
AI-Search Buyer Journey Mapping for SaaS: Ultimate Guide
Discover the ultimate guide to mapping SaaS buyer journeys in AI search. Actionable workflows, stage touchpoints, and expert measurement strategies.
When your buyer can ask an AI, “What’s the best [category] for [use case] and how do I deploy it?” and get a synthesized shortlist plus an implementation outline, you’re not fighting for clicks—you’re competing for authority. The journey isn’t gone; it’s compressed. Which touchpoints still matter, and how do you map them without guessing?
Why AI search is compressing SaaS buyer journeys
Several forces have converged. MarTech reports that AI answers increasingly assemble case studies, comparisons, and ROI snippets in a single interaction—effectively compressing research and evaluation into fewer steps. Their editors describe how authority and citability outweigh raw traffic in “AI search is collapsing the B2B buyer journey” (2025) and related coverage. McKinsey’s recent work on omnichannel B2B growth shows buyers blending channels and adopting genAI tools in commercial workflows, reinforcing the shift toward consolidated, AI-assisted research—see “Five fundamental truths: how B2B winners keep growing” (2024–2025).
On discovery surfaces, click patterns are changing. Previsible’s 2025 analysis of 1.96M sessions suggests AI-driven referrals remain relatively small but unusually intent-dense, with visits leaning toward evaluation pages like pricing and comparison content—referenced in “The State of AI Discovery (2025)”. Meanwhile, Google clarifies that AI Overviews pull from the broader web and surface links in multiple formats, emphasizing eligibility via people‑first, policy‑compliant content; see Google’s AI features documentation and the March 2024 core update and spam policies.
If more evaluation happens inside the answer itself, the mandate is clear: build and maintain assets that third‑party engines deem citable, trustworthy, and current. That’s the linchpin for your journey map.
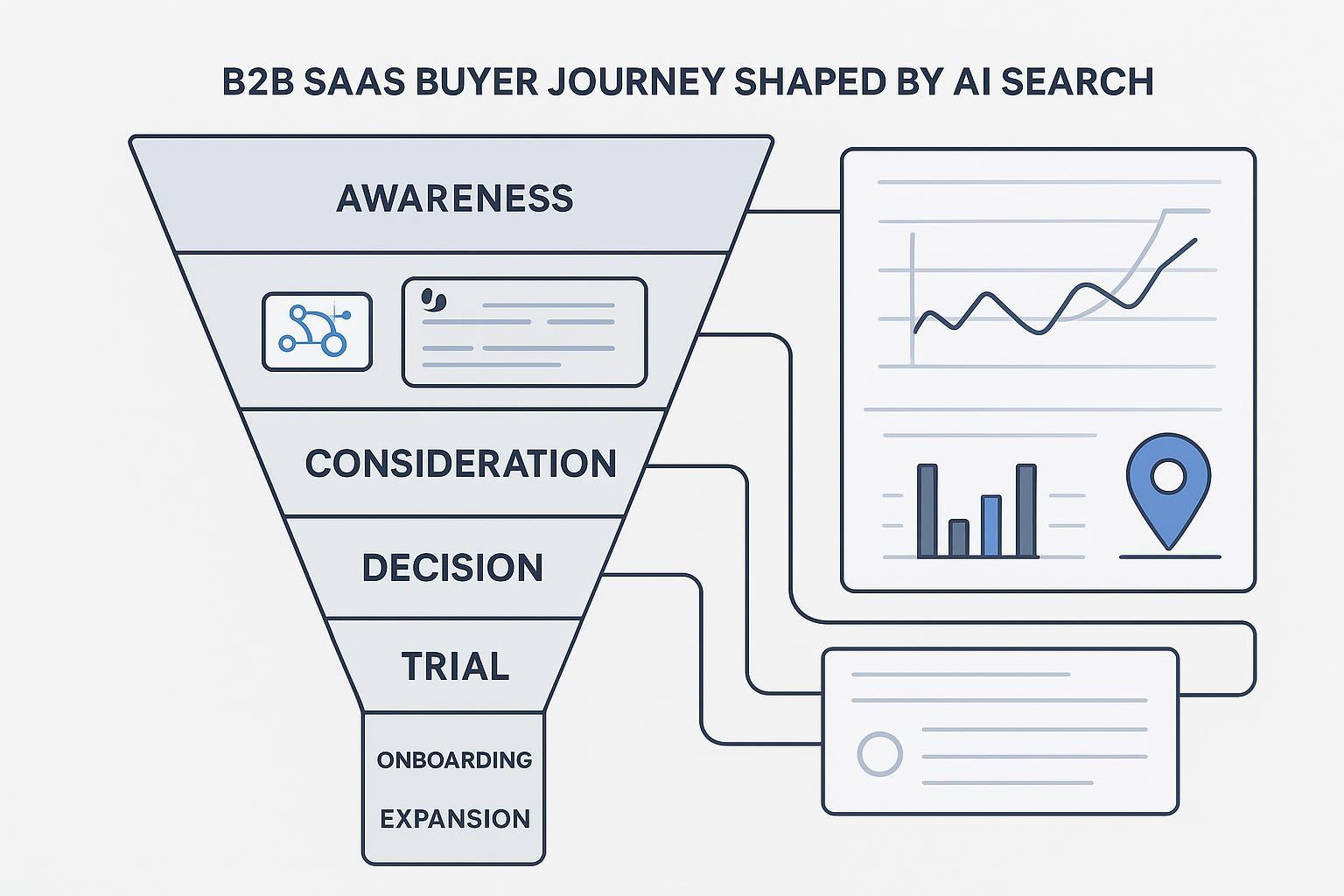
The six‑stage map with AI touchpoints
Think of the SaaS journey as the same backbone—Awareness → Consideration → Decision → Acquisition/Trial → Adoption/Onboarding → Expansion—but with AI surfaces layered across every step.
