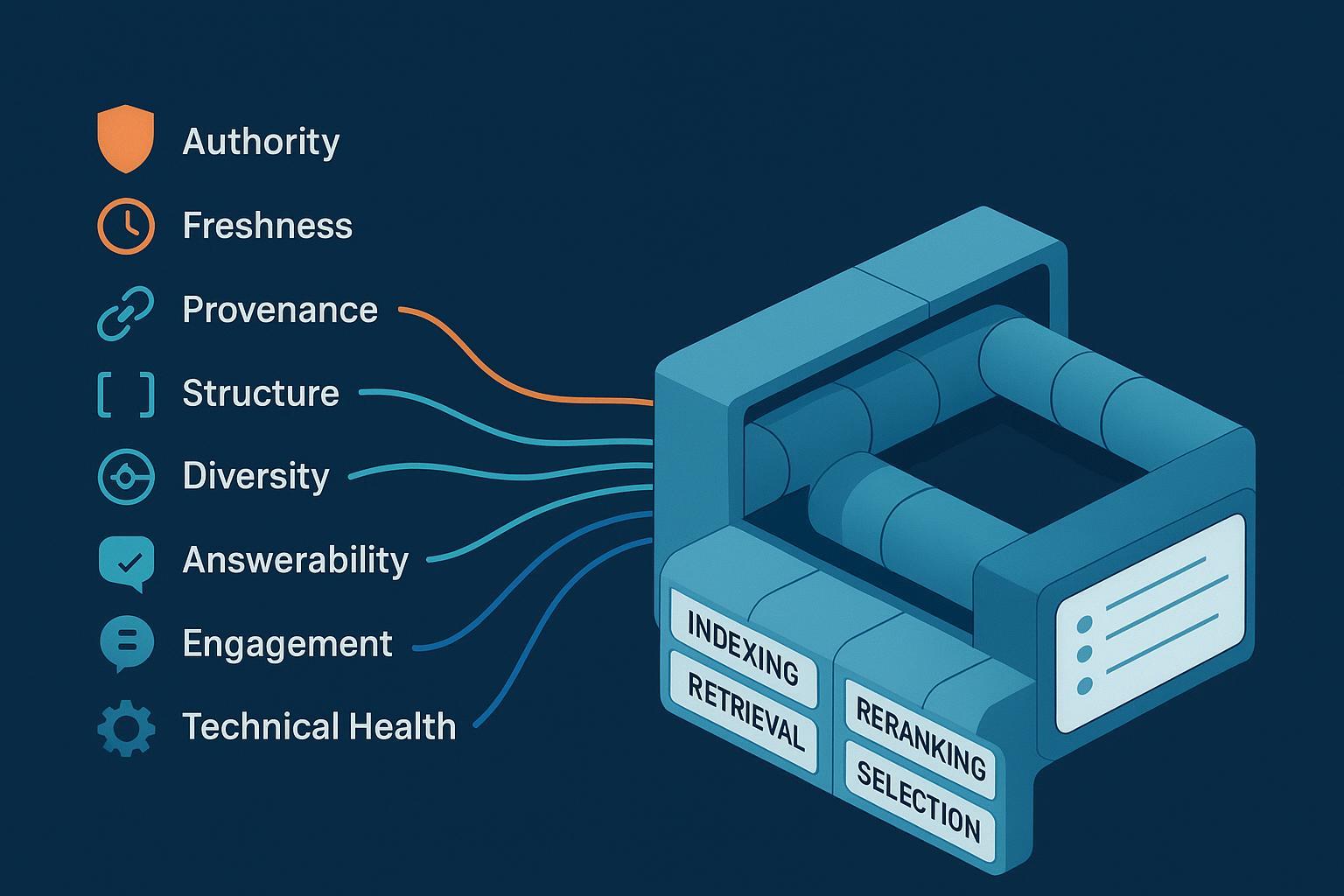
Generative engines don’t “rank pages” the way classic search does—they select passages to ground answers. If you want your content to be retrieved, cited, and trusted by systems like Perplexity, ChatGPT, Google AI Overviews, and Bing/Copilot, you’re optimizing for GEO signals, not just traditional SEO. Think of GEO as feed design for LLMs: the way you package facts, provenance, and structure determines whether a RAG pipeline can find and use your work.
GEO (Generative Engine Optimization) refers to structuring and publishing content so LLM‑based answer systems can retrieve, extract, synthesize, and—where supported—cite it. Industry definitions converge on this idea and list consistent signal categories—authority, recency, provenance, structure, diversity, answerability, engagement, and technical health—while noting proprietary weighting is opaque, as explained by Search Engine Land’s GEO overview (2024) and the a16z perspective in “GEO over SEO”. For a broader framing of AI exposure, see What Is AI Visibility?.
