
GEO Audits Explained: Practical Guide to AI Search Visibility
Discover what GEO audits are, why they matter, and how to measure AI answer visibility. Includes key metrics, workflows, and practical guidance.
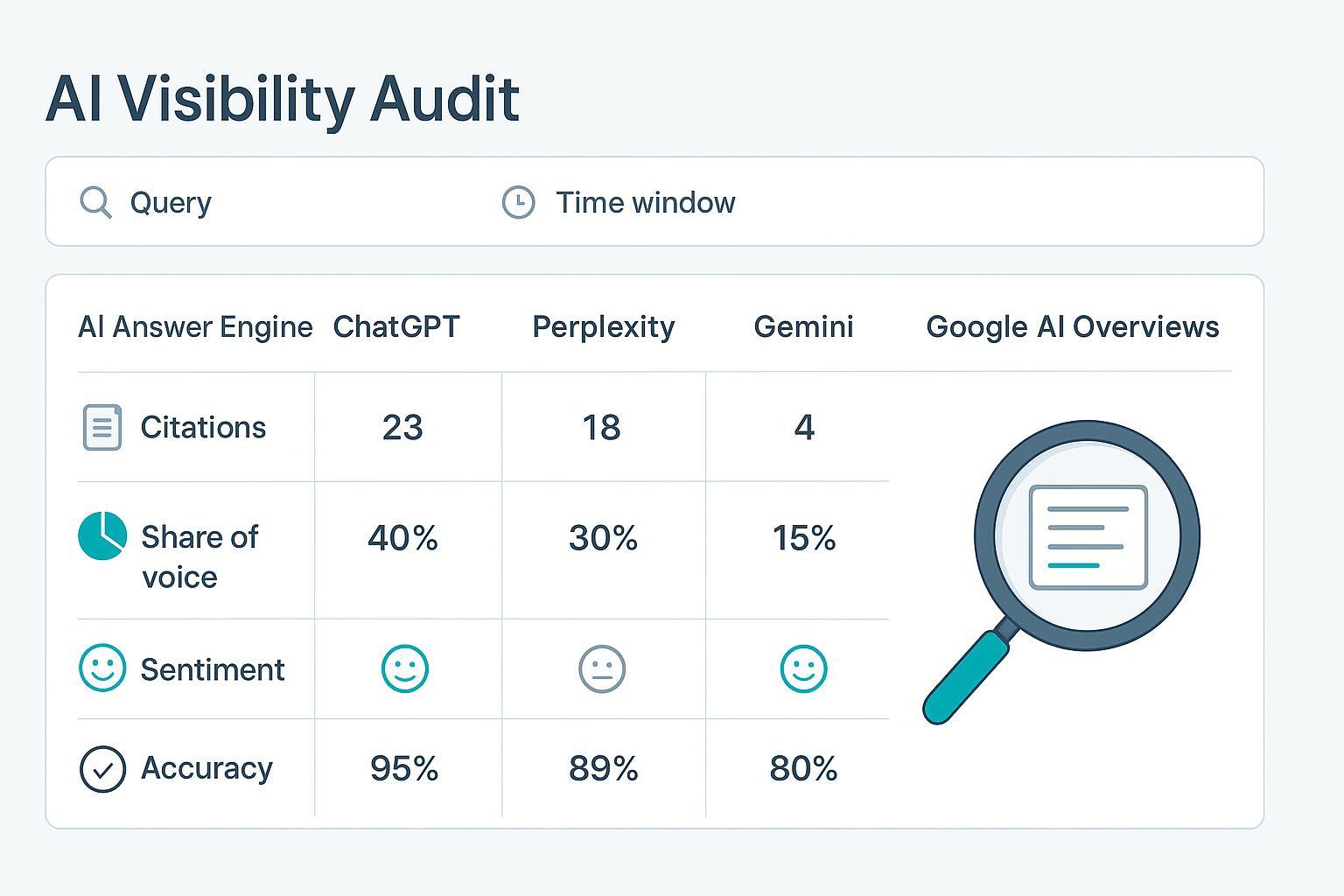
If “GEO audits” made you think of geography, you’re not alone. In marketing, GEO stands for Generative Engine Optimization—the practice of improving a brand’s inclusion and citation in AI‑generated answers across engines like ChatGPT, Perplexity, Gemini, and Google’s AI Overviews. Think of it this way: classic SEO optimizes for ranked lists of links; GEO optimizes for being summarized, named, and linked inside an answer.
What “GEO” means (and what it doesn’t)
Generative Engine Optimization (GEO) emerged as AI answer engines began to summarize the web and attribute sources. Industry coverage traces a formal introduction to December 2023 research that showed adding relevant statistics, quotations, and citations can increase visibility in AI answers—especially for sites that aren’t already dominating traditional SERPs, as summarized by Search Engine Land’s overview of the GEO framework (2023) and their what is GEO explainer (2024).
A GEO audit is a structured assessment of how often—and how well—your brand appears in AI answers. It documents presence, linked citations, accuracy, sentiment, and share of voice across engines and query classes, then translates findings into fixes and a re‑test plan. If you’re new to the concept, this primer on AI visibility and brand exposure in AI search provides helpful context.
Why GEO audits matter now
Here’s the deal: AI systems don’t just list pages; they synthesize and recommend. Your content either shows up as a named source inside an answer—or it doesn’t.
