
Ultimate Guide to AI Search Instability Tracking Tools by Query Type
Discover the complete guide for agencies to track AI search instability by category and query type—learn daily snapshot workflows and the best SaaS review monitoring tools. Schedule your Geneo demo today.
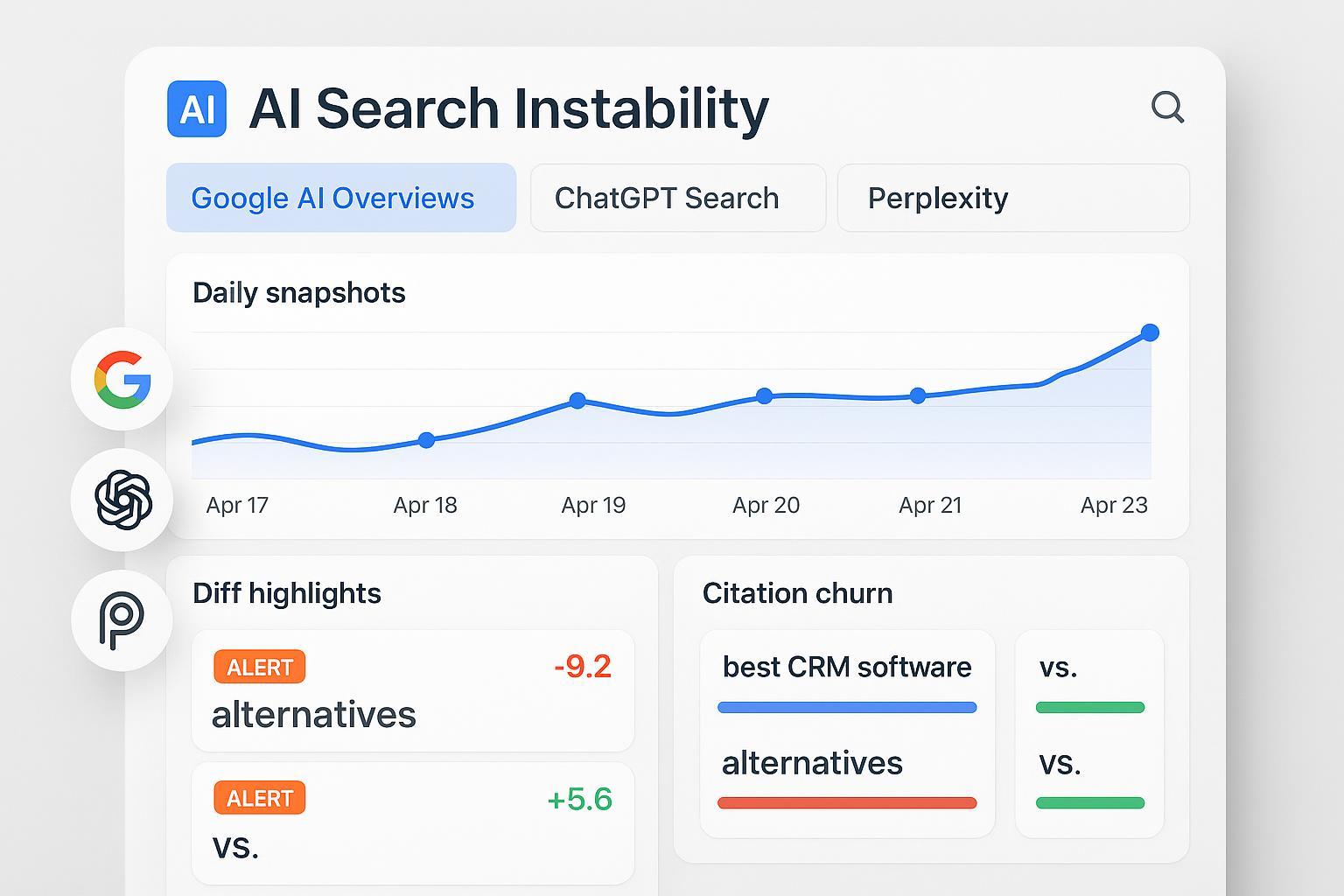
If your agency lives and dies by SaaS leads, the rise of AI answer engines has changed the playing field. One day your review appears in Google’s AI Overview or a ChatGPT Search summary; the next day it’s gone, replaced by different sources. That instability—what we’ll call citation churn and answer volatility—can quietly siphon mid‑funnel discovery and share of voice even when your classic blue‑link rankings remain intact.
This ultimate guide gives you a practical, repeatable monitoring plan built for SaaS and software review intents: a clear taxonomy, a daily snapshot methodology you can run, the tool categories that make it feasible, and a procurement framework to choose the right stack. You’ll also see a neutral, real‑world workflow example and a single next step to take today.
What “AI Search Instability” Really Means for SaaS & Software Reviews
AI search instability is the rapid, non‑transparent shifting of which sources are surfaced or cited in AI‑generated answers. It’s distinct from model drift (gradual performance changes) and matters because reviews, comparisons, and alternatives content are mid‑funnel lifelines for SaaS buyers.
