
How AI Search Models Decide Information Priorities
Understand how AI search models set information priorities, key ranking signals, and how brands can optimize for AI answers and citations.
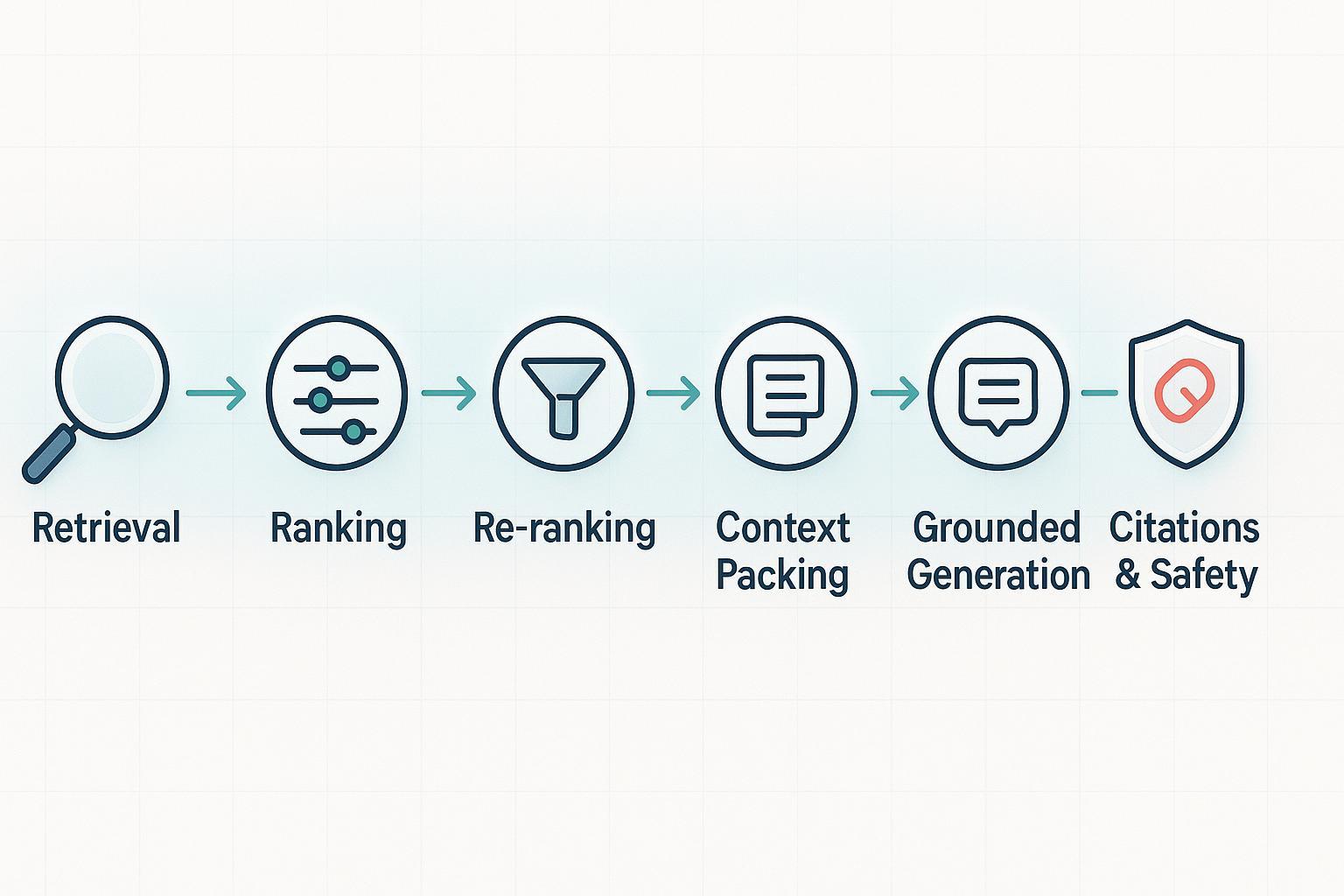
What determines which sources get cited—and which ideas make it into an AI answer—when you ask ChatGPT, Perplexity, or Google? In other words, how do these systems set their “information priorities”? If you work in SEO, GEO, or brand management, understanding this decision flow helps you shape content that’s more likely to be retrieved, selected, and attributed.