- Google’s guidance explains that AI features, including AI Overviews, surface links from eligible, indexed pages and aim to show a broader range of sources, with success still tied to helpful, reliable, people‑first content and E‑E‑A‑T. See Google’s “AI features and your website” page (2025) and the follow‑up on succeeding in AI Search (2025).
- OpenAI’s search‑enabled experiences provide inline citations and a Sources view so users can inspect attribution, as noted in OpenAI’s SearchGPT prototype announcement (2024).
- Perplexity emphasizes answer‑first results with links to sources but does not publish publisher‑facing criteria for selection. Treat it as citation‑forward yet algorithmically opaque; see Perplexity’s getting started guide (accessed 2025).
If you ignore GEO audits, you risk fading from high‑intent conversations where buyers ask engines for “best,” “compare,” or “pros and cons.” Audits make your inclusion measurable and your roadmap repeatable.
What a GEO audit covers
A good audit is reproducible. It spans engines, queries, measurement, and evidence:
- Engines to test: ChatGPT with search enabled, Perplexity, Gemini, and Google AI Overviews (regional teams may prioritize Google first). For Google specifics across markets, see this overview of AI Overview tracking tools and regional strategy.
- Query classes: branded (“about [brand]”), category/problem (“best [type] for [use case]”), comparison (“[brand] vs [competitor]”), how‑to, and buying‑guide terms.
- Measurements: presence and citation frequency, accuracy of brand facts, sentiment tone, and share of voice across competitors.
- Competitor benchmarking: include 3–5 peers; record who gets mentioned and linked, and in what context.
- Evidence logging: capture prompts, engine/model, timestamps, screenshots, and cited URLs; re‑test in consistent time windows to control for updates.
The metrics that make GEO audits actionable
You can’t improve what you don’t measure. These practitioner metrics turn observations into targets. For deeper methodology, see LLMO metrics: measuring accuracy, relevance, personalization.
| KPI | What it tells you | Formula | Evidence you need |
|---|---|---|---|
| AI‑Generated Visibility Rate (AIGVR) | How often your brand appears in AI answers | (queries with presence ÷ total tested queries) × 100 | Prompt logs + screenshots |
| Citation Frequency | How many linked citations point to your domain | Raw count per engine/query class | Screenshots + URL list |
| Share of Voice (SOV) | Your slice of mentions/citations vs. competitors | (your mentions or citations ÷ total across tracked brands) × 100 | Brand‑normalized logs |
| Accuracy Rate | Correctness of answers about your brand | (answers with no factual errors ÷ total audited answers) × 100 | Canonical refs + citations |
| Sentiment Mix | Tone in which your brand appears | % positive / neutral / negative | Annotated responses + rubric |
Track per engine and by query class. Repeat measurements in defined windows (e.g., quarterly) so you can compare apples to apples as models evolve.
A practical 60–90‑day workflow
A GEO audit isn’t a one‑and‑done; it’s a short cadence to baseline, fix, and verify.
- Week 0–1: Baseline. Build a prompt bank across branded, category, comparison, and “best of” queries. Test in ChatGPT (with search), Perplexity, Gemini, and Google AI Overviews. Log AIGVR, citations, SOV, accuracy, and sentiment. Save screenshots and exports.
- Week 2–4: Findings and fixes. Prioritize gaps: missing presence on high‑intent queries, thin citations, factual errors, or negative tonal contexts. Update content with clear headings, explicit claims, stats, quotes, and references. Strengthen entity signals (author bios, org info), and add appropriate structured data that matches visible content.
- Week 5–8: Re‑test and iterate. Re‑run the same prompt bank; quantify deltas. Expand into adjacent queries where early wins appear. Compare engines and investigate misattributions.
- Week 9–12: Codify and scale. Standardize your scoring model and quarterly re‑audit. For critical categories, add ongoing monitoring.
Disclosure: Geneo is our product. In practice, a monitoring layer helps teams keep evidence clean and comparisons fair. For example, Geneo can be used to track multi‑engine presence, citation frequency, and sentiment over time, storing prompt logs and screenshots so your Week 5–8 retests use the exact same inputs.
Pitfalls and governance
A few patterns can derail GEO work. Keep these in check:
- Overfitting to prompts. If you only test one phrasing, you’ll optimize for that phrasing. Use balanced query sets and re‑word variations.
- Conflating SEO with GEO. Durable SEO foundations still matter, but GEO success is measured by mentions and citations inside answers, not just rankings and clicks.
- YMYL caution. For health, finance, and other sensitive topics, raise your bar: stronger sourcing, human review, and conservative claims.
- Misattribution and hallucinations. Compare engines, verify cited facts against canonical sources, and keep an auditable trail. When answers link out, users can inspect attribution—Google AI Overviews, OpenAI’s search‑enabled experiences, and Perplexity all support linked sources.
Next steps
If you’re starting from zero, pick 40–60 queries across the classes above, run your baseline, and log everything. Then decide which fixes could move the needle fastest—usually clearer claims and better citations on high‑intent pages—before your Week 5–8 retest.
For ongoing monitoring and multi‑brand operations, consider Geneo’s platform for agency setups and collaboration; it supports teams offering GEO audits and tracking across AI engines without reinventing the workflow.