Independent analyses in 2024–2025 documented high volatility around Google AI Overviews (AIOs) and reported meaningful click‑through declines on affected queries when summaries appear. For example, Seer Interactive’s cohort studies in 2025 show material CTR impact patterns for publishers when AIOs trigger, while Google emphasizes that overviews aim to help users explore and include links to “go deeper.” Rather than assert a single figure, treat the effect as query‑set dependent and monitor your own corpus. For background, see the patterns summarized in Seer’s September 2025 update in “AIO Impact on Google CTR” (Seer Interactive, 2025) and publisher‑side adaptations outlined by Search Engine Journal’s 2025 overview.
For SaaS review intents—“best [category] software,” “alternatives to [brand],” “[brand] vs [brand]”—instability directly affects:
Visibility in comparative lists and summaries
Inclusion/exclusion as a cited source
Sentiment and framing of pros/cons
If you’re not tracking these answers and citations over time, you’re blind to share‑of‑voice swings that your clients will feel as lead volatility.
How Engines Differ (Google AI Overviews vs. ChatGPT vs. Perplexity)
Each engine has distinct retrieval, grounding, and citation behaviors—your monitoring must match those differences.
Google AI Overviews (AIO): Evolving from SGE, AIOs present grounded summaries with links. Volatility shows up as shifts in which domains get cited and how summaries are composed. Monitoring needs daily capture of rendered text plus cited URLs and titles, then diffing across time. Baseline official context appears in Google’s product communications and Search updates; see references in your internal runbooks alongside industry studies.
ChatGPT Search (OpenAI): In late 2024, OpenAI introduced a web search mode powered by a fine‑tuned GPT‑4o. In search mode, ChatGPT shows a summary with links; outside search, it may respond from internal knowledge with limited citations. Your pipeline should record whether search/browsing was used and capture any linked sources. See OpenAI’s “Introducing ChatGPT Search” (2024) and the help doc on ChatGPT search for mode specifics.
Perplexity: Perplexity is citation‑forward by design and offers modes like Web, Academic, and Deep Research, with inline links and source cards. Monitoring should log mode settings and track citation domain share over time (e.g., which review sites dominate for your categories). Terms require attribution when publishing outputs; see Perplexity’s Terms of Service for compliance considerations.
Think of it this way: you’re watching three different “editors” summarize the same topic. Your job is to capture what they published each day, who they credited, and how much that changed.
Intent‑First Taxonomy for SaaS/Software Review Queries
Organize your monitoring around buyer intent segments. Tagging by intent makes your reporting meaningful and your alerts actionable.
Comparative: “best [category] software,” “top [category] tools,” “… for [persona/use case]”
Head‑to‑head: “[brand] vs [brand]”
Alternatives: “alternatives to [brand]”
Pricing: “[brand] pricing,” “[category] pricing”
Reviews/feature deep‑dives: “[brand] reviews,” “pros and cons,” “AI features,” “security/compliance [brand]”
Start with 100–300 queries spanning your clients’ core categories and competitors. Use short tags like “comp,” “h2h,” “alts,” “pricing,” “reviews,” plus category tags (e.g., “project‑management,” “CRM”). This allows rollups by intent and category as soon as you have two weeks of data.
If you’re new to Generative Engine Optimization (GEO) and AI visibility concepts, skim Geneo’s overview of GEO and multi‑engine visibility for shared definitions like Brand Visibility Score.
The Daily Snapshot Methodology (hands‑on)
Your goal is simple: capture immutable snapshots of answers per query per engine, every day, then diff them and alert on meaningful changes.
Snapshot schema and storage
Request context: query string, system instructions (if any), engine mode (AIO, ChatGPT Search on/off, Perplexity mode), region, timestamp
Raw response: HTML and screenshots; normalized plaintext
Structured map: title, summary, bullets, any extracted sections
Citations array: URL, title, publisher, snippet
Model metadata: provider, model ID/version, parameters
Content digests: SHA‑256 of normalized text; semantic hash via embeddings
Provenance: collector version, run ID, retention tier
A practical north star is to keep immutable versions for 90 days in “hot” storage. For data lifecycle considerations, AWS Prescriptive Guidance on gen‑AI data provides helpful checklists for versioning and retention.
Diffing techniques
Preprocess: normalize whitespace, punctuation, dates, and IDs; store canonical plaintext
String diffs: Levenshtein edit distance, shingle‑based Jaccard; flag changed fields (e.g., title changed, bullets reordered)
Semantic diffs: embed text blocks with a fixed model; compare cosine similarity between consecutive snapshots; weight title/summary/bullets (e.g., 30/50/20)
Hybrid instability score: combine normalized string distance with semantic distance (1 − cosine similarity) into a single metric
Useful components include Microsoft Playwright for browser capture, sentence‑transformers for embeddings, and Faiss for fast similarity search.