What Counts as GEO Signals Today (and Why They’re Different from Classic SEO)
Classic SEO optimizes link rankings. GEO optimizes passage selection and attribution in answer systems. The most observed signals today include:
- Authority and expertise: Clear authorship, credentials, and reputable domains raise trust. Engines tend to cite expert sources per Search Engine Land’s overview (2024).
- Freshness/recency: Time‑sensitive queries preferentially surface recent sources; studies show high recency in AI Overviews and assistants.
- Provenance/transparency: Stable URLs, clear citations, and traceable sources matter for engines that surface clickable links.
- Structure/machine readability: Semantic HTML, schema, clean headings, and concise factual passages aid indexing, chunking, and extractability.
- Source diversity/corroboration: Multiple independent sources reduce contradiction risk.
- Answerability/directness: FAQ/Q&A sections and short declarative facts perform well in retrieval.
- Engagement signals: Clicks, dwell, feedback, and corrections can shape selection over time.
- Technical health/accessibility: Crawlability, speed, mobile friendliness, and minimal paywalls increase indexation and reliable extraction.
Why the shift matters: GEO signals are operationalized inside modular RAG pipelines, not just ranking algorithms. That means the way your content is split, embedded, retrieved, reranked, and attributed directly affects visibility.
Where GEO Signals Enter a RAG Pipeline
RAG pipelines share a common backbone: ingestion/indexing, retrieval (lexical/dense/hybrid), reranking, selection, and citation/post‑processing. Vendor documentation aligns on these stages—see NVIDIA’s RAG 101 (2023), Cohere’s RAG docs, and Elastic’s hybrid search guidance (2025).
| Stage | What it does | GEO signal touchpoints | Practical tip |
|---|---|---|---|
| Ingestion & Indexing | Crawl/parse pages; split into chunks; embed/store with metadata | Technical health, structure/schema, explicit authorship/date, stable URLs for provenance | Use semantic HTML and schema; keep authorship and dates visible; avoid paywalls and heavy scripts that block crawling |
| Retrieval (BM25) | Lexical matching on terms/headings | Answerable headings, keyword fidelity, definitional sentences | Put crisp, keyword‑rich headings over short factual passages to match TF‑IDF/BM25 |
| Retrieval (Dense) | Vector similarity on meaning | Concise, context‑rich passages; entities; FAQs | Keep facts self‑contained; avoid burying key claims in long prose; add entity names near facts |
| Hybrid Retrieval | Combine lexical + dense (rank fusion) | Structure helps both modes; freshness via filters | Default to hybrid with rank‑based fusion (e.g., RRF) before reranking |
| Reranking | Cross‑encoder re‑scores candidates | Provenance clarity, topical alignment, direct answers | Favor clean, factual passages with explicit entities and source cues; avoid ambiguous copy |
| Selection | Pick top‑k; enforce diversity/freshness | Domain quality gates; diversity; time‑decay | Enable freshness filters; dedupe near‑duplicates; prefer varied, reputable sources |
| Citation & Post‑processing | Attach source metadata; render links | Stable URLs; extractable spans; clean sections | Provide FAQ/definition blocks and consistent citation formatting to ease attribution |
Microsoft Cloud recommends hybrid retrieval, semantic reranking, and query rewriting for production pipelines—see Common RAG techniques explained (2025)—while Elastic’s hybrid search docs (2025) detail practical implementation.
Retrieval Behavior: Lexical vs. Dense vs. Hybrid (and What to Publish)
Lexical retrieval (BM25/TF‑IDF) rewards exact matches and clear terminology. Dense retrieval (embeddings) rewards semantic proximity and context. Hybrid retrieval combines both to improve recall and precision. Here’s the deal: to be selected in real systems, you need passages that work in both modes.
- For headings and definitional blocks, write short, keyword‑faithful sentences that can score well lexically.
- For explanatory passages, include entities, synonyms, and nearby context so embeddings can match meaning.
- Prefer rank‑based fusion (e.g., Reciprocal Rank Fusion) over brittle score mixing; then apply a cross‑encoder reranker. Elastic and Microsoft advocate this sequence; Google Cloud emphasizes groundedness checks downstream.
If you publish only long narrative pages with buried facts, BM25 may miss your key claims, dense retrieval may retrieve irrelevant segments, and rerankers will struggle to find clean, attributable spans. Think of it this way: you’re writing “chunks” for machines and “stories” for humans—do both.
