
Technical Architecture Behind Generative Engine Optimization (GEO) Platforms
Explore the comprehensive technical architecture behind Generative Engine Optimization (GEO) platforms. Discover ingestion, connectors, tracking, and governance. Read the complete guide now!
Generative Engine Optimization (GEO) is the discipline of improving a brand’s visibility, accuracy, and citations in AI-generated answers—from ChatGPT and Google Gemini to Bing Copilot, Perplexity, and Google’s AI Overviews. If SEO organized the web for ranked lists, GEO organizes your content and signals for answer engines that synthesize, attribute, and sometimes cite. The architecture behind a GEO platform determines whether you can reliably monitor, measure, and improve that visibility.
To keep terms straight: GEO here means Generative Engine Optimization (not geostationary orbit). If you want a primer on why “AI visibility” matters, see the explainer on AI visibility and brand exposure in AI search. For acronym hygiene across GEO, GSVO, GSO, AIO, and LLMO, bookmark this acronyms guide.
What a GEO platform does: the high-level data flow
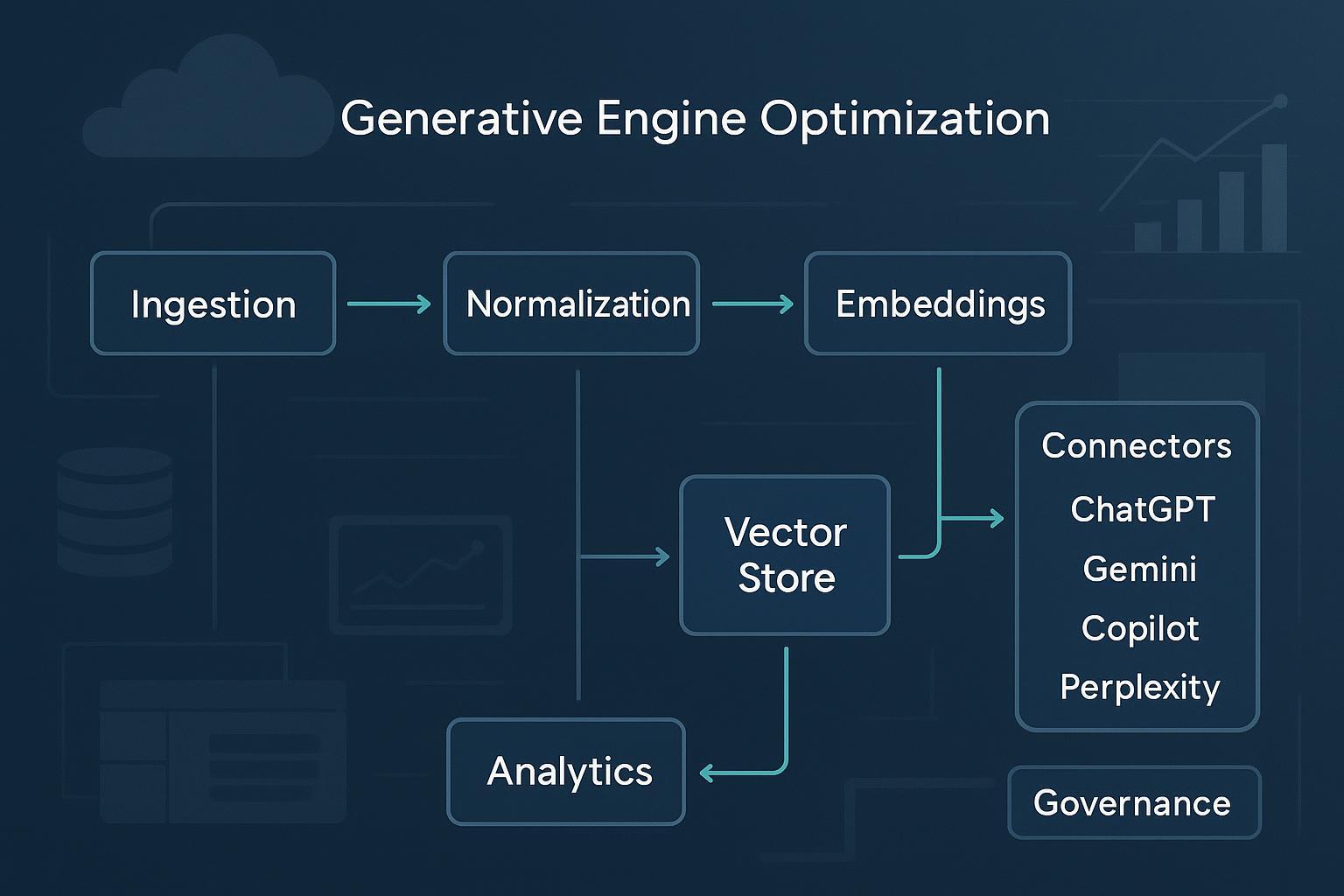
A well-architected GEO platform looks like a cloud-native pipeline:
- Ingestion pulls from crawlers, site maps, CMS exports, APIs, and data lakes—respecting robots.txt and terms of service.