Alert thresholds and cadence
Stable/no action: cosine ≥ 0.995 and Levenshtein ≤ 0.5%
Minor change (log): cosine 0.98–0.995 or Levenshtein 0.5–2%
Medium change (notify): cosine 0.95–0.98 or Levenshtein 2–10% or structural changes to key fields
Major change (alert): cosine < 0.95 or Levenshtein > 10% or significant citation turnover (e.g., top domain replaced or ≥50% list change)
Cadence: daily snapshots for evergreen SaaS review queries; 2–4×/day during known updates or product launches; weekly rollups and monthly retros. Store 90 days hot; archive beyond that.
Tool Categories and Where Each Fits
Below is a practical map of tool classes you can deploy. Choose one primary path and a backup option for resilience.
Category | What it tracks | Best for SaaS review intents | Typical refresh cadence |
|---|---|---|---|
AIO‑specific trackers | Visibility in Google AI Overviews, quote‑level changes, citations, sentiment | Quickly see if your reviews/lists appear in AIOs and how they shift | Daily; spike during core updates |
Prompt/LLM visibility analytics | Presence and share of voice across ChatGPT/Perplexity; prompt types; sentiment | Monitor whether brands are mentioned and how often across engines | Daily to weekly |
Synthetics/observability | Scripted browser tests to capture rendered answers and citations across UIs | Reliable, scheduled capture when AI‑specific tools fall short | Daily; flexible schedules |
Open‑source DIY stack | Custom capture, diffing, embeddings, alerts using OSS components | Maximum control, deep customization for agency workflows | Daily; configurable |
Representative references for market context: major roundups of AIO trackers such as SitePoint’s 2025 “best AI Overviews trackers” list can help you shortlist vendors, while you can adapt observability platforms (e.g., Datadog, Catchpoint, Checkly, New Relic) for scheduled captures when AI‑specific features lag.
If you need white‑label client reporting and agency‑grade dashboards across engines, review your options carefully. For context on agency workflows and white‑label needs, see Geneo’s agency page.
A Practical Workflow Example (Disclosure: Geneo is our product)
Here’s a neutral, replicable micro‑example of how an agency could implement the daily snapshot methodology for “best [category] software” and “alternatives to [brand]” queries.
Tag the query set by intent and category. Create lists for “comp,” “alts,” “h2h,” “pricing,” and “reviews,” filtered to your SaaS verticals.
Schedule daily cross‑engine probes. Capture AIO summaries with citations; run ChatGPT in Search mode where relevant; log Perplexity’s mode and citation domain mix.
Store immutable snapshots and compute hybrid instability scores. Trigger alerts when citation turnover exceeds 50% or when your brand drops from “best [category] software” answers.
Generate weekly white‑label summaries. Show share‑of‑voice changes, citation churn, and recommended remedial actions (e.g., refresh comparison pages, add structured data, update pros/cons blocks).
Using Geneo as an example platform, agencies can tag SaaS review prompts, monitor multi‑engine visibility, and export client‑ready reports under a custom domain. Keep your pipeline objective: your data structure, thresholds, and cadence are portable across tools.
Procurement Decision Framework for Agencies
When you evaluate tools, use criteria that map to your SaaS review priorities:
Engine coverage: Google AIO, ChatGPT with search/browsing, and Perplexity; capture of citations and brand mentions
Refresh frequency and stability: daily minimum; ability to spike cadence; historical retention with high‑quality diffs
Segmentation and tagging: category/intent labels; query list management; metadata for rollups
Share of voice (SOV): quantifies brand presence in answers; tracks changes and citation turnover
White‑label and reporting: client‑ready dashboards, custom domains (CNAME), scheduled exports
API and integrations: BI access, webhooks/alerts, governance controls, audit trails
Cost and scalability: pricing per keyword/prompt vs. per seat; predictable costs for daily snapshots
A helpful question to ask vendors: How do you version snapshots and surface diff severity? If they can’t show digest/embedding‑based comparisons, your analysts will be stuck doing manual reviews.
Implementation Pitfalls and How to Avoid Them
Not recording context. If you don’t log engine mode (e.g., ChatGPT Search on/off) or Perplexity’s setting, your diffs will conflate behavior changes with configuration changes.
Ignoring citation turnover. Visibility isn’t just “are we mentioned?”—it’s which domains dominate and how that shifts; track domain shares and turnover rates.
Over‑ or under‑sensitive thresholds. Tune your hybrid score with backtests; major changes should match business impacts like brand disappearance from “best [category]” answers.
Brittle UI selectors. Synthetics break when UIs change; prefer robust capture strategies (screenshots + HTML + text extraction) and keep selectors minimal.
Compliance gaps. Respect engine terms, especially when publishing outputs; for Perplexity, review its Terms of Service and attribute appropriately.
For volatility examples and why citation tracking matters across engines, see this Geneo blog discussion of AI visibility during Google updates.
Your Next Step
If you manage SaaS review visibility for clients, set up your first 150–200 intent‑tagged queries and start daily snapshots this week. Then consolidate weekly into white‑label summaries with share‑of‑voice changes, citation churn, and recommended fixes.
Ready to see this in action across ChatGPT, Perplexity, and Google AI Overviews? Schedule a Geneo platform demo to explore an agency‑first workflow that supports tagging, multi‑engine monitoring, and client‑ready reports.