Platform Differences in Citation Surfacing
Citation UI and source selection vary across platforms and change quickly. Studies and vendor observations converge on a few patterns:
- Perplexity: Multiple explicit links per answer, emphasis on real‑time retrieval; observed high recency for time‑sensitive queries and notable representation of user‑generated content sources, according to TryProfound’s platform citation patterns (2025).
- ChatGPT (web‑enabled modes): Fewer visible citations by default, blending pretraining with live grounding; aggregate analyses report heavier reliance on Wikipedia depending on model and browsing mode, per TryProfound’s comparison (2025). For context on brand mentions, see Why ChatGPT Mentions Certain Brands.
- Google AI Overviews (Gemini): Compact source cards/links with strong recency emphasis and alignment to top organic results; periodic recaps document behavior shifts as seen in SE Ranking’s AIO research (2024–2025). If you track regional nuances, review our guide to AIO tracking tools for China.
- Bing/Copilot: Similar to Google in surfacing a modest set of authoritative sources grounded in Bing’s index; newsroom tests have flagged mismatched links in multiple AI search tools, including Bing, per CJR Tow Center’s comparison (2025).
Bottom line: platform heuristics differ, so measure your visibility and citations across engines instead of assuming one set of rules applies everywhere.
Evaluate and Diagnose: A Simple Workflow
You can’t improve what you don’t measure. Separate retrieval metrics from generation metrics and end‑to‑end groundedness, and run a lightweight test regimen.
- Build a query set that represents your audience’s information needs.
- Label chunk‑level relevance for a small sample; compute Precision@k, Recall@k, nDCG, and MRR to understand retrieval quality.
- Evaluate generated answers for groundedness and attribution accuracy with rubric‑based checks or calibrated LLM‑as‑judge workflows.
- Inspect failures and adjust chunking (granularity/overlap), add query rewriting, tune hybrid fusion, or upgrade the reranker.
For a detailed methodology, see EvidentlyAI’s RAG evaluation guide. If you’re formalizing KPIs for AI visibility and answer quality, LLMO Metrics: Measure Accuracy, Relevance, Personalization outlines a practical framework.
Edge Cases and Risks You Should Anticipate
- Chunking pitfalls: Overly coarse chunks bury facts; too fine creates noise. Use structure‑aware splitting with overlap; validate per domain. Guidance appears in vendor docs and research like Google Research’s discussion on sufficient context in RAG (2025).
- Over‑retrieval/noise: Excess context reduces recall on key facts and increases latency; mitigate with rerankers and diversity constraints. See the Pinecone learn series on rerankers.
- Schema spam and provenance gaps: Misused markup or thin content degrades trust; quality gates and deduplication filters can suppress these pages.
- Contradictions and stale caches: Cross‑document conflicts and outdated content induce intermittent hallucination; apply groundedness checks and consider freshness filters.
- Multihop failure: Scattered evidence hurts synthesis; multi‑query retrieval and rank fusion (e.g., RRF) improve coverage.
A Practical Workflow for Content + Engineering (with a Micro‑Example)
Disclosure: Geneo is our product.
Here’s a simple, repeatable alignment checklist you can run monthly:
- Content prep: Update page dates and authorship; add schema and semantic headings; extract short definitional statements and FAQ blocks near the top.
- Indexing review: Confirm crawlability (no blocked resources), stable URLs, and clean rendering. Ensure chunking is structure‑aware with modest overlap.
- Retrieval baseline: Run hybrid retrieval (BM25 + dense) with Reciprocal Rank Fusion; apply a cross‑encoder reranker.
- Diagnostics: Compute retrieval metrics on your query set; audit groundedness and attribution in generated answers.
- Adjustments: If facts are missed, tighten headings or move declarative facts higher; if citations are messy, improve provenance and sectioning; if recency matters, enable date filters or publish changelogs.
Micro‑example: Suppose your “Pricing Models for B2B SaaS” page is long narrative text. After GEO tuning, you add an H2 “What is usage‑based pricing?” followed by a 2–3 sentence, fact‑dense definition with citations, plus a short FAQ. In hybrid retrieval, a BM25 pass now picks up the exact heading and definition; dense retrieval matches the semantic description; the reranker favors the clean, self‑contained passage. Assistants that surface citations more readily attach your stable URL and authorship to the answer card.
You can use Geneo to monitor whether these GEO changes correlate with increased mentions and citations across platforms like Perplexity and Google AI Overviews. It helps teams track AI visibility trends and compare query‑level results over time without making performance claims in the absence of auditable data.
GEO isn’t a buzzword—it's how your content gets chosen as evidence in generative answers. Publish extractable facts with clear provenance, design pages for hybrid retrieval, and instrument evaluation so you can iterate with confidence. If you want a lightweight way to see where your brand is showing up in AI answers, start a free trial and benchmark your current visibility.