The Answer Pipeline in Plain English
Think of an AI answer as a funnel followed by a sifter. First, the system grabs a broad set of potentially relevant passages quickly (the funnel). Then it carefully re‑scores those passages to pick the few that truly fit your question (the sifter). Finally, it crafts a grounded response and shows where the evidence came from.
Most production systems follow a pattern:
- Fast retrieval and initial ranking: The query is matched to documents using dense semantic embeddings—often combined with classic keyword scoring like BM25—in “hybrid” search to maximize recall. Microsoft recommends hybrid retrieval and chunking in its RAG guidance to balance speed and relevance, and explains the retrieval phase clearly in the RAG information retrieval overview.
- Re‑ranking: A second‑stage model (commonly a cross‑encoder or an LLM‑based scorer) rescans the top candidates to find the most semantically aligned passages. NVIDIA describes reranking as a precision boost after fast recall in “Enhancing RAG Pipelines with Re‑Ranking” (Developer Blog), and Zilliz’s education hub defines rerankers and when to apply them in “What Are Rerankers?”.
- Context/evidence packing: The best passages are deduplicated, compressed, and arranged under token limits so key evidence fits the prompt.
- Grounded generation: The LLM synthesizes an answer tied to retrieved evidence to reduce hallucinations. Microsoft frames this “grounding” approach across Copilot and Azure patterns.
- Attribution and safety: Links and source identifiers accompany the answer to support verification, and content safety filters check policy boundaries. Microsoft’s Copilot materials describe hyperlinked citations and safety layers in the Transparency Note for Microsoft Copilot.
The Signals That Steer What Shows Up
Information priorities emerge from how these signals are scored and balanced during retrieval, reranking, and generation.
Semantic relevance
This is the core: does a passage directly answer the query? Dense vector similarity (embeddings) finds semantically related text even without exact keywords. Hybrid search blends that with lexical scoring (e.g., BM25) to catch exact‑match terms. Microsoft’s RAG guidance recommends hybrid retrieval to maximize recall before precision tuning.
Authority and E‑E‑A‑T
Systems emphasize sources that demonstrate experience, expertise, authoritativeness, and trustworthiness. Google repeatedly underscores rewarding helpful, reliable content in its guidance around AI in Search; its product explainer for AI Overviews notes grounding answers in high‑quality web results. See Google’s AI Overviews announcement (Search Blog) and the Search Central note on AI content and E‑E‑A‑T.
Freshness and recency
When topics move fast, freshness matters. Google has stated it applies extra care for sensitive or breaking‑news topics and does not always trigger overviews there, while systems like Perplexity ground answers in current web data via retrieval. For grounding and real‑time results, see Perplexity’s Search API quickstart.
User intent and conversational context
Answer engines track the nuance of your query and the conversation so far. In enterprise scenarios, Microsoft allows grounding in a user’s accessible content, while web mode centers on public sources. This context affects which passages are prioritized.
Diversity, contradiction, and safety filters
Providers do not publish explicit “conflict resolution” algorithms. Instead, they emphasize grounding in credible sources, applying safety filters, and limiting risky triggers. NVIDIA documents guardrails used in production stacks, including content filters and groundedness checks, in NeMo Guardrails guidance.
Provenance and citation fidelity
Transparent citations help you verify answers and audit what’s prioritized. Google’s AI Overviews show links next to the summary; Microsoft Copilot uses hyperlinked citations; Perplexity displays inline references and structured outputs via its API.
If you’re newer to this space and want a broader view of how brand exposure works inside AI answers, our explainer on AI visibility and brand exposure in AI search walks through visibility concepts and measurement basics.
Re‑ranking: The Precision Engine
Re‑ranking is where coarse recall becomes fine selection. A reranker revisits the top‑k candidates and assigns a higher‑fidelity score to passage–query pairs.
- Cross‑encoders vs bi‑encoders: Bi‑encoder retrieval encodes queries and documents separately for speed; cross‑encoders jointly encode them with attention, usually achieving higher precision at the cost of latency. Zilliz’s guide “What Are Rerankers?” and NVIDIA’s post on re‑ranking explain why cross‑encoders are commonly used to condense top‑100 results into a small, high‑quality set for the LLM.
- Quality vs latency: Reranking adds compute—hundreds of milliseconds to seconds depending on candidate count and model size—but it improves precision, reduces noise, and focuses the LLM on evidence that actually answers the query.