- Normalization cleans, canonicalizes, and validates structured data (JSON-LD/schema.org); it also handles language detection and de-duplication.
- Embeddings encode content chunks for semantic retrieval; versions and hyperparameters are recorded for reproducibility.
- Indexing stores text and vectors in document stores and vector databases for fast similarity search.
- Connectors query AI answer engines (where permitted) and capture outputs, citations, and metadata.
- Tracking analyzes citations and mentions, measuring frequency, share, freshness, and entity accuracy.
- Analytics surfaces visibility, sentiment/stance, model coverage, and trends with alerts.
- Governance enforces privacy, compliance, access controls, and audit trails.
Think of it this way: ingestion and normalization prepare the “ingredients,” embeddings and indexing make them findable, connectors and tracking observe the “chefs” (AI engines), and analytics plus governance tell you what’s working—and what must change.
Ingestion and normalization
Robust ingestion is the backbone of GEO. Cloud providers document scalable RAG-style ingestion patterns that apply directly here: object storage → chunking → embedding → indexing. AWS outlines an end-to-end pipeline for large-scale ML ingestion—including security filtering and orchestration—in this 2024 Big Data Blog walkthrough and a companion security article from late 2024.
Key practices:
- Sources: Combine compliant web crawling, XML sitemaps, CMS/API feeds, and exports from data warehouses or lakes.
- Cleaning and canonicalization: Strip boilerplate, resolve canonical URLs, fix pagination and faceted duplicates.
- Structured data validation: Enforce JSON-LD/schema.org; validate organization, product, FAQ, and review markup.
- Language detection and segmentation: Detect language at document and paragraph levels; partition multilingual sites.
- Chunking strategies: Balance chunk size to preserve coherence while maximizing embedding efficiency; track chunk lineage.
- Embedding jobs: Use managed endpoints (SageMaker, Vertex AI, Azure ML) or trusted APIs; log model versions, dimensionality, and pre/post-processing parameters.
Hybrid schemas (keyword + vector) in services like Azure AI Search are well-documented and help align lexical fields with semantic vectors; see Microsoft’s RAG overview for Azure AI Search.
Multi-engine connectors and constraints
Answer engines differ widely in access and behavior. Your connector layer must respect policies and normalize outputs.
- OpenAI (ChatGPT/GPT models): Full API access for chat/completions with model-dependent rate limits. Outputs don’t include native citation fields by default, so enforce citation prompts or tool outputs and parse the text. See the OpenAI model documentation for current constraints.
- Google AI Overviews (SGE) and Gemini: There’s no public API for AI Overviews, and scraping is prohibited under Google policies. Monitor using compliant workflows and rely on content quality and structured data. For traditional results, Google’s Custom Search JSON API applies; AI features are documented in Search Central’s AI appearance guidance.
- Microsoft Bing Copilot: Extensible in enterprise contexts via Microsoft 365 Copilot Studio (agents/plugins). For web retrieval, Bing Custom Search is available, but there’s no dedicated Copilot summaries API with citation metadata.
- Perplexity: As of late 2025, no official public API is documented. The UI surfaces citations, but programmatic access is not available. Treat scraping as disallowed and re-check policies periodically.
Connector implications: Normalize everything by storing the prompt, answer text, visible citations, timestamps, engine/version, locale, and evidence artifacts; and always respect rate limits and terms of service with backoff, throttles, and audit logs.