| Stage | Typical AI touchpoints | Priority assets for citability | Primary KPIs |
|---|---|---|---|
| Awareness | Google AI Overviews summarize problems; Perplexity aggregates credible primers; ChatGPT drafts option sets from known entities | Expert explainer posts, glossary pages, FAQ blocks with JSON‑LD (Organization, SoftwareApplication, FAQPage) | Brand mentions in AI answers; branded search lift; qualified site landings |
| Consideration | Perplexity/ChatGPT comparisons pull reviews, analyst notes, implementation guides | Comparative content with sources, case studies with methods, integration docs, review hygiene (G2/TrustRadius) | Shortlist inclusion signals; visits to comparison/pricing pages |
| Decision | AI answers surface pricing assumptions, ROI models, deployment and security details | Transparent pricing, ROI calculators with methodology, security/compliance pages, procurement guides | Demo requests, pricing tool engagement, security page dwell |
| Acquisition/Trial | Engines recommend trials/sandboxes and onboarding guides | Friction‑light signup, quickstart docs, success criteria checklists | Trial starts, PQLs, activation within N days |
| Adoption/Onboarding | AI surfaces “how to” tasks and integration steps | How‑to libraries, integration playbooks, video walkthroughs | Feature adoption, time‑to‑value, support deflection |
| Expansion | AI highlights advanced use cases, benchmarks, and peer stories | Advanced guides, ROI expansions, customer stories, roadmap transparency | Expansion revenue, multi‑product attach, review volume/quality |
Two implications stand out. First, citability is earned by clarity, structure, and provenance—clean Q&A sections, author attribution, dates, and explicit methods. Second, engines differ in how they cite: Perplexity shows numbered references, and OpenAI documents inline citations for ChatGPT Search; see Perplexity’s help center on how it works and OpenAI’s guide to ChatGPT Search citations.
Build your query taxonomy and prompt library
Without a disciplined prompt set, you’ll map anecdotes instead of journeys. Start with a compact, high‑stakes taxonomy per ICP and region. Focus on problem and job‑to‑be‑done prompts (for example, “reduce churn in B2B SaaS” or “best onboarding tool for PLG teams”), category and competitor prompts (“top [category] platforms,” “Tool A vs Tool B for SOC 2”), and integration, compliance, and pricing/ROI prompts (“[product] + Salesforce,” “SOC 2 automation cost,” “pricing calculator for [category]”).
Governance matters. Version prompts by engine and locale, record run context (engine/mode, date/time, location), and log outcomes: mentions/recommendations, citation sources, sentiment, and positions. Use JSON‑LD (Organization, SoftwareApplication, WebSite/WebPage) and structured Q&A to improve clarity for crawlers and answer engines; see schema.org’s example corpus and Google’s SEO starter guide for fundamentals.
How often should you run it? Weekly sampling for volatile queries, monthly for stable categories, and pre/post major content releases. Keep a change log so you can attribute shifts to either engine updates or your own actions.
Measure what matters: a dual‑lens dashboard
Here’s the deal: measuring AI influence without tying it to the funnel invites vanity metrics. Build a dual‑lens view that pairs AI visibility with web and revenue outcomes.
AI visibility metrics (by engine and locale): mentions/recommendations, citation domains and positions, link presence, and observed sentiment. Track variance by engine—ChatGPT may drive fewer but higher‑intent clicks; Perplexity often aggregates deeper sources; Google AI Overviews evolve in appearance and link formats.
Web and revenue outcomes: pricing‑page landings, demo requests, trial signups, assisted conversions, CRM stage progression, and win–loss interview notes that explicitly reference AI answers or citations. In GA4, watch for referrers like perplexity.ai and chat.openai.com/chatgpt.com. Expect some traffic to bucket as “Direct” when clicks pass through intermediary UI; use ranges and narrative context rather than point claims. Maintain IVT hygiene and document filters.