- Outcome: Better groundedness and fewer hallucinations, because the generation step is fed cleaner, more relevant context.
Guardrails and Trust: From Grounding to Attribution
Guardrails keep outputs safe and tied to evidence:
- Grounded generation: Answers are constructed with retrieved passages, not just model priors.
- Safety and policy filters: Content moderation, jailbreak detection, topic boundaries, and PII masking protect users and brands. NVIDIA’s guardrails article above outlines layered protections.
- Citation transparency: Hyperlinked sources or inline references allow verification. Microsoft details this in its Copilot Transparency Note.
How Providers Differ (Concise, Useful Comparisons)
- Google AI Overviews: Combines a customized LLM with existing Search ranking systems to ground answers in high‑quality web results, and presents links next to the overview. Google emphasizes care around sensitive topics in its AI Overviews announcement.
- Microsoft Copilot (Bing): Centers on high‑ranking content, provides hyperlinked citations, and can ground on enterprise data that a user is authorized to access. See Microsoft’s Transparency Note.
- Perplexity: Uses hybrid retrieval and displays inline citations, with a Search API that returns structured, real‑time results suitable for grounding.
Practical Workflow for Brands (With One Disclosed Example)
Here’s the deal: you can’t control proprietary weights, but you can align to the signals these systems use.
- Publish verifiable, helpful content. Use clear headings, concise passages, and cite sources. Add dates or versioning when recency matters.
- Structure for retrieval. Include answerable snippets (FAQs, summaries) that rerankers can select cleanly.
- Monitor citations and sentiment across engines. Differences may reflect grounding choices and safety thresholds, not just your content.
- Respond with updates. Where you see outdated references or missing context, refresh the page and add a clear, citable passage.
Disclosure: Geneo is our product. As a practical example, you can use Geneo to monitor which sources cite your brand in ChatGPT, Perplexity, and Google AI Overviews, and compare sentiment and recommendation types over time. For a deeper look at why certain brands get mentioned, see Why ChatGPT Mentions Certain Brands. If you work with multiple clients, our agency workflow overview outlines how teams track and report multi‑brand visibility.
Measurement and KPIs That Actually Help
Measure what the pipeline prioritizes, not just raw traffic.
- Citation rate: How often your domains appear as cited sources in AI answers for target queries.
- Sentiment distribution: The ratio of positive/neutral/negative mentions.
- Recommendation type: Are you cited as an example, a recommended provider, a definition source, or a cautionary note?
- Freshness alignment: How current the cited page is versus query needs.
For a metrics framework tailored to AI search visibility, see LLMO metrics for accuracy, relevance, and personalization.
| Signal prioritized | What to publish or update | Why it helps |
|---|---|---|
| Semantic relevance | Concise, answerable passages with clear headings; include the key terms users actually use | Improves hybrid retrieval recall and reranker precision |
| Authority (E‑E‑A‑T) | Author bios, citations, original data, transparent methods | Signals trustworthiness to ranking systems |
| Freshness | Update date/version, recent examples, changelogs | Aligns with queries where recency is essential |
| Context fit | FAQs and scenario pages that match query intent; add conversational clarifications | Helps engines pick passages that match intent and history |
| Provenance | Link out to canonical sources; include permalinks and references | Makes citations cleaner and verification easier |
Common Pitfalls and How to Course‑Correct
- Chasing “secret weights.” Providers don’t publish exact formulas. Focus on helpful content, clean passages, and verifiable evidence.
- Optimizing for one engine only. Cross‑engine differences are normal; monitor across Google, Copilot, and Perplexity and adapt.
- Ignoring provenance. If your pages are hard to cite—no clear titles, unstable URLs—answer engines may prefer cleaner sources.
- Overlooking safety context. Topics that trip filters may reduce visibility. Keep content neutral, factual, and policy‑safe.
What This Means for Your Next Quarter
Information priorities aren’t mystical—they’re the result of fast recall, careful reranking, grounded synthesis, and transparent citations shaped by authority, relevance, and freshness. Think of it this way: if your content is easy to retrieve, precise enough to rerank, and cleanly citable, it has a better shot at being included in answers users actually read. Start by tightening your passages, refreshing key pages, and setting up cross‑engine monitoring. Then iterate based on what the systems cite, not assumptions about hidden weights.