Citation and mention tracking
Tracking answers and attributions is how GEO quantifies impact.
- Capture and evidence: Where APIs exist, store structured outputs; otherwise, capture text plus screenshots for audit-ready evidence. Normalize URLs and resolve redirects.
- Measures: Frequency of citation, citation share by engine/domain, freshness/recency, overlap with organic rankings, and entity accuracy (is your brand correctly described?). Analyses in 2025 show variance: Ahrefs found only about 12% overlap between AI-cited URLs and Google top 10 rankings on a long-tail set, while Perplexity displayed higher overlap than other engines.
- Context and caution: Prefer reputable analyses with transparent methods; aggregated trackers can be directional but not definitive. Seer Interactive reports higher CTR when cited in AI Overviews, with methodology caveats; see their September 2025 update.
Misattribution and drift:
- Flag incorrect attributions or outdated facts; maintain a review queue.
- Track model/version drift; a jarring shift in citations or stance can signal content or engine changes.
- Compare against organic SEO baselines to triangulate opportunities.
Sentiment and stance analysis
A GEO platform should aggregate not just “what” engines cite but “how” they portray your brand.
- Methods: Transformer-based classifiers (BERT/RoBERTa families) outperform lexicon baselines for nuanced AI-generated text; aspect-based sentiment analysis (ABSA) reveals polarity by topic (pricing, reliability, support). Peer-reviewed summaries and surveys in 2024–2025 back these choices, including a stance detection evaluation in 2024 and an LLM stance survey from 2025.
- Evaluation: Use macro/micro F1, precision/recall, ROC-AUC, and confusion matrices; document thresholds and calibration.
- Aggregation: Roll up sentence → answer → topic → brand; slice by engine, geography, and time window. Visualize confidence bands to avoid overreacting to low-signal changes.
Storage and indexing options
Vector search is central to GEO retrieval and auditing. Below is a compact comparison of common choices.
| Store | Strengths | Considerations |
|---|---|---|
| OpenSearch (managed or self-hosted) | Hybrid lexical+vector; mature ecosystem; ANN support via knn_vector; good for large corpora | Tune k/num_candidates; consider quantization; plan cluster sizing and observability |
| PostgreSQL + pgvector | SQL-native joins and filters; flexible ANN (IVFFlat/HNSW); simpler ops for teams already on Postgres | Tune lists/probes; watch WAL/replication; dimensionality affects memory/CPU |
| Vertex AI Matching Engine | Managed ANN with auto-scaling and metadata filters; seamless with Vertex pipelines | Cloud lock-in; cost and data locality considerations; design for cold-start/warmup |
Two design notes:
- Hybrid retrieval wins: Combine keyword filters with vector similarity; store rich metadata for precise slices.
- Auditability first: Log similarity scores and parameters used in retrieval to reproduce results and understand shifts.
See official docs for detailed guidance: OpenSearch vector search, pgvector indexing best practices, and Vertex AI Matching Engine.
Analytics layer and dashboards
Decision-makers need crisp dashboards, while engineers need traceable metrics.
- Core KPIs: Visibility coverage by engine/topic, citation frequency/share, sentiment polarity and stance trends, model coverage/version drift, freshness, crawl/index health.
- Data model: Unified fact tables for answers and citations; dimensions for engines, entities, topics, locales, and time; lineage and similarity audit logs.
- Alerting: Threshold- and anomaly-based alerts on visibility drops, sentiment dips, or citation loss; include “explain” links to underlying evidence.
- Agency reporting: Multi-brand rollups, client-ready exports, and SLAs. For multi-brand management and reporting context, see Geneo’s agency capabilities.
When discussing metrics frameworks and evaluation steps, the LLMO metrics guide and AI search KPI frameworks for 2025 are helpful complements.
Orchestration and reliability patterns
GEO platforms are living systems; freshness and reproducibility depend on solid ops.
- Scheduling: Kubernetes CronJobs or workflow engines (Argo/Tekton) to run crawls, re-embedding, schema audits, and freshness checks.
- CI/CD and IaC: Terraform for infrastructure, GitOps for configuration; use blue/green or canary for schema/index changes.
- Observability: Prometheus/Grafana for metrics; centralized logs; distributed tracing for connector latencies.