Disclosure: Geneo (Agency) is our product. Used neutrally as an example, a cross‑engine tracker can help agencies and SaaS teams log daily citations and recommendations across ChatGPT, Perplexity, and Google AI Overviews, and present metrics such as Share of Voice and AI Mentions in client‑ready dashboards. For a deeper look at prompt‑level monitoring and white‑label reporting in practice, see the internal review “Geneo Review 2025: AI search visibility tracking”. For analytics setup and reporting ranges, consult “AI Traffic Tracking Best Practices (2025)”.
Reporting cadence should balance drift detection and executive digestibility: weekly checks for movement and anomalies; monthly narrative summaries with hypotheses and next actions; quarterly prompt set and taxonomy revisions. Keep cross‑engine comparisons side‑by‑side to avoid optimizing for a single surface.
Workflow Example A: Cross‑engine mapping loop
- Define 50–100 priority prompts per ICP and region (problem, category, competitor, integration, pricing/ROI). Document intent and business stakes.
- Run the prompt bank in ChatGPT, Perplexity, and Google (signed‑out profiles, clean locales). Capture mentions, citations, recommendation phrasing, and destination links.
- Analyze gaps. Are implementation guides missing? Is pricing ambiguous? Are security pages thin? Compare how each engine cites.
- Refactor assets with provenance: add methods to case studies, clarify pricing assumptions, enrich integration docs, add FAQPage/HowTo schema, and ensure authorship and dates.
- Re‑run the bank on a fixed cadence. Log deltas in mentions and citations; correlate with pricing‑page landings and demo/trial changes in GA4/CRM.
- Decide next tests. If Perplexity consistently misses your implementation guide, add a standalone deployment page with stepwise headings and internal links from relevant hubs.
Workflow Example B: From visibility to revenue signals
- Instrument referrers and campaign parameters where possible; maintain a lookup for AI surfaces (Perplexity, ChatGPT Search, Gemini). When attribution is ambiguous, use modeled ranges rather than absolutes.
- Monitor spikes in AI mentions and recommendations. Did a pricing overhaul or a new security guide precede the change? Note the timestamp in your change log.
- Correlate with funnel metrics: pricing visits, demo form starts, trial signups, and CRM stage progression. If signals lift, flag a hypothesis—not a conclusion—and validate via win–loss interviews.
- In interviews, ask buyers whether they used AI answers during shortlisting and which pages or sources influenced confidence. Triangulate responses with your citation logs.
- Present executives with a dual‑pane view: a trend of AI citations by engine next to MQLs/PQLs and opportunities created, annotated with content releases and engine updates. Keep confidence intervals visible.
Governance and risk
Shortcuts backfire. Verify claims in your assets with primary sources and transparent methods. Maintain author bios and update dates to align with E‑E‑A‑T. Follow Google’s policies on helpful content and spam, especially given the March 2024 core update and spam policies. Keep a single prompt governance document with version history, sampling cadence, locale rules, and IVT filters for auditability.
Don’t overfit to one engine. Per MarTech’s commentary and Previsible’s findings, behaviors differ by surface. Design tests that improve citability broadly, not just for one UI pattern.
Multi‑stakeholder and ABM nuances
B2B decisions rarely rest with one person. Highspot (citing Forrester) highlights stall rates tied to misaligned buying groups, and Wynter’s 2024 research finds many SaaS leaders shortlist around three vendors before demos—see Highspot’s buying journey summary and Wynter’s findings on how B2B SaaS leaders buy. Map validators to stages: security and compliance sign‑off near Decision, finance near ROI modeling, and admins during Adoption. Create assets AI can cite that answer each validator’s concerns—security whitepapers with scope and controls, procurement checklists, and role‑specific how‑tos.
Think of it this way: if an ABM account’s champion asks ChatGPT for “top vendors with SOC 2 attestation and Salesforce integration under 60‑day deployment,” will your pages trigger a confident mention? If not, you know what to fix.
Next steps
- Finalize a 50–100 prompt set per ICP and region; implement governance and a change log.
- Stand up a dual‑lens dashboard pairing AI visibility with GA4/CRM outcomes; normalize referrers for Perplexity and ChatGPT Search.
- Refactor priority assets for citability: methods on case studies, transparent pricing assumptions, security/compliance depth, structured Q&A blocks.
- Pilot the cross‑engine mapping loop for one segment; evaluate shifts in mentions and correlated funnel metrics within 30–60 days.
- For executive storytelling and AEO/GEO operations, see “AEO Best Practices 2025: Executive Guide” and the one‑page dashboard approach in this executive GEO guide.
The buyer journey didn’t disappear; it got denser. Map it with discipline, measure it with humility, and keep your most citable evidence front and center.