- Security: Segment networks, enforce role-based access, manage secrets (Vault/K8s Secrets), and apply policy-as-code.
- Reliability: Retries with exponential backoff, idempotent jobs, state locks, and dead-letter queues for failed tasks.
Plural and major cloud tutorials offer practical references for Kubernetes CI/CD patterns; see their workflow examples.
Privacy, compliance, and governance
Monitoring AI engines and processing answer data may touch personal or sensitive information; governance isn’t optional.
- GDPR: Lawful basis and consent (Article 7), automated decision-making safeguards (Article 22), and Data Protection Impact Assessments (Article 35). The EDPB issued opinions in 2024 clarifying controller obligations and human oversight for AI models; see EDPB Opinion 08/2024 on consent and Opinion 28/2024 on AI models.
- CCPA/CPRA: Respect opt-out/Do Not Sell or Share, Global Privacy Control (GPC), and transparent policies; the California AG’s CCPA overview is canonical.
- US sensitive data transfers: DOJ’s final rule implementing Executive Order 14117 (Jan 2025) adds obligations for handling sensitive personal and government-related data; see the Federal Register notice.
- Governance stack: DPIA templates, data minimization, role-based access controls, audit logging, incident response, and vendor diligence. Document roles, responsibilities, and review cadences.
Practical micro-example: monitoring a brand across engines
Disclosure: Geneo is our product. Here’s a neutral, replicable workflow you can adapt.
- Define monitored queries: Branded, product, and category terms across locales.
- Configure connectors: Use compliant APIs where available (OpenAI, Bing Custom Search) and controlled headless browsing with manual review where APIs are absent; store prompts, responses, timestamps, engine/version, and evidence.
- Normalize citations: Parse visible citations; resolve URLs; classify source types (publisher, forum, video). Flag misattributions.
- Sentiment rollout: Run aspect-based sentiment on captured answers (pricing, reliability, support). Aggregate by engine and topic; set alert thresholds.
- Reporting: Build a dashboard with visibility coverage, citation share, sentiment trends, and freshness; export weekly client reports.
This example generalizes across stacks and respects engine constraints. It’s designed to help teams start measuring before pushing optimization changes.
Build vs. buy: decision factors
Should you assemble a GEO stack or adopt a platform?
- Scope and speed: Building grants control but demands ingestion, connectors, storage, analytics, and compliance expertise; buying accelerates time-to-insight.
- Compliance: Platforms with mature governance reduce risk; custom stacks require sustained legal and security attention.
- Maintenance: Expect continuous updates for engine changes, rate limits, and schema evolutions.
- Extensibility: Favor solutions that expose data models, APIs, and export paths to avoid lock-in.
- Cost: Model inference, vector storage, and orchestration add up; evaluate total ownership vs. subscription.
Implementation checklist
A concise, practical checklist to guide your build:
- Ingestion: Identify sources; implement crawling and CMS/API feeds; validate JSON-LD; chunk and embed with versioned models.
- Connectors: Respect engine policies; capture prompts/answers/citations/metadata; throttle and log.
- Tracking: Compute citation frequency/share/freshness/overlap; flag misattributions; retain evidence.
- Sentiment: Deploy transformer-based classifiers; ABSA for aspects; evaluate and calibrate.
- Storage/indexing: Choose OpenSearch/pgvector/Vertex; enable hybrid retrieval; log similarity and parameters.
- Analytics: Build visibility/sentiment dashboards; alerts on drops or drifts; agency exports.
- Orchestration: Kubernetes workflows; Terraform IaC; observability; retries and DLQs; secrets management.
- Governance: DPIA, consent tracking, RBAC, audit logs, incident response, vendor due diligence.
Next steps
Ready to evaluate or implement a GEO architecture? Start by instrumenting measurement before optimization—otherwise you’re flying blind. For background reading, revisit AI visibility and brand exposure, the GEO/GSVO/AIO acronyms explainer, LLMO metrics for evaluation, and KPI frameworks for AI search. If you manage multiple brands and clients, see our agency page for multi-brand reporting context.
If you’d like to explore a ready-to-use platform that supports multi-engine monitoring, citation tracking, and sentiment analysis with governance features, you can evaluate Geneo—keeping this guide’s vendor-agnostic principles in mind.